《数据区》专题
-
Appengine Search API与数据存储区
问题内容: 我正在尝试决定是否应针对App引擎关联的Android项目使用App引擎搜索API或数据存储区。Google文档的唯一区别是 …索引搜索最多只能找到10,000个匹配的文档。App Engine数据存储区可能更适合需要检索非常大的结果集的应用程序。 鉴于我已经非常熟悉数据存储区:假设我不需要10,000个结果,有人可以帮我吗? 是否有任何优势,利用与使用数据存储为我的查询(根据上面的报
-
数据是否跨分区分割?
我读过Kafka文档,但当有人谈论数据和分区时,我仍然感到困惑。在文档中,我看到客户机将向分区发送消息。然后将消息分区复制到副本(跨代理)。和使用者从分区读取数据。 我有一个有两个分区的主题。假设我有一个生产者,它向分区#1发送消息。但我有两个消费者,一个从分区1读取,另一个从分区2读取。这是否意味着我的分区1将有50%的消息,分区2将有50%的消息。或者,当客户端将数据发送到分区#1时,分区#1
-
Cassandra中的数据重新分区
作为卡桑德拉数据分区的后续,我得到了vNodes的想法。感谢“西蒙·丰塔纳·奥斯卡森” 当我尝试使用vNodes进行数据分区时,我有几个问题, 我尝试观察2节点中的分区分布() 因此,根据我在两个节点中的观察,随着一个范围的扩展,节点61的值从-9207297847862311651到-9185516104965672922。。。 注意:分区范围从9039572936575206977到90199
-
火花数据帧范围分区
[新加入Spark]语言-Scala 根据文档,RangePartitioner对元素进行排序并将其划分为块,然后将块分发到不同的机器。下面的例子说明了它是如何工作的。 假设我们有一个数据框,有两列,一列(比如“a”)的连续值从1到1000。还有另一个数据帧具有相同的模式,但对应的列只有4个值30、250、500、900。(可以是任意值,从1到1000中随机选择) 如果我使用RangePartit
-
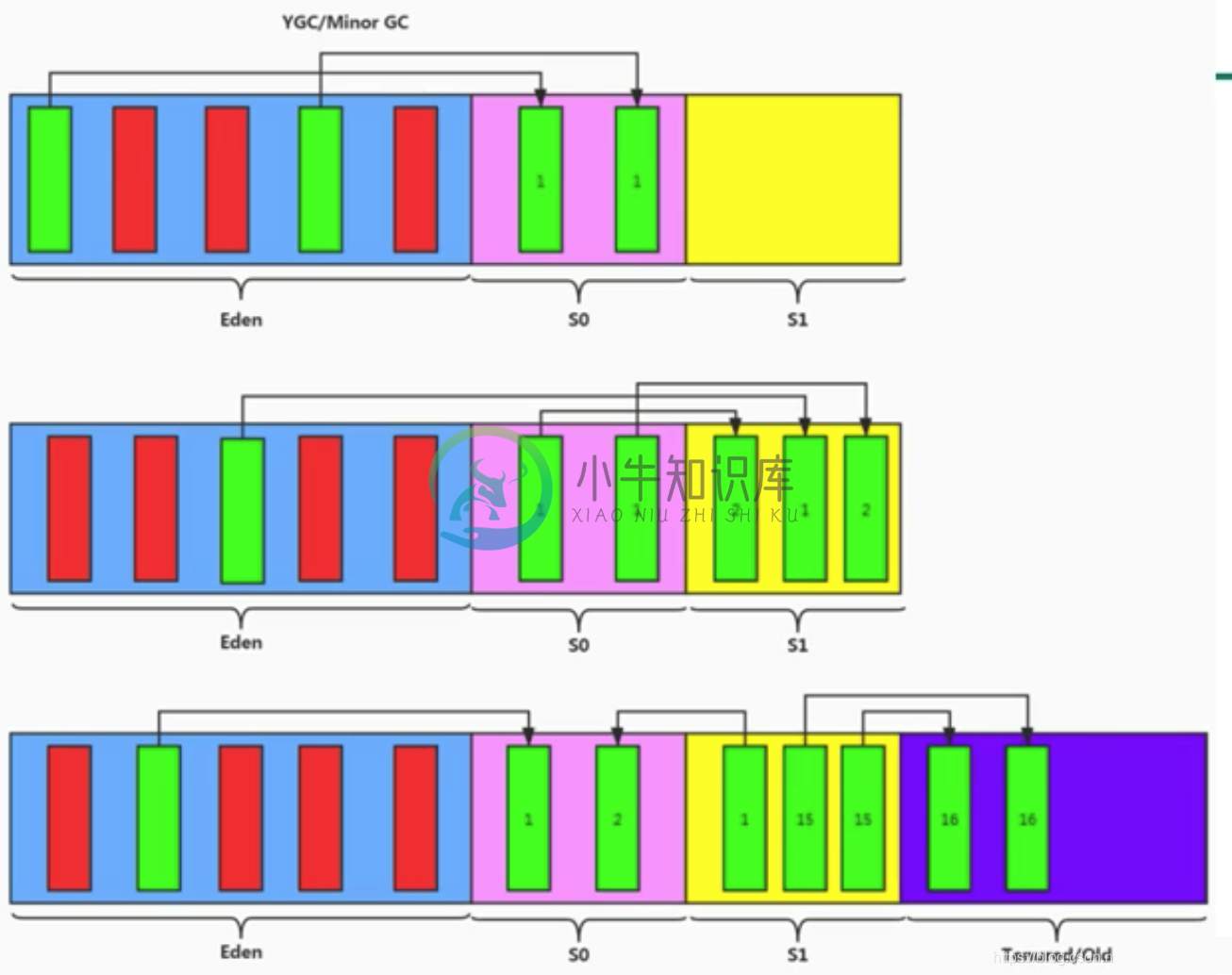 JVM 运行时数据区-堆-2
JVM 运行时数据区-堆-2主要内容:1.图解对象分配过程,2.Minor GC、Major GC、Full GC,3.TLAB(线程私有缓存区域)1.图解对象分配过程 特殊情况 2.Minor GC、Major GC、Full GC 部分收集:不是完整收集整个Java堆的垃圾收集。其中又分为: 新生代收集(Minor GC/Young GC):只是新生代的垃圾收集 老年代收集(Major GC/Old GC):只是老年代的垃圾收集 混合收集(Mixed GC):收集整个新生代以及部分老年代的垃圾收集 整堆收集(Full
-
 JVM 运行时数据区-堆-1
JVM 运行时数据区-堆-1主要内容:1.堆的细分内存结构,2.设置堆内存大小与OOM,3.年轻代与老年代1.堆的细分内存结构 JDK 7以前: 新生区+养老区+永久区 Young Generation Space:又被分为Eden区和Survior区Young/New Tenure generation Space:Old/Tenure Permanent Space:Perm JDK 8以后: 新生区+养老区+元空间 Young Generation Space:又被分为Eden区和Survior
-
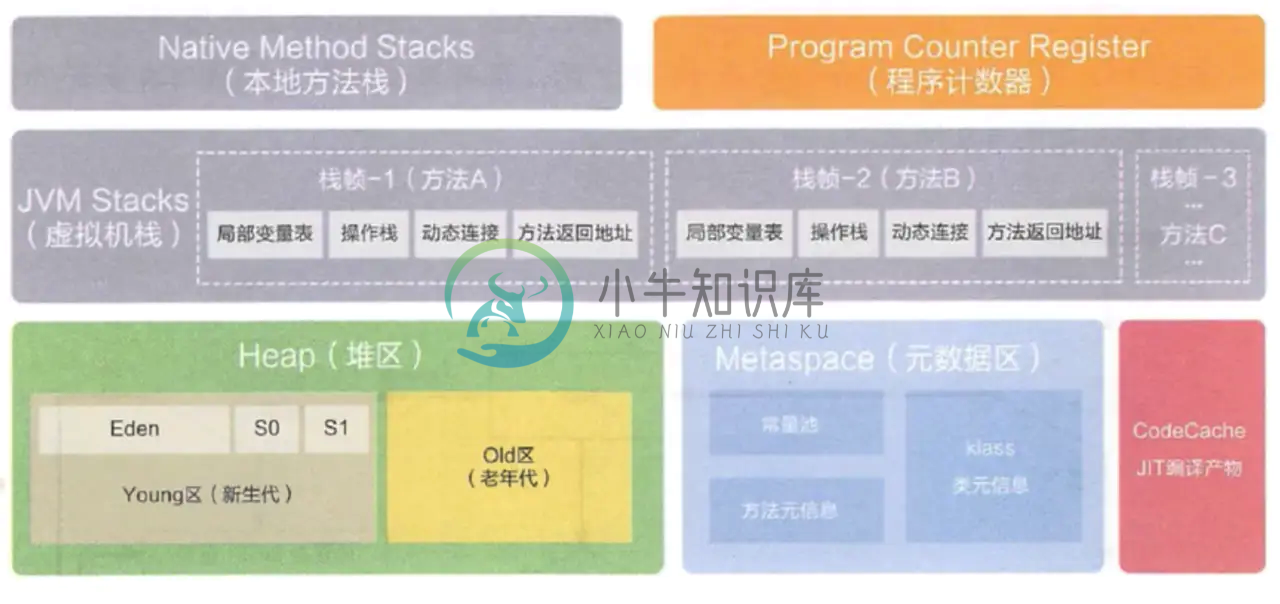 JVM 运行时数据区1-pc
JVM 运行时数据区1-pc主要内容:01 内存,02 分区介绍,03 线程,2.1 JVM系统线程,1.程序计数器(PC寄存器)01 内存 内存是非常重要的系统资源,是硬盘和cpu的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM内存布局规定了JAVA在运行过程中内存申请、分配、管理的策略,保证了JVM的高效稳定运行。不同的jvm对于内存的划分方式和管理机制存在着部分差异(对于Hotspot主要指方法区) (图源阿里)JDK8的元数据区+JIT编译产物 就是JDK8以前的方法区 02 分区介绍 java虚拟机定
-
从Firebase数据库检索数据并存储在数组列表中
问题内容: 我正在尝试以android应用程序的形式创建一个小型课程聚合程序。 我的课程全部存储在Firebase实时数据库中,该数据库可从firebase控制台查看,并且一切正常。 问题是我已经编写了一个Java方法来连接到DB,从DB检索数据,将数据转换为Custom Java对象,将其附加到另一个Custom Java对象,然后将该对象保存到ArrayList中。 与数据库的连接已成功建立,
-
如何用另一个数据帧中的数据填充一个数据帧,同时保留第一个数据帧中的NAs
我有两个数据帧,它们的列名相同,但行数不同。第一个数据帧(a)看起来与此类似: 注:站点5、6、8和12故意丢失。 第二个数据帧(b)看起来像这样: 我想要实现的是: 在那里我注入(我肯定有一个更好的术语)数据帧b到数据帧a的数据,但是我想用零替换b中的任何NAs,并保持a中的NAs不变。 我发现并尝试了这个代码: 但它会带来NAs。我考虑先将NAs替换为零,但即使如此,它也会抹去我目前在数据帧a
-
基于文档的数据库与基于键/值的数据库之间的区别?
问题内容: 我知道有三种不同的,流行的非SQL数据库类型。 键/值:Redis,Tokyo Cabinet,Memcached ColumnFamily:Cassandra,HBase 文件:MongoDB,CouchDB 我已经读了很长的博客,但对它的了解却很少。 我知道关系数据库,并且在MongoDB / CouchDB等基于文档的数据库中徘徊。 谁能告诉我这些和清单上的两个前者之间的主要区别
-
将数据从一个数据库复制到另一个数据库时,如何解决org.hibernate.StaleObjectStateException?
问题内容: 我正在尝试将数据从一个数据库复制到另一个数据库。一切工作正常,直到修改了源数据库中的一行之一(下面的堆栈跟踪)。按预期将新行添加到目标数据库。 对于每个数据库连接(mysql和hsqldb),我都有一个由以下bean组成的上下文文件: 在我为每个数据库连接中创建一个: 很简单: 我正在使用Spring Integration将2种服务方法连接在一起。服务方法如下: 我尝试过从s 分离列
-
基于来自另一个数据帧的值将数据帧拆分为多个数据帧
我有两个数据帧df1和df2。df1就像一个具有以下值的字典 df2具有以下值: 我想基于df1数据帧中的,将df2拆分为3个新的数据帧。 日期,TLRA_权益栏应位于数据框 预期产出: > 数据帧 消费者,非周期性数据帧 请让我知道如何有效地做。我想做的是连接列名,例如,然后根据列名的前半部分分割数据帧。 代码: 但这很复杂。需要更好的解决方案。
-
Listview显示排序后的数据,而不是数据在数据库中的存储方式
我正在根据下面显示的代码从数据库填充ListView,代码片段实现了CursorLoader。早些时候,出于同样的目的,我使用SimpleCrsorAdapter,但出于某些原因,我不得不改为ArrayAdapter。 数据库只有两列: _id(整数主键自动增量)和消息(字符串非空) ListView工作正常,但问题是listview中显示的字符串会自动按字母顺序排序,而不是按存储顺序排序。而我在
-
python - 使用django的modelForm出现数据只创建数据不更新数据(form.save)怎么办?
使用django的modelForm出现数据只创建数据不更新数据(form.save) models.py,数据库有多个字段 views.py 前端修改数据的页面edit_user.html 问题是通过编辑user_list的用户数据,每次修改只会创建新的数据,并不会通过id值更新数据,已经传入instance参数,save()都不行,通过 会报错Cannot force an update in
-
通过Gradle传递数据库凭据
我正在使用gradle credentials插件将用户和密码数据库传递给liquibase插件。另外,我使用spring data repositories和hibernate作为数据层,我希望传递给它与liquibase插件相同的配置。有一种通过gradle传递凭据的方法(我不想创建application.properties文件,因为凭据已经存储在凭据插件上)? 我正在使用以下代码向Liqu