《数据区》专题
-
培训数据和测试数据(Training Data and Test Data)
培训数据和测试数据是机器学习中的两个重要概念。 本章将详细讨论它们。 培训数据 训练集中的观察结果形成了算法用于学习的经验。 在监督学习问题中,每个观察包括观察到的输出变量和一个或多个观察到的输入变量。 测试数据 测试集是一组观察结果,用于使用某些性能指标评估模型的性能。 重要的是,测试集中不包括来自训练集的观察结果。 如果测试集确实包含来自训练集的示例,则难以评估算法是否已经学会从训练集中推广或
-
2. 数据 - 2.2 导入csv或txt格式的数据
1. 数据准备 请提前准备好需要导入的数据,数据格式参考下图1: 图 1 数据格式 2.数据导入过程 2.1添加数据 打开OpenQuant2014,点击Data->Import->CSV or Text Files 进入到数据导入界面,如图2:
-
Serverless 数据分析,Kinesis Firehose 持久化数据到 S3
based on:serverless-kinesis-streams, but auto create Kinesis streams 在尝试了使用 Kinesis Stream 处理数据之后,我发现它并不能做什么。接着,便开始找寻其它方式,其中一个就是:Amazon Kinesis Firehose Amazon Kinesis Firehose 是将流数据加载到 AWS 的最简单方式。它可以
-
 数据开发 - 面经 - 来未来(医疗大数据)
数据开发 - 面经 - 来未来(医疗大数据)2024.1.9 面试 Boss直聘沟通 公司要求驻场开发,接受加班,接受出差 你是25届是吧?能在六个月左右是吗?目前在校吗? 后续有什么规划? 你怎么理解数据开发这个岗位的? 讲讲简历上这两个项目?是你在学校做的是吧? 项目你是全程参与是吧? 聊天这个项目的数据源是哪里来的呀? 项目整体是落在HDFS上是吧? 单一架构,嗷,然后可视化,是哇? 下一个电商项目介绍一下? 数据来源讲讲? 那意思是
-
mysql 如何迁移数据流较大的数据库?
数据库日积月累几个G后,从服务器A导入到服务器B 导入数据库总是失败。内存不足或者直接崩了。 请问有什么方案可以稳定的分段导入吗?
-
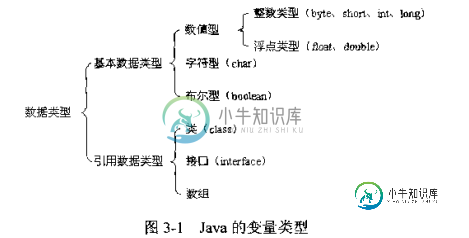 Java中int与integer的区别(基本数据类型与引用数据类型)
Java中int与integer的区别(基本数据类型与引用数据类型)本文向大家介绍Java中int与integer的区别(基本数据类型与引用数据类型),包括了Java中int与integer的区别(基本数据类型与引用数据类型)的使用技巧和注意事项,需要的朋友参考一下 一、先说说int与integer的区别 int 是基本数据类型,默认值为0,不需要进行实例化 integer 是引用数据类型,是int的封装类型,默认值为null,创建该类型需要进行实例化。
-
获取一个数据frame的当前分区数
是否有任何方法可以获得一个DataFrame的当前分区数?我检查了DataFrame javadoc(spark 1.6)但没有找到一个方法,或者我只是错过了它?(对于JavaRDD,有一个getNumPartitions()方法。)
-
转换后保留Spark数据帧的分区数
我正在查看代码中的一个错误,其中一个数据框被分成了太多的分区(超过700个),当我试图将它们重新分区为48个时,这会导致太多的洗牌操作。我不能在这里使用coalesce(),因为我想在重新分区之前首先拥有更少的分区。 我正在寻找减少分区数量的方法。假设我有一个 spark 数据帧(具有多个列),分为 10 个分区。我需要根据其中一列进行 orderBy 转换。完成此操作后,生成的数据帧是否具有相同
-
将列数据的多维数组重组为行数据的多维数组
问题内容: 我具有以下列数据的关联数组: 我需要将结构转置/旋转为行数组(将合并的列数据分配给它们各自的行)。我不需要结果中的列名。 预期产量: 问题答案: 正如Kris Roofe在删除的答案中所说,的确是一种更为优雅的方法。只要确保将其放入某种循环中即可,就像Sahil Gulati向您展示的那样。例如,像这样: 的输出正是您要寻找的
-
MySQL之终端Terminal(dos界面)管理数据库、数据表、数据的基本操作
本文向大家介绍MySQL之终端Terminal(dos界面)管理数据库、数据表、数据的基本操作,包括了MySQL之终端Terminal(dos界面)管理数据库、数据表、数据的基本操作的使用技巧和注意事项,需要的朋友参考一下 MySQL有很多的可视化管理工具,比如“mysql-workbench”和“sequel-pro-”。 现在我写MySQL的终端命令操作的文章,是想强化一下自己对于MySQL的
-
 在codeigniter中显示动态类别中的数据和数据库中的动态数据
在codeigniter中显示动态类别中的数据和数据库中的动态数据我有三类,像故事,电影故事,照片 我想显示数据类别明智的数据从数据库 1.故事*data1*data2*data3 2.电影故事*data1*data2*data3 控制器: 型号: 查看: 数据库: 创建表home_page: 创建表(int(11)not NULLAUTO_INCREMENT,int(11)DEFAULT NULL,int(11)DEFAULT NULL,text,
-
 很全面的Mysql数据库、数据库表、数据基础操作笔记(含代码)
很全面的Mysql数据库、数据库表、数据基础操作笔记(含代码)本文向大家介绍很全面的Mysql数据库、数据库表、数据基础操作笔记(含代码),包括了很全面的Mysql数据库、数据库表、数据基础操作笔记(含代码)的使用技巧和注意事项,需要的朋友参考一下 Mysql数据库、数据库表、数据基础操作笔记分享给大家,供大家参考,具体内容如下 一、数据库操作 1.创建数据库 Create database db name[数据库选项]; tip:语句要求使用语句结束符"
-
不支持DML操作。无法使用spring数据更新postgresql数据库中的数据
嗨,我使用的是Spring启动和Spring数据,我想从数据库中获取数据的基础上的id,但我不能检索它。我得到这个错误"异常": "org.springframework.dao.InvalidDataAccessApiUsageExctive","消息":"org.hibernate.hql.internal.QueryExcutionRequest estExctive:不支持DML操作[Up
-
将数据帧合并到一个数据帧中,并将空数据帧保留为NA
这是我的密码: 我想知道如何将df3绑定到单个数据帧中作为"NA"s? 我在r_blogger上找到了一篇关于将向量或长度不等的数据帧组合成一个数据帧的文章。http://www.r-bloggers.com/r-combining-vectors-or-data-frames-of-unequal-length-into-one-data-frame/ 但是我从数据中得到的数据框,其中一些是空的
-
根据分区列从数据库增量表中删除
我有一个具有5个分区的delta表,其中一个分区是runid列。当我尝试使用runid删除时,使用真空命令后,底层拼花文件会被删除。但这不会删除runid分区。如果我运行相同的真空命令4次,那么它会删除runid分区。 对于配置单元,我们有删除分区,但这不适用于增量表! 这就是删除在增量表中的工作方式吗?或者有没有更好的方法从托管增量表中删除runid的数据和分区?