《GC》专题
-
多处理器机器上的Java堆和GC?
Java如何处理多处理器机器上的GC和堆分配? 在我所做的阅读中,单处理器和多处理器系统之间使用的算法似乎没有任何区别。艺术 作为一个数据点。Net时,算法发生了显著的变化:每个处理器都有一个与之密切相关的堆,每个处理器都负责该堆。这在很多地方都有记录,比如MSDN: 在运行服务器版本的执行引擎(MSCorSvr.dll)的多处理器系统上,托管堆被分成几个部分,每个CPU一个。当收集启动时,收集器
-
Clang vs GCC vs MSVC模板转换运算符-哪个编译器是正确的?
我有带转换操作符的简单代码,似乎所有的编译器都给出不同的结果,我很好奇哪个编译器是正确的?我也尝试了不同的组合,但以下是最有趣的。代码是使用C 11标志编译的,但是在C 03中也可能观察到相同的行为。 叮当声-3.6: g -4.9: msvc 2014年CTP: 删除后: msvc编译: 此外,在移除const in后 叮当声-3.6: g -4.9: msvc 2014年CTP:
-
GCM超时&发送5000个推送通知后拒绝连接
我需要发送500推送通知每秒通过gcm服务。不幸的是,与chrome49不同,我必须为每个chrome50客户加密消息,加密密钥显示在请求头中。发送超过5000条消息后,我从https://android.googleapis.com/gcm/send收到超时和拒绝连接,并停止工作一段时间,然后定期正常工作 在线程中运行的Post请求 异常:连接被拒绝 异常:与https://android.go
-
允许用户使用BlobstoreService上传并保存文件到我的GCS Bucket,如何识别上传的文件?
请帮忙。我正在尝试使用BlobstoreService将视频文件(.mp4)上传到GCS bucket。 文件成功上传并自动保存在我的GCS桶中,客户端收到的关键upload_result值是。 问题是,我不知道如何识别上传的文件保存在我的桶中的Blosstore Service和如何获得其他信息例如请求中的foo和bar键值。 文档中说我可以使用BlobInfo#getGsObjectName(
-
Neo4j GC开销限制
我建立了一个neo4j图。大小约为5 GB。当我想通过使用类似这样的密码查询向每个节点添加一个关系时,我会得到错误。我不想为Neo4J增加内存。有什么方法可以一步一步地更新节点吗?比如,先有5000个节点,然后再有5000个节点...或者你对此有什么其他建议?
-
 JMeter JP@GC-WebDriver采样器-图形生成器
JMeter JP@GC-WebDriver采样器-图形生成器嗨,我现在使用JMeter Groovy WebDriver。我的问题是,导入了图形生成器,但没有任何图形输出。你能建议图形生成器应该与WebDriver一起工作吗?还是只为JMeter采样器Http请求工作?
-
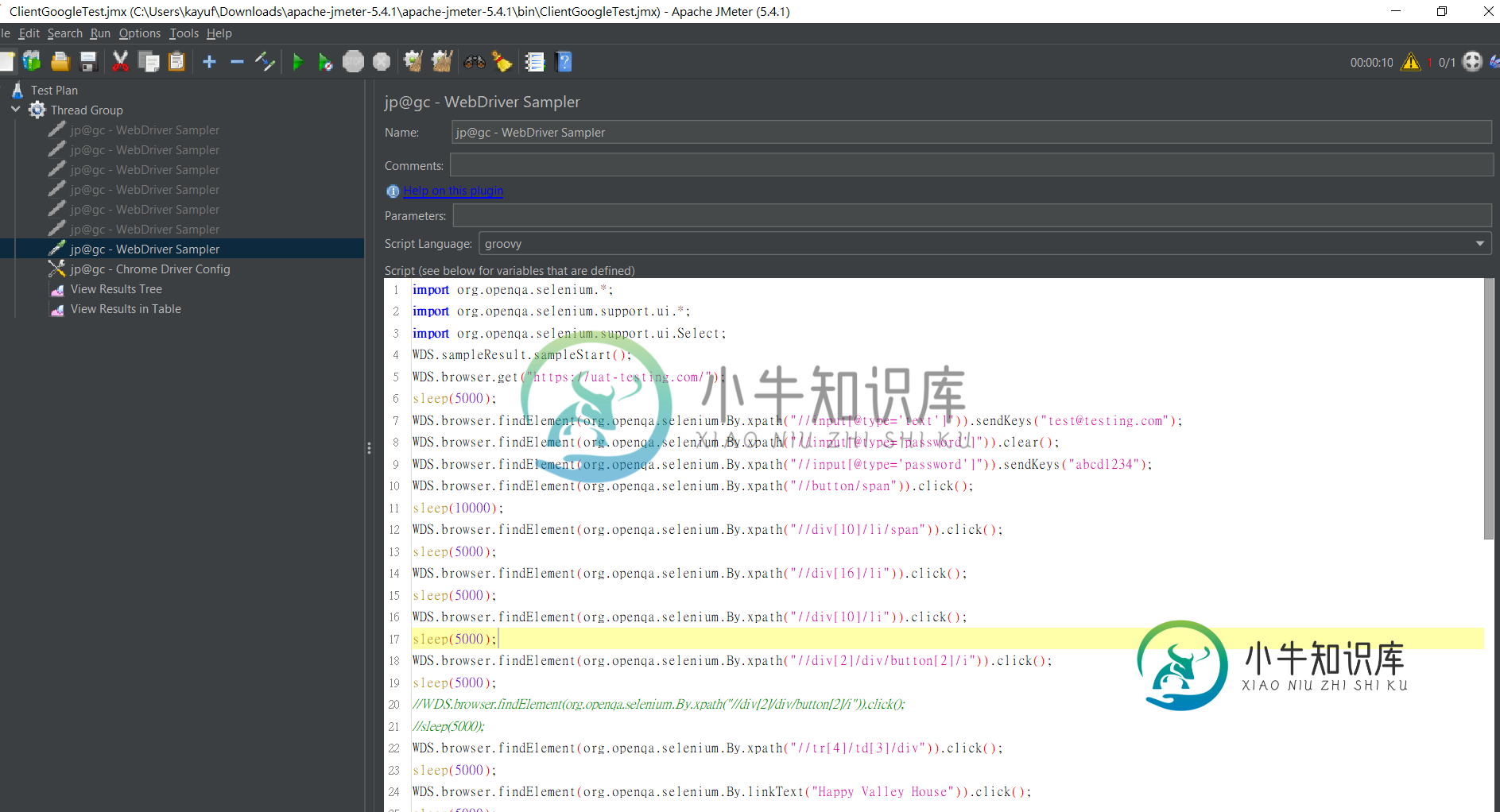 JMeter jp@gc-WebDriver采样器--执行包
JMeter jp@gc-WebDriver采样器--执行包 -
基类中模板化构造函数的叮当/gcc 和 MSVC 之间的不同结果
我偶然发现了以下代码。案例在MSVC上产生的结果与在叮当声或gcc上产生的结果不同。也就是说,叮当声 13 和 gcc 11.2 调用 的复制构造函数,而 MSVC v19.29 调用模板化构造函数。我使用的是C 17。 考虑到所有编译器都同意调用模板化构造函数的非派生情况(我认为这是clang和gcc中的一个错误,MSVC是正确的吗?还是我解释错了,叮当/gcc是正确的?任何人都可以对可能发生的
-
GCP数据流+Apache波束缓存问题
我对GCP、Dataflow、Apache Beam、Python和一般的OOP都是新手。我来自函数式javascript领域,对于上下文。 现在,我已经用Apache Beam python sdk构建了一个流管道,并将其部署到GCP的数据流中。管道的源是pubsub订阅,接收器是数据存储。 管道从pubsub订阅中获取消息,根据配置对象+消息内容做出决定,然后根据做出的决定将其放在数据存储中的
-
如何使用maven jvmarg解决“超过GC开销限制”?
线程“main”java.lang.OutOfMemoryError中出现异常:超过GC开销限制 我试图从类包的maven pom.xml内部增加jvmArg堆大小: http://maven.apache.org/xsd/maven-4.0.0.xsd“>4.0.0 null
-
如何为运行在Java 7中的Tomcat 7添加AES-GCM支持
我很清楚Java 7默认不支持基于GCM的密码。因此,我试图通过Bouncy Castle完成这项工作。 我在Tomcat的HTTPS连接器中配置了以下密码: 密码=“我们的研究结果是,他们的研究结果是一个有128个字符的CBC共有256个,他们的研究结果是一个有128个字符的RSA的研究结果是一个有128个字符的CBC共有256个,他们的研究结果是一个有128个字符的CBC共有128个字符的CB
-
GCP数据流批处理作业-防止工人在批处理作业中一次运行多个元素
我正在尝试在GCP数据流中运行批处理作业。工作本身有时会占用大量内存。目前,工作一直在崩溃,因为我相信每个工作人员都在试图同时运行pcollection的多个元素。有没有办法防止每个工人一次运行多个元素?
-
优化内存密集型数据流管道的GCP成本
我们希望提高在GCP数据流中运行特定Apache Beam管道(Python SDK)的成本。 我们已经构建了一个内存密集型Apache Beam管道,这需要在每个执行器上运行大约8.5 GB的内存。一个大型机器学习模型目前加载在转换方法中,因此我们可以为数百万用户预先计算建议。 现有的GCP计算引擎机器类型的内存/vCPU比率低于我们的要求(每个vCPU高达8GB RAM)或更高的比例(每个vC
-
预计ETA将在使用python的apache beam GCP数据流管道中使用管道I/O和运行时参数?
只是想知道新版本(3.X)的python是否提供了更多的管道I/O和运行时参数。如果我是正确的,那么当前ApacheBeam只提供基于文件的IOs:使用python时提供textio、avroio、tfrecordio。但在Java中,我们有更多的选项,如基于文件的IOs、BigQueryIO、BigtableIO、PubSubIO和SpanRio。 在我的需求中,我想使用Python 3在GCP
-
如何获得有效的令牌,以便在安装了SDK的本地计算机上使用GCP数据丢失防止API?
所以我尝试使用来使用SSL代理背后的API 在我的本地机器(Windows或Mac)上给我一段时间相同的令牌,每次我执行该命令时,我都会得到一个新的令牌。在我的本地机器上,如果我用中的令牌替换gcloud命令的头,那么它可以正常工作。我的本地计算机和上都有最新版本的。 问题1:预计每次我们在本地运行()时,都会得到一个新的令牌?(在上,在几分钟内,它是相同的标记)