《同步调用》专题
-
从返回CompletableFuture的异步方法的同步部分抛出异常
这个问题是针对Java和< code>CompletableFuture的。 如果我有一个像下面这样的异步方法, 如果步骤#1中的代码抛出,的调用者将在获得它返回的之前获得异常,而如果步骤#2中返回的中的代码抛出,调用者将仅在与返回的交互时获得异常。 这表明的调用方应该编写一些复杂的异常处理代码来处理这两种情况。 下面是另一个异步方法的示例,,该方法调用并返回它返回的字符串长度: 我的问题是: <
-
RabbitMQ和pika:同一通道上不同队列的不同回调?
我很难理解RabbitMQ的基本概念。我发现在线文档并不十分清楚。 到目前为止,我理解了什么是通道、队列、绑定等。 但如何实现以下用例: 用例:发件人以不同的主题发布到一个交易所。在接收者方面,根据主题,应该通知不同的接收者。 因此,通过主题交换,以下内容应该是可行的: 创建频道 我的困难在于回调与通道相关,而与队列或队列绑定无关。我不能百分之百确定我是否在这里。 这就是我的问题:为了有多个回调,
-
如何等待异步回调函数集?
问题内容: 我的代码在javascript中看起来像这样: 在完成所有这些异步调用之后,我想计算所有数组的最小值。 我要如何等待所有人? 我现在唯一的想法是拥有一个名为done的布尔数组,并在第i个回调函数中将done [i]设置为true,然后说while(不是全部都完成了){} 编辑:我想一个可能但很丑陋的解决方案是在每个回调中编辑完了的数组,然后如果每个回调中都设置了所有其他完成,则调用一个
-
Node.js:异步回调执行。这是Zalgo吗?
问题内容: 使用 节点-6.0 执行以下操作 。 但是将上面的示例更改为使用process.nextTick()打印A,B,C 这就是我们所说的吗?谁能提供给我一个实时的例子,这将导致重大故障? 问题答案: 首先,让我解释一下代码的工作原理-请参阅添加的代码中的注释: 这与任何语言(如Java,C等)完全一样。 现在,第二个示例: 更新资料 感谢Bergi解释了Zalgo的答案是什么。现在,我更好
-
在Android的IntentService中等待异步回调
问题内容: 我有一个在另一个类中启动异步任务,然后应该等待结果。 问题是方法将在方法运行完成后立即完成,对吗? 这意味着,通常,在启动异步任务后,它将立即关闭,并且不再在那里接收结果。 如何使以上代码段正常工作?开始任务后,我已经尝试放入(任意持续时间)。似乎可以正常工作。 但这绝对不是一个干净的解决方案。也许甚至有一些严重的问题。 有更好的解决方案吗? 问题答案: 使用标准类代替,从回调启动异步
-
如何在Playground中运行异步回调
问题内容: 许多Cocoa和CocoaTouch方法都将完成回调实现为Objective- C中的块,而实现为Swift中的Closures。但是,在Playground中尝试这些操作时,永远不会调用完成操作。例如: 我可以在Playground时间轴中看到控制台输出,但是在我的完成块中从未调用过… 问题答案: true`。如果设置了此属性,则在您的顶级游乐场源完成时,我们将继续旋转主运行循环,而
-
通过回调异步加载JavaScript文件
问题内容: 我正在尝试编写一个超简单的解决方案以异步加载一堆JS文件。到目前为止,我下面有以下脚本。但是,当未实际加载脚本时,有时会调用回调,这会导致未找到变量错误。如果我刷新页面有时会起作用,因为我猜这些文件是直接从缓存中提取的,因此比调用回调要快,这很奇怪吗? 无论如何,有没有方法可以测试JS文件是否已完全加载,而无需在实际的JS文件本身中放入任何东西,因为我想使用相同的模式从我的控件(GMa
-
node.js中的for循环和异步回调?
问题内容: 我是JavaScript和node.js的新手。我想遍历目录并将所有文件统计信息(而不是其他目录)添加到数组中。如下所示,我的代码存在问题,因为回调可能在for循环完成后被调用,因此在回调方法中使用“ i”变量将不起作用。但是代码应如何显示,以便以下代码段起作用?它与闭包有关吗? 感谢帮助! 问题答案: 您需要使用闭包是正确的。您应该将循环的内容包装在一个自调用函数中,以保留每次迭代的
-
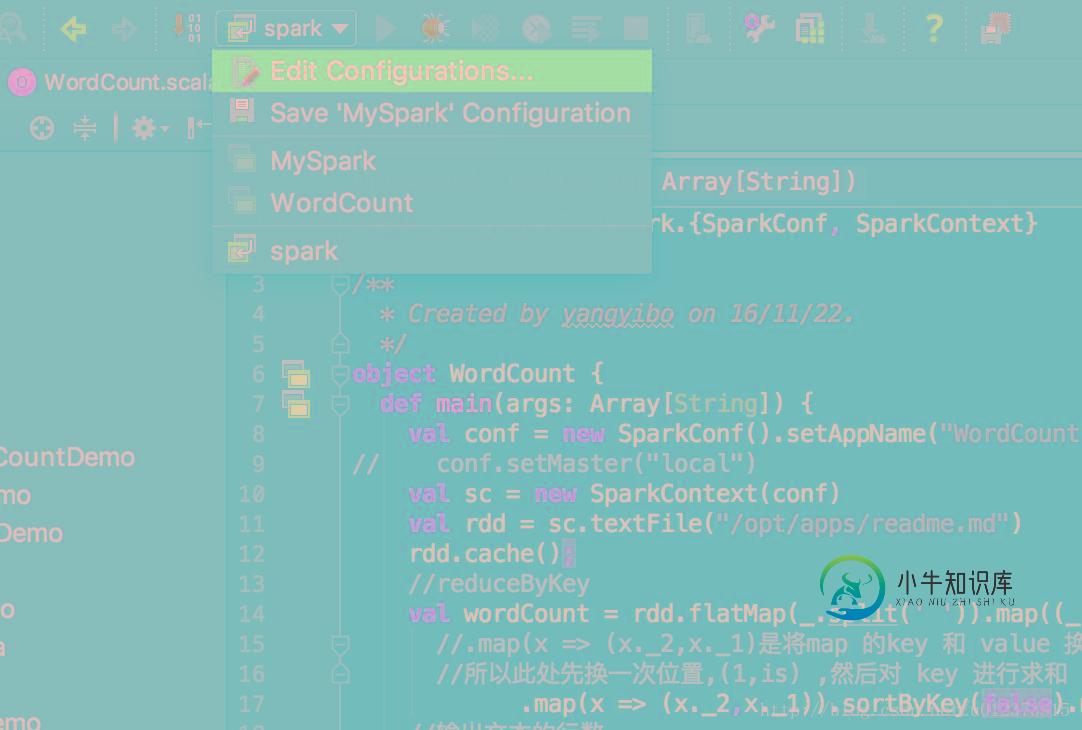 idea远程调试spark的步骤讲解
idea远程调试spark的步骤讲解本文向大家介绍idea远程调试spark的步骤讲解,包括了idea远程调试spark的步骤讲解的使用技巧和注意事项,需要的朋友参考一下 spark 远端调试 本地调试远端集群运行的spark项目,当spark项目在集群上报错,但是本地又查不出问题时,最好的方式就是调试一步一步跟踪代码。但是在集群上的代码又不能像本地一样的调试。那么就试试这个调试方法吧。 远程调试spark其实就四步: * 第一步j
-
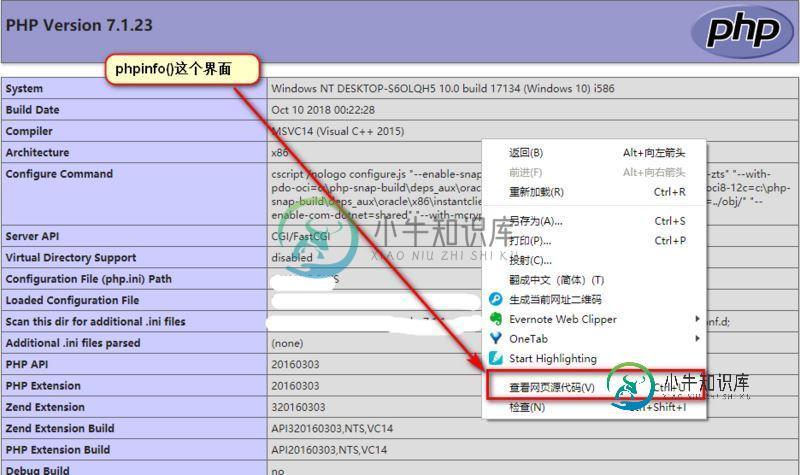 PhpStorm配置Xdebug调试的方法步骤
PhpStorm配置Xdebug调试的方法步骤本文向大家介绍PhpStorm配置Xdebug调试的方法步骤,包括了PhpStorm配置Xdebug调试的方法步骤的使用技巧和注意事项,需要的朋友参考一下 安装xdebug 去官网下载对应版本的xdebug扩展 XDEBUG EXTENSION FOR PHP | DOWNLOADS 如何选择正确版本输出phpinfo()函数的内容 查看输出页面的网页源码 全选复制 到这个页面XDEBUG EXT
-
玩框架2.1-调度异步任务(Java)
我刚刚更新了 Play!框架到版本 2.1 和 scala 到版本 2.10... 现在我的游戏!应用程序已损坏。似乎Akka API已经发生了变化。我找不到现在使用的阿卡版本,但我认为这是最后一个版本...... 我刚刚阅读了迁移指南:http://doc.akka.io/docs/akka/2.1.0/project/migration-guide-2.0.x-2.1.x.html。 我相应地
-
同步工具 - windows上有不需要共享文件夹,就能在局域网同步的软件?
Resilio Sync类似的软件都是被公司封掉的。 不想一直开局域网共享,只想同步的时候用。
-
调用同一模拟方法时,如何返回不同的结果?
我调用了一个方法,它连接到另一个服务器,每次调用它,它都返回不同的数据。 我正在为调用该方法的类编写一个单元测试。我已经嘲笑了那个类,我希望它返回存根结果。它实际上使用工作,但是它每次都返回相同的数据。我希望它返回不同的数据,我希望能够指定它应该是什么。 我试着使用“doReturn-when”,它可以工作,但我无法让它返回不同的结果。我不知道怎么做。 我还尝试使用“when-thenReturn
-
同步跨线程共享但不能同时访问的对象
问题内容: 假设我有一个与field共享的对象。多个线程将共享对该对象的引用以访问该字段。但是,线程永远不会同时访问对象。我需要声明为volatile吗? 这样的情况如下: 一个类定义一个唯一字段和一个方法。 一个线程使计数器递增,然后生成另一个使计数器递增的线程,依此类推。 鉴于程序的逻辑,因此无法并发访问计数器。但是,计数器是在多个线程之间共享的。计数器必须波动吗? 的情况的另一个变体是当多个
-
为什么同步方法允许多个线程同时运行?
问题内容: 我在同一文件中有以下程序。我已经同步了run()方法。 输出是 我的问题是,为什么同步方法同时允许“我的线程1”和“我的线程4”线程访问? 问题答案: 方法在实例级别工作。 类的每个实例都有自己的锁。每次输入实例的任何方法都将获取该锁。这样可以防止多个线程 在同一个实例上 调用方法(请注意,这还可以防止在同一个实例上调用 不同的 方法)。 现在,由于您有两个类实例,因此每个实例都有自己