《内存淘汰》专题
-
org.hibernate.hql.ast.QueryTranslatorImpl列表注意:用集合访存指定的firstResult / maxResults;申请内存
问题内容: 我遇到了一个问题,我在JPA中有一个查询。因为我有一些集合,所以我需要使用左连接获取或内部连接获取 我的问题是使用和,以便带回准确的结果数。每次我看到整个结果都带回来,并且只有在使用maxResult之后。 有什么办法可以使maxResult之前吗? 非常感谢 ! 这是更多信息: 我的问题是当我使用它时: 我在日志中看到此消息: 2011年6月7日09:52:37 org.hibern
-
x86_64寄存器RAX/EAX/AX/AL覆盖完整寄存器内容[重复]
所以,我有两个问题: > 我认为这种尴尬的行为必须在某个地方记录下来,但我似乎找不到详细的解释(关于64位寄存器的32位高值是如何被清除的)。对的写入总是擦除,还是更复杂?它是否适用于所有64位寄存器,或者有一些例外? 一个非常相关的问题提到了同样的行为,但是,唉,再次没有确切的文档参考。 只是我,还是这整件事看起来真的很奇怪和不合逻辑(即eax-ax-ah-al,rax-ax-ah-al有一种行
-
Android App将数据写入内部存储和外部存储的示例
本文向大家介绍Android App将数据写入内部存储和外部存储的示例,包括了Android App将数据写入内部存储和外部存储的示例的使用技巧和注意事项,需要的朋友参考一下 File存储(内部存储) 一旦程序在设备安装后,data/data/包名/ 即为内部存储空间,对外保密。 Context提供了2个方法来打开输入、输出流 FileInputStream openFileInput(Strin
-
每次部署网站时,如何让Google App Engine清除内存缓存?
问题内容: 标题问了一切。我正在构建的网站上的内容根本不会很快改变,因此Memcache可能会存储几个月的数据,但当我进行更新时除外。有没有一种方法可以在每次部署站点时清除缓存?我正在使用Python运行时。 更新1 使用 jldupont 的答案,将以下代码放入主请求处理脚本中… 更新2 我已切换到Koen Bok在所选答案的注释中提到的方法,并在答案的第二次更新中为我的所有内存缓存键添加了有用
-
如何修复上传文件到谷歌云存储的内存泄漏?
通过
-
如果响应NGINX中没有缓存控制头,如何缓存内容
我已经在一台主机上安装了一个带有NGINX的Ubuntu实例,并将其配置为另一台主机上我的应用程序的转发代理。我的应用程序正在向NGINX发出GET请求,NGINX正在向外部服务器发出另一个GET请求(请求中指定了指向此服务器的URL),并将响应返回给应用程序。NGINX应该缓存来自外部服务器的响应。我需要尊重响应中的缓存控制头(缓存该头所说的响应),但是!当响应中没有缓存控制头时,必须缓存12小
-
在mongodb collection上执行简单功能而不将其存储到内存?
我的mongo db集合中有1000个用户,我想在不将它们加载到内存的情况下对它们进行一些更新,更新是: 在每个用户对象中,我都有以下内容: 我想做以下简单的操作: 但是,像这样的更新,但不存储在内存中,甚至有可能做这样的检查吗?(可能是更复杂的事情?)
-
内存分布式缓存中的数据分区与数据持久化
null 假设我有100张唱片。缓存只能保存40条记录(最常用)和100条记录在磁盘文件(不在任何其他数据库中)。 所以,如果从这100条记录中请求任何东西,我就不必去实际的数据库(例如Sybase db)? 如果在100条记录中找到了密钥,但它不存在于内存缓存中(40条记录),则获取该密钥,放入内存缓存中,并使用驱逐策略将其他密钥交换到磁盘文件中(但在磁盘上,我总是有100条记录) 如果缓存和磁
-
Log4j2中是否使用java本机内存?我在本机内存而不是堆中发现了许多日志
我们有一个java应用程序,它是通过运行主功能启动的,我们还在springboot中启动嵌入式jetty作为webcontainer。我发现java head达到了最大大小,但堆使用率很低,java耗尽了被OS杀死的本机内存 pmap中有许多64MB内存。我转储了一些内存块,发现其中有许多日志。日志时间各不相同,即使几天过去了,日志似乎仍在内存中。对于exmaple 我们使用log4j2和slf4
-
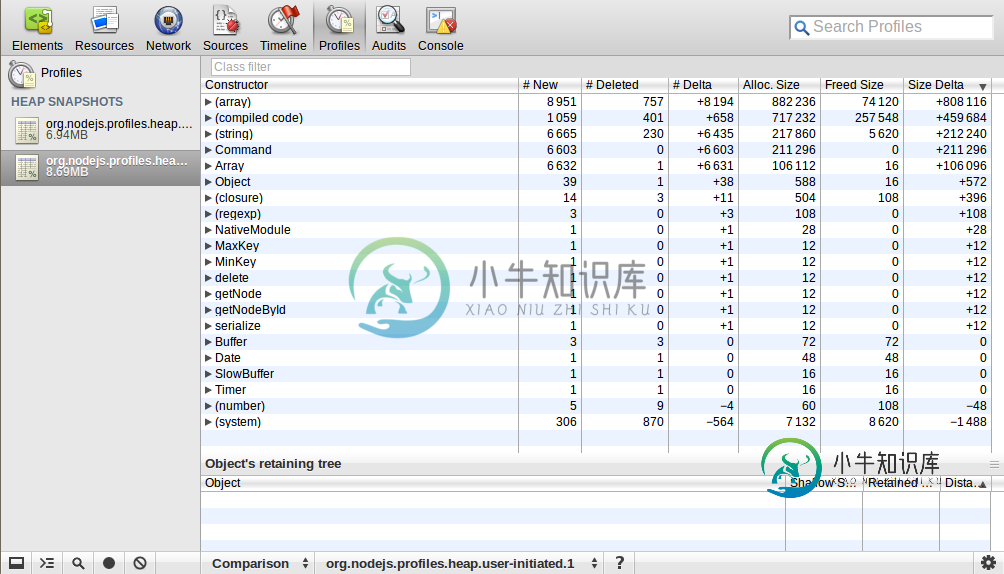 与Node.js的长连接,如何减少内存使用和防止内存泄漏?也与V8和webkit-devtools相关
与Node.js的长连接,如何减少内存使用和防止内存泄漏?也与V8和webkit-devtools相关下面是我正在尝试做的事情:我正在开发一个Node.js http服务器,它将在一台机器中保存来自数万个移动客户机的长连接,以实现推送目的(与redis协作)。 测试环境: 第一次,我使用了“Express”模块,在使用swap之前,我可以达到大约120K的并发连接,这意味着RAM不够。然后,我切换到本地“HTTP”模块,我得到了大约160K的并发。但是我意识到仍然有太多的功能我不需要在原生http
-
Web 应用程序中的静态变量是否会导致内存泄漏(以及透视的内存不足)?
静态变量以这样的方式进行垃圾收集: 静态变量由类对象引用,类对象由类加载器引用。所以,静态变量只是在加载了静态字段所在的类的类加载器在java中被垃圾收集时才被垃圾收集。 因此,假设一个web应用程序和Tomcat管理它。在一个特定的应用程序中存在静态变量,该应用程序被多次主动重新部署。 静态变量是否保留在元空间中,因为类加载器在重新部署时尚未进行GC处理?
-
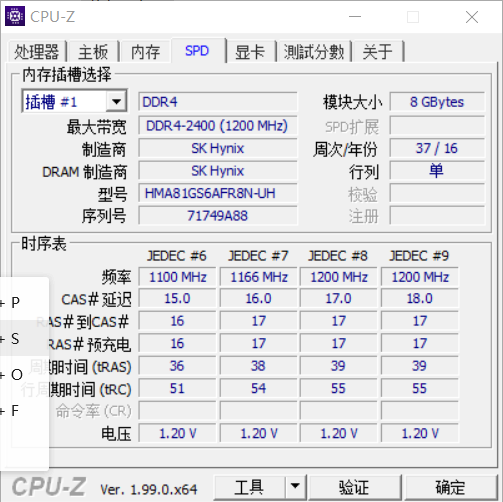 后端 - 笔记本准备加装一根内存条,请大佬帮忙推荐一根笔记本内存条?
后端 - 笔记本准备加装一根内存条,请大佬帮忙推荐一根笔记本内存条?笔记本准备加装一根内存条,请大佬帮忙推荐一根笔记本内存条? 根据CPU-Z得到的当前内存条信息如下: 通过任务管理器获取的内存信息如下: 请大佬看看我这个配置该如何选择?选择哪个品牌比较好?选择什么型号的比较好? 小弟跪谢。 我在淘宝上咨询了客服,他推荐给了我 2400Mhz 的内存条,但是我这个看着是 1200Mhz 的吧,我不太确定,请大佬指点。
-
Aws ec2实例中docker容器内的“Composer update”命令内存不足错误
我已尝试在Aws ec2实例中的docker容器内运行“composer update”命令。但是我得到了这个错误 我试过在php配置文件中使用“memory_limit=-1”或“memory_limit=2G”。我还尝试在我的docker容器中运行这个命令“php-dmemory_limit=-1 /usr/local/bin/composer更新”。但还是显示了同样的错误
-
火花内部-重新分区是否加载内存中的所有分区?
我在任何地方都找不到如何在RDD内部执行重新分区?我知道您可以在RDD上调用重新分区方法来增加分区数量,但它是如何在内部执行的呢? 假设,最初有5个分区,他们有- 第一个分区 - 100 个元素 第二个分区 - 200 个元素 第 3 个分区 - 500 个元素 第 4 个分区 - 5000 个元素 第 5 分区 - 200 个元素 一些分区是倾斜的,因为它们是从HBase加载的,并且数据没有正确
-
选择分布式共享内存解决方案
问题内容: 我的任务是为可大规模扩展的分布式共享内存(DSM)应用程序构建原型。原型仅用作概念验证,但我想通过选择稍后在实际解决方案中使用的组件来最有效地利用我的时间。 该解决方案的目的是获取来自外部源的数据输入,将其搅动并使结果可用于许多前端。这些“前端”将仅从缓存中获取数据并提供服务,而无需额外的处理。该数据的前端命中量实际上可以是每秒数百万。 数据本身非常不稳定。它可以(并且确实)快速变化。