《内存淘汰》专题
-
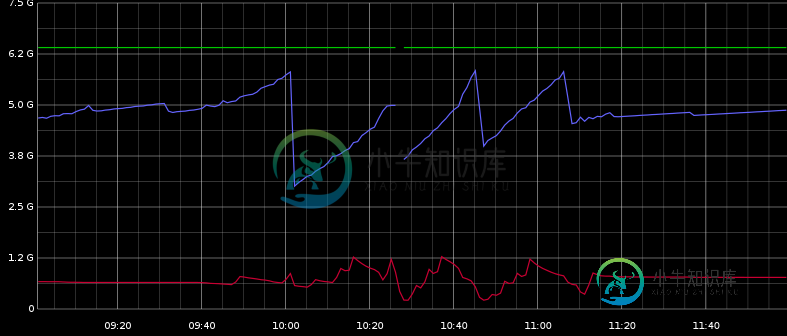 监视JVM的非堆内存使用情况
监视JVM的非堆内存使用情况我们通常处理OutOfMemoryError问题是因为堆或permgen大小配置问题。 但所有JVM内存都不是permgen或heap。据我理解,它还可以与线程/堆栈、原生JVM代码... 但是使用pmap我可以看到进程分配了9.3G,这是3.3G的离堆内存使用量。 我想知道有什么可能性来监视和调优这种额外的离堆内存消耗。 我不使用直接离堆内存访问(MaxDirectMemorySize是64M默
-
spring web Development-禁用静态内容的缓存
这是我的Build.Gradle文件
-
Mongodb C#查询排序超出内存限制
我有2周的时间来学习和使用MongoDB,我正在使用DataGridview构建一个简单的WinForm APP。 一切正常,但我添加了超过 1.000.000 个文档,现在它向我显示此错误: MongoDB.Driver.MongoCommandException:“命令聚合失败:排序超出了 104857600 字节的内存限制,但未选择加入外部排序。正在中止操作。Pass allowDiskUs
-
JNI库在垃圾收集时释放内存?
我正在使用JCUDA,想知道JNI对象是否足够聪明,可以在垃圾收集时解除分配?我能理解为什么这可能在所有情况下都不起作用,但我知道它会在我的情况下起作用,所以我的后续问题是:我如何才能完成这一点?有没有我可以设置的“模式”?我需要构建抽象层吗?或者答案真的是“不,永远不要尝试”,那么为什么不呢? 编辑:我只是指通过JNI创建的本机对象,而不是Java对象。我知道所有Java对象都被平等地对待,即垃
-
内存消耗高于wiredtigercachesizeg中设置的值
你好,专家们 我有一个mongodb服务器在我的2GB ec2实例上运行,使用以下命令 mongod-WiredTigerCacheSizeGb=0.5 下面是我的内存使用情况: 根据我的理解,使用的虚拟地址空间是MongoDB占用的总内存。如果有人能告诉我为什么它会超过0.5(500MB)的限制 内存消耗高于wiredtigercachesizeg中的设置值
-
关闭JavaFX阶段后如何释放内存?
我正在创建一个应用程序,当我单击一个按钮时,它将在new中打开一个表。但我的问题是,当我关闭该表的时,应用程序不会释放内存。JavaFX有什么问题吗?还是我得做点别的? 我尝试在该阶段结束时将所有内容设置为空,但仍然没有释放内存。 表的舞台上的关闭事件: 表视图; 舞台我的舞台; 我已经创建了一个名为replaceScene方法来使用文件为Stage加载场景。它将返回它的控制器和设置的场景进入舞台
-
从Firebase存储读取文件的值/内容
是否可以在不使用下载功能的情况下读取文件中的值? 代替的东西: 类似于:
-
ITextSharp 内存不足异常合并多个 pdf
我必须将多个1页pdf合并为一个pdf。我使用iTextSHarp 5.5.5.0来实现这一点,但当我合并超过900-1000个pdf时,会出现内存不足异常。我注意到,即使我释放并关闭阅读器,内存也不会得到正确的清理(进程使用的内存量永远不会减少),所以我想知道我可能做错了什么。这是我的代码: 它从来没有开始写文件,我在p.Copy()过程中得到一个内存不足的异常。AddPage()部分。我甚至尝
-
为什么JVM总分配内存大于-Xmx?
JVM选项: 正如预期的那样,JVM将为JVM堆分配将近20MB的内存。 但请参阅以下 GC 详细信息: PSYoungGen总计9216K,已用4612k[0x 00000000 ff 6000000,0x 0000000010000000100000000]< br > Eden空间8192K,56%已用[0x 000000000 ff 600000,0x 0000000 FFA 812d 8
-
超过GC开销限制,但内存充足
我的JBoss服务器出现了一个奇怪的问题:引发的异常: 我寻找内存不足的情况,但内存可用性看起来很好: 以前有没有人遇到过这个GC异常,当时似乎内存很大?
-
在Android中从内存流播放WAV音频
我将从REST服务接收非常短的音频数据。它们将以WAV格式到达。然后我需要在Android设备上播放它们。我想在不将数据保存到文件的情况下完成这项工作——这只会让它变得比需要的更复杂。然而,我无法从内存流让它工作。下面是我正在使用的测试代码(使用assets文件夹中的.wav文件): 当我从文件中播放它时,它是好的,但是内存流方法给了我一个IO异常准备失败错误。我怀疑问题可能是音频/wav值。我找
-
PhantomJS web驱动程序停留在内存中
用这个来清理它: 进程应该退出还是留在内存中?如果它应该留在内存中,在Windows7任务管理器中可见,我可以用编程方式杀死它吗?我应该吗?
-
具有数千个线程的内存设置
每次运行程序时,我都会调整,以查看它的效果。 然后,我将作业(的实例)提交到池。每一个都增加一个,做一些工作(创建一个随机整数数组并对其进行洗牌),然后Hibernate一段时间。其思想是模拟一个web服务调用。最后,作业将自己重新提交到池中,这样我总是有作业在工作。 我正在测量吞吐量,例如每分钟处理的作业数。 现在的问题是:我得到了一个,作业超过了31,000个。我尝试过设置,但这没有帮助。我尝
-
iText7合并2个PDF内存流不工作
我正在将一些旧的iTextSharp代码升级到新的iText 7库。我很难确定将2个PDF MemoryStream合并为一个PDF MemoryStream的正确方法,该PDF MemoryStream包含来自两个源PDF MemoryStream的所有页面。这看起来很简单,我认为下面的代码设置正确,但生成的PDF内存流只包含第一个文件。第二个PDF文件从未出现,也从未连接到第一个PDF文件。
-
为什么内存使用少于XMS?[副本]
我有一个简单的java程序,它使用和参数运行。所以初始堆是512Mb,这意味着我的JVM必须请求我的OS在我启动程序时为它分配至少512Mb。如果打开jconsole,我会看到最大堆大小为524MB(JVM本身需要一些额外的内存),提交内存为524(保证Java VM可用的内存量)。但如果执行 然后我明白了 我很困惑。怎么会低于512MB呢?