《性能测试》专题
-
GWT编译时间性能改进
我们在当前项目中使用GWT 2.4版。在服务器端,我们使用Spring 我们使用Maven作为构建工具。该应用程序正在JBOSS 7服务器上部署。 目前,我们在一个Eclipse项目中拥有所有内容。指一个应用程序。gwt。xml文件和一个ApplicationContext。spring的xml。我们有大约2000个Java文件,其中大约1500个用于GWT相关的源文件。 该项目仍在增长,源文件越
-
WorkbookF的Apache Poi性能问题actory.create()
我正在尝试使用apache poi插件从excel文件中检索命名范围。 代码段如下所示。 我看到调用需要很长时间-大约3秒。 有没有更快的方法来获取与excel表关联的所有命名范围?
-
Hibernate:n1和实体图的低性能
我们升级到Hibernate 5,之后我们开始遇到性能问题。 我们有几个实体有这样的关联: 我们正在使用Criteria API从数据库中获取数据。 以前(版本4,旧的Criteria API),Hibernate仅基于FetchType生成一个带有获取所有数据的连接语句的选择。EAGER,但使用Hibernate 5,它会创建多个额外的查询来获取“位置”数据——N 1问题。 现在,我们尝试了JP
-
flash math.random()返回1的可能性
我们都知道很古老的。它返回一个介于0和1之间的随机浮点数。 我似乎找不到任何证据来证明零或一是排他性的还是包容性的。
-
闪烁窗口拖动流性能
作业并行性(4,8,16):[自动生成源]-->[Map1]-->[滚动窗口(10s)]-->[Map2]-->[接收器] Flink窗口性能eps 4p、8p、16p 作业以上的性能最高达到了每秒50k+-左右,不管我如何将集群缩放成4-16的并行度。 闪烁性能无窗口4p、8p 我已经删除了窗口的逻辑,以消除瓶颈性能的应用程序逻辑,但似乎窗口仍然导致我的整个流性能下降,即使该窗口只是一个通过函数
-
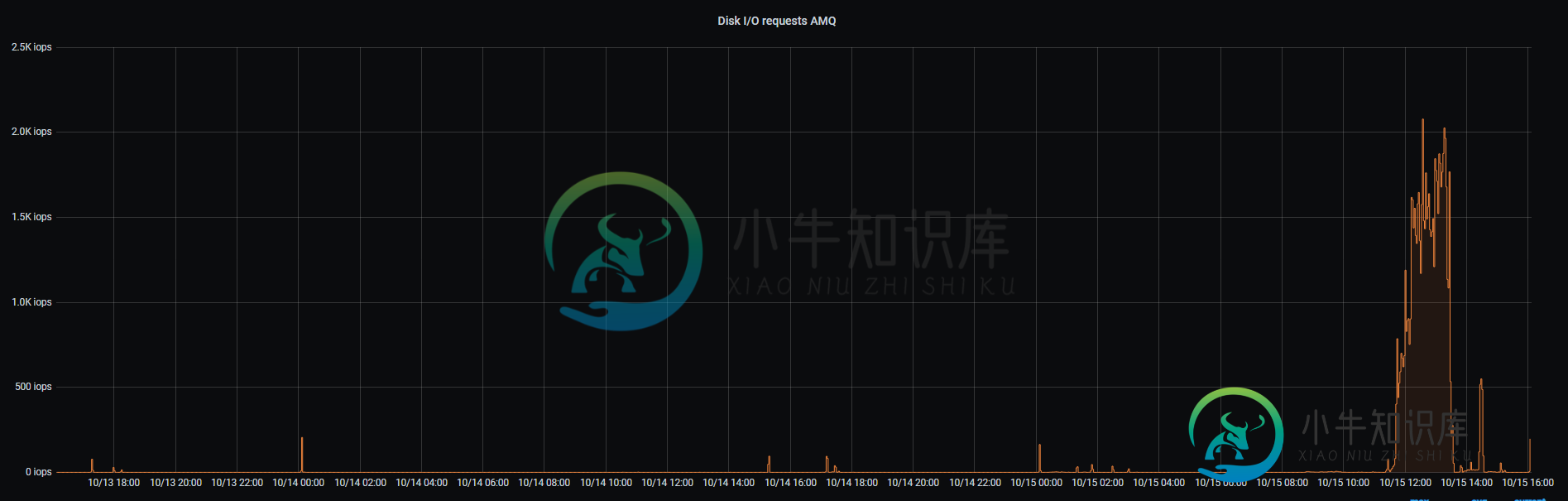 分页后ActiveMQ Artemis性能下降
分页后ActiveMQ Artemis性能下降在代理切换到分页模式后,我看到性能出现了奇怪的下降。一些消息开始花很长时间: 1800 我还看到了大量磁盘使用情况: 我的: Linux Astra、4 CPU 24GB ram 50GB SSD、ActiveMQ Artemis 2.7.0 只有代理重启有帮助
-
Apache Flink使用Java-性能问题
我们有一个在 Java 上编写并在 AWS Kinesis Data Analytics 上运行的 flink 应用程序。应用程序从 AWS 托管服务 Kafka(kafka 主题 1)读取输入流,然后应用业务逻辑(一些计算),最后将输出写入另一个 Kafka 主题(kafka 主题 2)。 并行度为 10,主题有 15 个分区。预计在 5 分钟内处理 ~20K 并发数据。但是,经过所有优化后,我
-
Elasticsearch索引性能:节流合并
我们将数据导入到elasticsearch集群中的索引很少,每个索引约为10GB。 同时,我们关心对现有索引的搜索,很少是小的-100MB,也很少是大的-10GB。 根据这些文章和拉请求,我们不应该接触合并设置在所有。 在这里非常困惑,任何帮助都非常感谢。
-
配置单元UDF性能太慢
我在Select query where条件下执行了带有自定义配置单元UDF函数的配置单元SQL脚本,它已经运行了两天多。我想知道这里到底有什么问题?调用java需要很多时间,还是查询执行本身需要很多时间? 我的数据集如下,A表有200万条记录,B表有100万条记录,
-
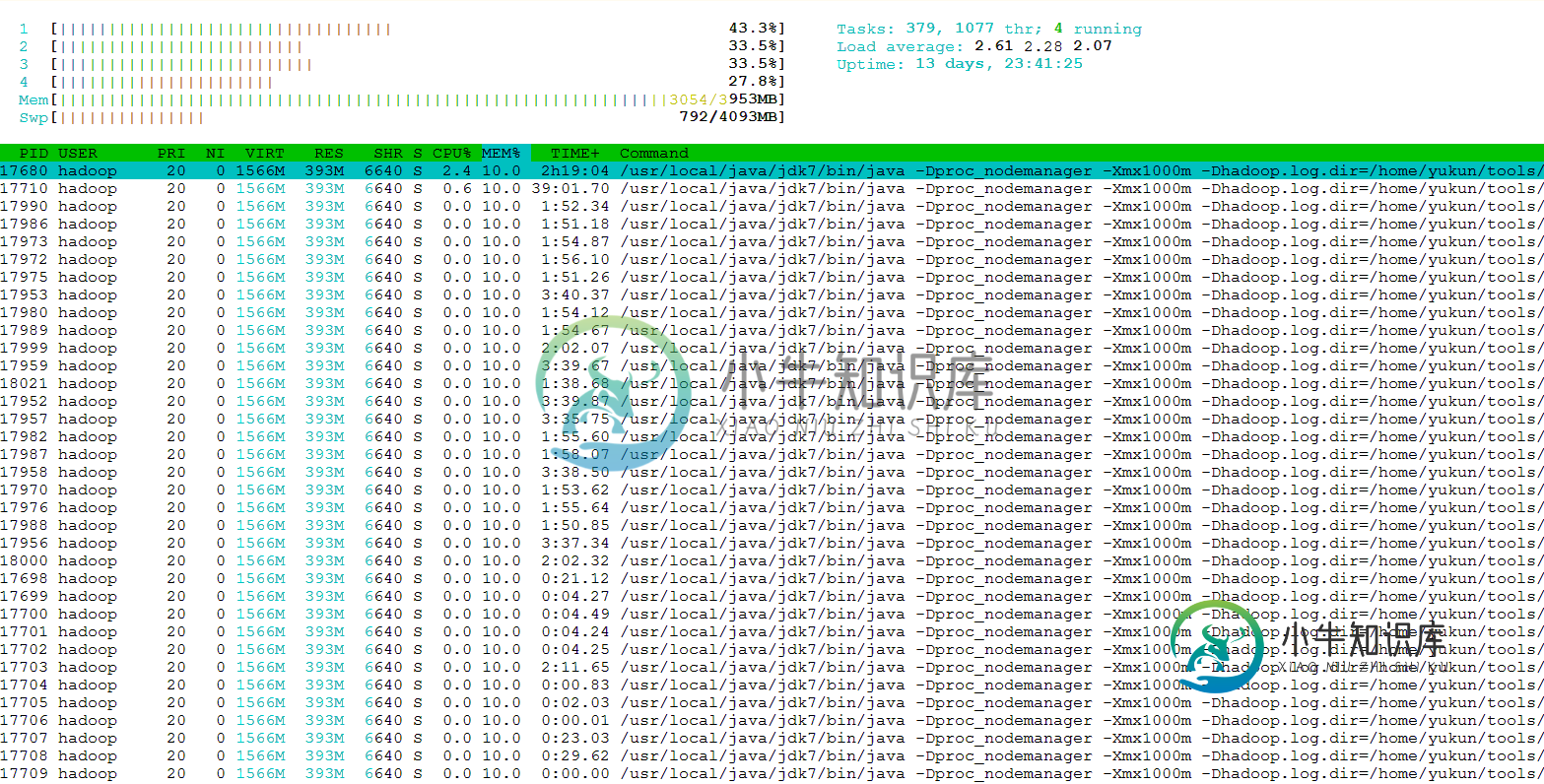 hadoop纱单节点性能调优
hadoop纱单节点性能调优我在我的Ubuntu VM上有hadoop 2.5.2单模式安装,它是:4核,每个核3GHz;4G内存。这个VM不是用于生产的,只用于演示和学习。 然后,我使用python编写了一个vey简单的map-reduce应用程序,并使用该应用程序处理49个XML。所有这些xml文件都很小,每个文件都有数百行。所以,我期待一个快速的过程。但是,big22令我惊讶的是,它花了20多分钟才完成这项工作(该工作
-
SecurityContext#setAuthentication能保证可见性吗?
我在我的项目中使用spring security。 我有更改登录的功能。为了实现这个目标,我使用以下代码 但现在我正在详细研究这段代码,并看到身份验证字段不是易变的,因此不保证可见性: 我应该用自己的同步来包装代码以实现可见性吗? 我读过https://stackoverflow.com/a/30781541/2674303 在单个会话中接收并发请求的应用程序中,相同的SecurityContex
-
Hibernate@DynamicUpdate(value=true)@SelectBeForeUpdate(value=true)性能
首先,我会试着解释我对它的理解,以知道我对它的理解是否正确。 只更新实体中的修改值 在之前创建,以了解哪些属性已被更改,这在实体已在不同会话上加载和更新时非常有用 在中,哪个更好或更快,一次更新实体中的所有字段,还是
-
Java性能问题-Tomcat WebappClassLoader锁定
在过去的几天里,当我使用Java6、Struts3框架和Tomcat7服务器对我的产品进行性能测试时,我一直面临着这个奇怪的问题
-
Spring无功高负荷性能差
我有一个spring boot webflux应用程序,默认情况下使用Netty。其中一个业务需求,我们有要求,要求应超时在2秒内。 当很少的请求被发送到应用程序时,一切都很好,但是当请求负载增加时(比如Jmeter每秒并发超过40或50次),由于每个请求的时间超过2秒阈值,有时所有请求都会超时。 如果有人能告诉我该做什么,那将是一个巨大的帮助。在这一点上,我没有更多的改进,并认为我可能已经看错了
-
短路评估的性能影响
免责声明:我对反向工程字节码没有太多的经验,所以请不要对我太苛刻,如果这可以“轻松”回答我的问题。