《流程》专题
-
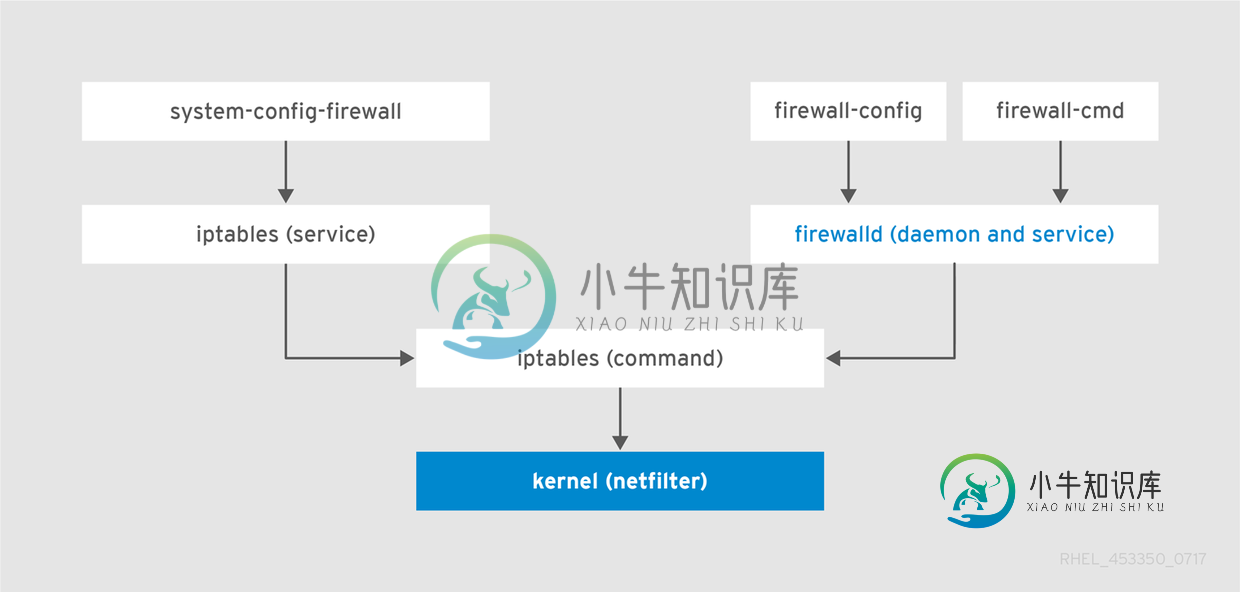 Linux下双网卡Firewalld的配置流程(推荐)
Linux下双网卡Firewalld的配置流程(推荐)本文向大家介绍Linux下双网卡Firewalld的配置流程(推荐),包括了Linux下双网卡Firewalld的配置流程(推荐)的使用技巧和注意事项,需要的朋友参考一下 实验室拟态存储的项目需要通过LVS-NAT模式通过LVS服务器来区隔内外网的服务,所以安全防护的重心则落在了LVS服务器之上。笔者最终选择通过firewalld放行端口的方式来实现需求,由于firewall与传统Linux使用的
-
您如何与Docker的流程连接和分离?
问题内容: 我可以附加到docker进程,但是+ 不能与其分离。基本上停止了这个过程。 建议使用什么工作流程来运行流程,偶尔将其附加以进行一些更改,然后分离? 问题答案: 要在不退出外壳的情况下分离tty,请使用转义序列+ 后跟+ 。更多细节在这里。 此来源的其他信息: docker run -t -i→可以与docker attach 分离并重新连接 docker run -i→不能与分离; 会
-
什么是一个好的docker webdev工作流程?
问题内容: 我有种预感docker可以极大地改善我的webdev工作流程- 但我还没有设法解决如何将docker添加到堆栈中的问题。 基本软件堆栈如下所示: 软件 提供自定义LAMP堆栈的Docker映像 Apache与几个模块 MySQL数据库 的PHP 一些CMS,例如Silverstripe GIT 工作流程 我可以想象工作流程看起来如下所示: 发展历程 编写一个定义满足上述要求的LAMP容
-
学习JavaScript事件流和事件处理程序
本文向大家介绍学习JavaScript事件流和事件处理程序,包括了学习JavaScript事件流和事件处理程序的使用技巧和注意事项,需要的朋友参考一下 本文全篇介绍了JavaScript事件流和事件处理程序,分享给大家供大家参考,具体内容如下 一、事件流 事件流描述的是从页面中接收事件的顺序。IE的事件流是事件冒泡流,而Netscape Communicator的事件流是事件捕获流。 二、事件冒泡
-
在单个Java进程中处理多个Kinesis流
我想在同一个Java过程中使用KCL处理多个Kinesis流。 想法很简单:为每个流创建一个新的KCL实例,然后并发运行worker。 我的问题是,在这种情况下,所有KCL实例是否都使用相同的线程池,以及在处理流处理时,这种想法是否是一种好的/常见的做法。 非常感谢。
-
一个datanode 宕机,怎么一个流程恢复
本文向大家介绍一个datanode 宕机,怎么一个流程恢复相关面试题,主要包含被问及一个datanode 宕机,怎么一个流程恢复时的应答技巧和注意事项,需要的朋友参考一下 解答: Datanode宕机了后,如果是短暂的宕机,可以实现写好脚本监控,将它启动起来。如果是长时间宕机了,那么datanode上的数据应该已经被备份到其他机器了,那这台datanode就是一台新的datanode了,删除他的所
-
缺陷报告的生命周期(处理流程)?
本文向大家介绍缺陷报告的生命周期(处理流程)?相关面试题,主要包含被问及缺陷报告的生命周期(处理流程)?时的应答技巧和注意事项,需要的朋友参考一下 激活、待确认、已解决、待确认、重新激活、已关闭
-
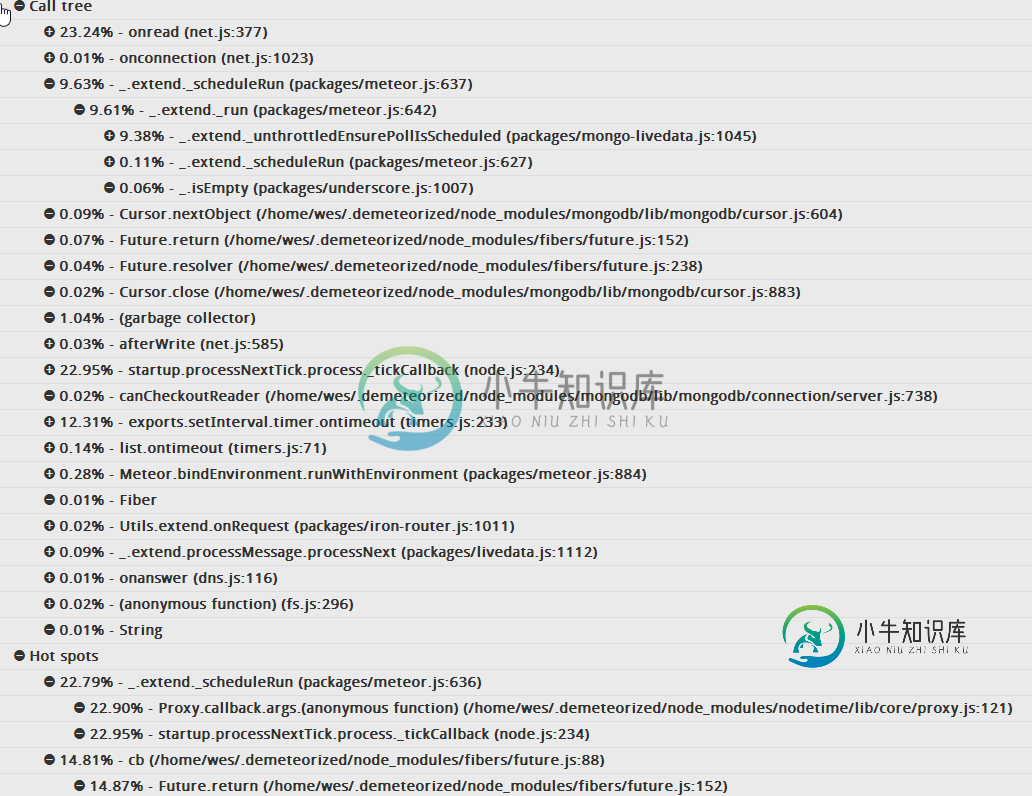 流星节点进程CPU使用率接近100%
流星节点进程CPU使用率接近100%问题内容: 当Meteor应用达到峰值流量时,我遇到了麻烦(请注意,这没什么,每天访问1000次,一天的综合浏览量可能为2500次)。CPU使用率会激增并且永远不会恢复,因此我开始使用Nodetime来监视使用率,并且我一直在重新加载进程()以使一切恢复正常。 我对概要分析还很陌生,因此找到根本原因使我不知所措。我相当确定它与我的应用程序的服务器代码有关,但性能分析似乎将Fibers模块指向“热点
-
如何以编程方式创建Django ViewFlow流程
问题内容: 概要 我正在开发一个Web应用程序以学习Django(python 3.4和Django 1.6.10)。该Web应用程序具有复杂且经常更新的工作流程。我决定集成Django-Viewflow库(https://github.com/viewflow/viewflow/),因为这似乎是处理工作流且不将工作流逻辑与应用程序模型合并的一种非常方便的方法。 在这种情况下,我创建了一个工作流以
-
Spring Security OAuth2:处理过期访问的流程Ken
我只是Spring Security Oauth2的初学者。我尝试使授权服务器和资源服务器(分离并连接到JDBC)和目的是使单点登录。我的流成功地从授权服务器获取accesstoken和refreshtoken。我的accesstoken总是作为参数访问资源服务器,这是给出一个响应。 我的问题是,如果accesstoken过期,Spring Security性将阻止访问该页面并给出错误异常。当我必
-
在后台线程中从流中获取位图
我有ListView显示从服务器下载的图像。我需要执行的步骤是: 调用api获取流。 从该流中获取字节[]。 将这些字节保存在File对象(在sd卡中)中。 从该文件路径/位置获取位图。 在ImageView中显示位图。 前4个步骤需要在后台线程中执行,以保持主线程未被占用,以便用户可以在后台下载图像时顺利滚动列表。第 5 步需要在 UI 线程上执行。 我在后台执行这些步骤时遇到问题。 这就是我在
-
Spark结构化流式多线程/多消费者
我正在使用spark结构化流媒体、合流开源Kafka集群开发spark流媒体应用程序,并在AWS EMR中运行spark job。我们至少有20个Kafka主题,以AVRO格式将数据生成单个Kafka主题,每个主题在3到4个分区之间进行了分区。我正在使用Spark阅读所有20个主题(逗号分隔的主题值)。然后从生成的数据帧中过滤每个消息行,使用正确的Avro模式应用每个消息,并将生成的写入S3和Ca
-
BDD和TDD,正确的工作流程是什么?
BDD是一个评估软件需要如何运行的过程,然后编写代码所依据的验收测试。您可以使用TDD方法编写代码,为方法编写单元测试,并围绕单元测试(代码、测试、重构)构建类。当代码编写完成时,您将对其进行测试,以查看是否满足原始的验收测试。 有经验的人可以对我的解释进行评论,并用这些敏捷原则来演示一个简单的应用程序吗?我看到在不同的出版物中有大量关于BDD和TDD的文本,但我正在研究这两个过程在现实世界的开发
-
以编程方式捕获网络流量(无根)
我正在尝试寻找资源或库,可以让我捕捉所有网络数据包的流量的设备编程,无论是从wifi或移动网络。我相信不需要root用户就可以像shark for root用户所要求的那样进入这种混乱的模式,因为play store上有一个应用程序,它可以捕获所有的网络流量(甚至用MITM解密SSL),而不需要root用户。我根本想不出如何做同样的事。 我的问题是:这款app是如何实现这种抓取的?他们用了什么AP
-
如何引流Java线程堆栈内存区域?
在C语言中,我可以用下面的小程序来耗尽堆栈内存区域(我的Mac中堆栈大小的限制是8MB) 由于数组是Java也是一个对象,它的元素存储在堆中。根据Oracle的文档,默认的线程堆栈大小在MAC中为512KB。是否有任何程序可以耗尽堆栈大小?