《数据湖》专题
-
StackExchange.Redis 复杂数据(Protobuf)
本文向大家介绍StackExchange.Redis 复杂数据(Protobuf),包括了StackExchange.Redis 复杂数据(Protobuf)的使用技巧和注意事项,需要的朋友参考一下 示例 StackExchange.Redis还支持通过pub / sub通道发送字节,这里我们使用protobuf-net将消息序列化为字节数组,然后再发送: 订户再次需要在收到消息后反序列化消息:
-
hive 创建数据库
本文向大家介绍hive 创建数据库,包括了hive 创建数据库的使用技巧和注意事项,需要的朋友参考一下 示例 在特定位置创建数据库。如果我们不为数据库指定任何位置,则其在仓库目录中创建。
-
恢复MySQL数据库
问题内容: 我已经使用名为library的数据库的mysqldump实用程序创建了一个名为ab.sql的文件。工作正常。现在,我正在尝试使用mysqlimport还原它。我的数据库已经存在。但我想重写它。我正在使用命令 在命令行中,但显示错误消息, mysqlimport:错误:1146,使用表:ab时,表’library.ab’不存在 迫切需要帮助。 问题答案: mysqlimport将文本文件
-
Elasticsearch批量JSON数据
问题内容: 似乎我有一个相似但不相同的查询,因此最好像@Val建议的那样,让其他人从中受益。 因此,类似于上述内容,我需要在索引中插入大量数据(我的初始测试大约是10000个文档,但这只是针对POC,还有更多)。我想插入的数据在.json文档中,看起来像这样(片段): 我自己是ElasticSearch的新手,但是,从阅读文档开始,我的假设是我可以获取.json文件并根据其中的数据创建索引。从那以
-
熊猫:重塑数据
问题内容: 我有一个熊猫系列,目前看起来像这样: 我想从根本上将其重塑成一个看起来像这样的数据框… 即。逻辑构造,指出每个观察(行)属于哪个类别。 我能够编写基于循环的代码来解决该问题,但是鉴于我需要处理的行数众多,这将非常缓慢。 有谁知道针对这种问题的矢量化解决方案?我将不胜感激。 编辑:有509个类别,我确实有一个清单。 问题答案:
-
数据类型不明
问题内容: 我正在尝试使用矩阵来计算内容。代码是这个 但我收到“无法理解的数据类型”,并且如果我从终端执行此操作,它将起作用。 问题答案: 尝试: 由于shape参数必须是int或int序列 http://docs.scipy.org/doc/numpy/reference/generation/numpy.zeros.html 否则,您将作为dtype传递给。
-
Axios未发布数据
我正在尝试使用axios发送数据,但它发送的响应超出预期。当我使用postman发出相同请求时,它会成功地向我的手机发送通知,以下是postman的响应: 但是使用axios,通知不会发送到我的手机,以下是axios的响应: 这是我的axios代码:
-
Spring数据Rest和Hateoas
我遵循一个简单的教程来测试SpringDataREST的行为,用@RestResource注释库。我有一个非常简单的场景:用@RestResource注释的Jpa用户实体和用户存储库 我使用注释配置初始化,并尝试注册RepositoryRestMvcConfiguration,以便可以注册UserRepository。但是我的应用程序没有启动,我有以下例外 我使用sping-hateoas: 0.
-
Kendo+角度图数据
问题内容: 我正在尝试使用角度的Kendo图表,但在显示数据时遇到问题,这是我的代码: HTML: Javascript: 问题是从服务器获取数据后图表未更新,我尝试过这样刷新图表(但没有运气): 并在以下方法中调用此方法: 而且我也尝试过定义相同的函数,但是什么也没定义。有没有什么办法解决这一问题 ? 问题答案: 它的文档记录不充分,但是要获得具有远程数据绑定的UI控件以在从服务器返回数据后进行
-
yaml YAML顺序数据
本文向大家介绍yaml YAML顺序数据,包括了yaml YAML顺序数据的使用技巧和注意事项,需要的朋友参考一下 示例 同一列表级别: 嵌套列表:
-
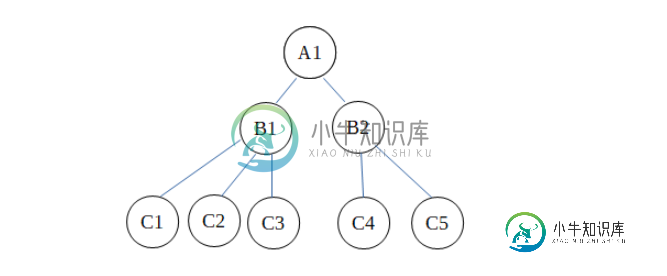 分层数据模型
分层数据模型本文向大家介绍分层数据模型,包括了分层数据模型的使用技巧和注意事项,需要的朋友参考一下 分层数据模型是最早的数据模型之一。该模型是基于文件的模型构建,就像树一样。在此树中,父节点可以与多个子节点关联,但是一个子节点只能有一个父节点。 对于目录和文件,可以说单个目录进一步包含多个文件或目录,然后这些目录包含更多文件,依此类推。 这可以表示为- 示例 使用关系数据库的层次模型的示例如下- <员工> E
-
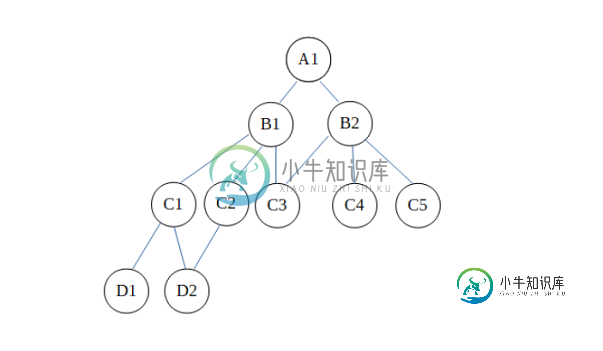 网络数据模型
网络数据模型本文向大家介绍网络数据模型,包括了网络数据模型的使用技巧和注意事项,需要的朋友参考一下 创建网络数据库模型是为了解决分层数据库模型的缺点。在这种类型的模型中,一个孩子可以链接到多个父母,而分层数据模型不支持该功能。父节点称为所有者,子节点称为成员。 网络数据模型可以表示为- 网络模型的优势 如图所示,网络模型可以支持许多关系。D2和C3每个都有多个主机。D2的主控是C1和C2,而C3的主控是B1和
-
关系数据模型
本文向大家介绍关系数据模型,包括了关系数据模型的使用技巧和注意事项,需要的朋友参考一下 关系数据模型是最著名的数据模型,全世界大多数人都在使用它,它是一种简单而有效的数据模型,并具有以最佳方式处理数据的能力。 表用于处理关系数据模型中的数据。包含有关公司员工数据的表格示例如下- <员工> Emp_Number Emp_Name Emp_Designation Emp_Age Emp_Salary
-
Firebase脱机数据库
我的应用程序有一个目录,它使用Firebase来存储和更新数据。我想显示已经缓存的数据,如果应用程序被杀死,并再次启动,而不在线。 firebase是否在应用程序被终止时删除缓存? 无论用户在线或离线,我们都可以首先推送离线数据。
-
Yii2-数据已删除
我正在运行一个Yii2应用程序。今天我遇到了一个问题,至少有250个条目的整个表都是空的。该表由文件信息条目(原始文件名、新文件名)组成。因此,每个条目在逻辑上都链接到文件系统中的一个文件。我检查了文件系统的文件,发现文件也被删除了。因此,我得出结论,数据在yii2应用程序中被删除。我有一个操作将被调用(POST)来删除一个条目。 我为它做了一种通用函数: 在视图中,我有一个带有操作列的文件附件列