
网络数据模型

创建网络数据库模型是为了解决分层数据库模型的缺点。在这种类型的模型中,一个孩子可以链接到多个父母,而分层数据模型不支持该功能。父节点称为所有者,子节点称为成员。
网络数据模型可以表示为-
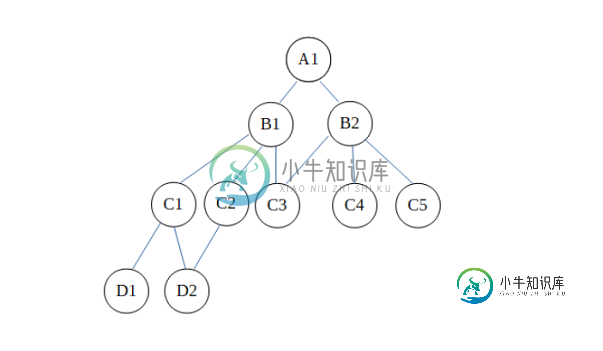
网络模型的优势
如图所示,网络模型可以支持许多关系。D2和C3每个都有多个主机。D2的主控是C1和C2,而C3的主控是B1和B2。这样,网络数据模型可以处理许多层次结构数据模型所没有的关系。
网络模型的缺点
即使是对分层模型的改进,网络模型也存在一些缺点。这些是-
网络模型比层次模型复杂得多。因此,难以处理和维护。
尽管网络模型比分层模型更灵活,但仍然存在灵活性问题。并非所有关系都可以通过以所有者和成员的形式进行分配来处理。
网络模型的结构非常复杂,因此程序员必须充分理解它才能实现或修改它。
-
在网络数据菜单下设置了一个连接服务器的功能,通过这个功能,可以直接通过网络地址连接到远程的服务器,从而实现一份数据,多客户端共享。 创建一个服务器连接 只需要输入服务器的ip地址,端口号,账号和密码就可以快速建立一个连接,并保存。 删除已有连接 对于不想出现在服务器连接列表里的连接,可以选中后直接删除。 连接已有服务器 选中一个连接,直接点击
-
在网络数据菜单下设置了一个连接服务器的功能,通过这个功能,可以直接通过网络地址连接到远程的服务器,从而实现一份数据,多客户端共享。 创建一个服务器连接 只需要输入服务器的ip地址,端口号,账号和密码就可以快速建立一个连接,并保存。 删除已有连接 对于不想出现在服务器连接列表里的连接,可以选中后直接删除。 连接已有服务器 选中一个连接,直接点击
-
网络模型 在某些情况下,你需要理解Subversion客户端如何与服务器通讯。Subversion网络层是抽象的,意味着Subversion客户端不管其操作的对象都会使用相同的行为方式,不管是使用HTTP协议(http://)与Apache HTTP服务器通讯或是使用自定义Subversion协议(svn://)与svnserve通讯,基本的网络模型是相同的。在本小节,我们要解释网络模型基础,包括
-
Kubernetes网络模型 IP-per-Pod,每个Pod都拥有一个独立IP地址,Pod内所有容器共享一个网络命名空间 集群内所有Pod都在一个直接连通的扁平网络中,可通过IP直接访问 所有容器之间无需NAT就可以直接互相访问 所有Node和所有容器之间无需NAT就可以直接互相访问 容器自己看到的IP跟其他容器看到的一样 Service cluster IP尽可在集群内部访问,外部请求需要通过
-
我有一个数据框架,其中一些列是网络的节点: 我的预期结果如下: 考虑到每个节点的交互作用。 我尝试了以下代码,但没有成功: 感谢任何帮助。下面是一个可重复的示例: 谢谢
-
虽然之前我们已经提到过不建议直接使用 LogStash::Inputs::TCP 和 LogStash::Outputs::TCP 做转发工作,不过在实际交流中,发现确实有不少朋友觉得这种简单配置足够使用,因而不愿意多加一层消息队列的。所以,还是把 Logstash 如何直接发送 TCP 数据也稍微提点一下。 配置示例 output { tcp { host => "19