《数据湖》专题
-
1.6 数据管理
“数据管理”用来管理“百度统计-分析云”所追踪的数据,帮助您对产品内所有的数据进行统一管理和维护。 新版分析云的数据模型由之前的“PV模型”升级为“事件模型”。支持您对产品进行更多场景下的精细化分析。在使用分析云进行分析前,您需要在“数据管理”内定义“事件”和“属性”。 事件是用户在产品上的行为,如“浏览页面”、“点击元素”等。 属性是用来描述事件的维度。在分析云中,属性不从属于具体事件,您需要从
-
1.5 数据接入
本章介绍了各端数据接入分析云的方法,包括网站、APP、微信小程序。建议您在使用分析云前根据需求阅读相关接入文章。 全埋点功能可支持圈选事件回溯,回溯数据可以在圈选事件后,前往事件分析报告查看。 百度推广授权则支持接入百度推广相关数据,使用渠道转化模块报告前请确认已进行该项授权。 本章节的主要内容包括: 网站数据接入 全埋点及埋点回溯 App数据接入 小程序数据接入 百度推广授权
-
6 数据库Seeding
Phinx 0.5.0 支持数据库中使用seeding插入测试数据。Seed 类可以很方便的在数据库创建以后填充数据。这些文件默认放置在 seeds 目录,路径可以在配置文件中修改 数据库 seeding 是可选的,Phinx 并没有默认创建 seeds 目录 创建Seed类 Phinx 用下面命令创建一个新的 seed 类 $ php vendor/bin/phinx seed:create U
-
5.4 插入数据
插入数据 Phinx 可以很简单的帮助你在表中插入数据。尽管这个功能也在 seed 中实现了。你也可以在迁移脚本中实现插入数据。 <?php use Phinx\Migration\AbstractMigration; class NewStatus extends AbstractMigration { /** * Migrate Up. */ publi
-
5.3 获取数据
获取数据 有2个方法可以获取数据。 fetchRow() 方法可以返回一条数据, fetchAll() 可以返回多条数据。2个方法都可以使用原生 SQL 语句作为参数。 <?php use Phinx\Migration\AbstractMigration; class MyNewMigration extends AbstractMigration { /** * Migr
-
单向数据流
单向数据流只关注于在store中维护的唯一的state,消除了不必要的多种states带来的复杂度. 这个store应该具有能被我们订阅(subscribe)store中变化的能力,实现如下: var Store = { _handlers: [], _flag: '', onChange: function (handler) { this._handlers.push(ha
-
数据库 - Pony ORM
Pony 是一个很有意思的 ORM, 它的特别之处在于可以使用 Python 生成器的语法来创建数据库请求, 我们可以用这样的语句来查询数据库: select(p for p in Product if p.name.startswith('A') and p.cost <= 1000) Pony 还提供了一个在线的数据库结构编辑器:Pony Editor 演示示例:University 注意:P
-
R重塑数据
本文向大家介绍R重塑数据,包括了R重塑数据的使用技巧和注意事项,需要的朋友参考一下 示例 数据通常在表中。通常,可以将此表格数据分为宽和长格式。在广泛的格式中,每个变量都有自己的列。 人 身高[cm] 年龄[yr] 艾莉森 178 20 鲍勃 174 45 卡尔 182 31 但是,有时使用长格式会更方便,因为所有变量都在一列中,而值在第二列中。 人 变量 值 艾莉森 身高[cm] 178 鲍勃
-
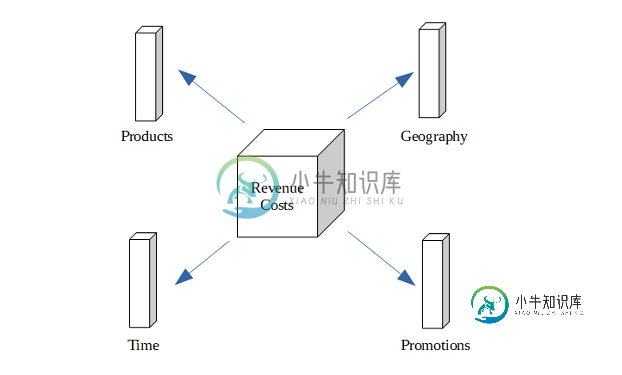 多维数据库
多维数据库本文向大家介绍多维数据库,包括了多维数据库的使用技巧和注意事项,需要的朋友参考一下 多维数据库主要用于OLAP(在线分析处理)和数据仓库。它们可用于向用户显示多维数据。 多维数据库是从多个关系数据库创建的。关系数据库允许用户以查询形式访问数据,而多维数据库则允许用户提出与业务或市场趋势有关的分析性问题。 多维数据库使用MOLAP(多维在线分析处理)来访问其数据。它们允许用户通过相当快地生成和分析数
-
移动数据库
本文向大家介绍移动数据库,包括了移动数据库的使用技巧和注意事项,需要的朋友参考一下 移动数据库与主数据库是分开的,可以轻松地传输到各个地方。即使它们没有连接到主数据库,它们仍然可以与数据库通信以共享和交换数据。 移动数据库包括以下组件- 存储所有数据并链接到移动数据库的主系统数据库。 移动数据库,允许用户即使在移动中也可以查看信息。它与主数据库共享信息。 使用移动数据库访问数据的设备。该设备可以是
-
开源数据库
本文向大家介绍开源数据库,包括了开源数据库的使用技巧和注意事项,需要的朋友参考一下 开源数据库是具有开源代码的数据库,即任何人都可以查看,研究甚至修改代码。开源数据库可以是关系(SQL)或非关系(NoSQL)。 为什么要使用开源数据库? 为任何公司创建和维护数据库都非常昂贵。在软件总支出中,很大一部分用于处理数据库。因此,切换到低成本开源数据库是可行的。从长远来看,这可以为公司节省很多钱。 使用中
-
Logcat蓝牙数据
我的蓝牙耳机与我的Android 5.1.1设备结合时出现声音问题。因此,我需要调试蓝牙连接。我已经使用获得了一些日志,但我担心这些日志可能包含有关我的机密数据。 我应该对使用哪些参数,以便日志仅包含相关的蓝牙和耳机数据?
-
MySQL数据太长?
我使用的mysql2库与NodeJS。我在本地机器和服务器上有相同的代码和数据库结构。当我上传一张照片到“照片”表时,在我的本地机器上,它工作正常。当我使用服务器时,我得到以下错误: {错误:数据太长,列'照片'在第1行Packet.as错误(/srv/project/server/node_modules/mysql2/lib/数据包/packet.js:716: 13)在查询。Command.
-
jQuery数据与Attr?
问题内容: 使用之间和使用时的用法有什么区别? 我的理解是存储在jQuery的内部,而不是DOM。因此,如果要用于数据存储,则应使用。如果要添加HTML5数据属性,则应使用。 问题答案: 如果要将数据从服务器传递到DOM元素,则应在该元素上设置数据: 然后可以.data()在jQuery中使用访问数据: 但是,当您使用数据在jQuery中的DOM节点上存储数据时,变量将存储在node 对象上。这是
-
数据库关系
问题内容: 在数据库中建立适当的关系对数据完整性以外的其他功能没有帮助吗? 它们会改善还是阻碍性能? 问题答案: 我不得不说,适当的关系将比省略它们更好地帮助人们理解数据(或数据的意图),特别是因为维护它们的总成本非常低。 它们的存在不会影响性能,除非是在体系结构方面(正如其他人指出的那样,数据完整性有时会导致外键冲突,这可能会产生某些影响),但是IMHO的许多好处(如果正确使用,则不胜枚举)。