《流处理》专题
-
跳过情况下禁用Spring批处理单件处理
我有一个工作,处理项目的大块(1000个)。这些项目被封送到一个JSON有效负载中,并作为一个批处理发布到远程服务(在一个HTTP POST中所有1000个)。有时远程服务陷入困境,连接超时。我为此设置了跳过 如果一个块失败了,批处理重试这个块,但一次一个项目(为了找出是哪个项目导致了失败)但在我的情况下,没有一个项目导致了失败,这是整个块作为块成功或失败的情况,应该作为块重试(事实上,下降到单项
-
Spring Batch:如何使块处理成为多线程处理
如何使这个多线程。?
-
块处理模式下的Spring批处理事务回滚
-
Spring批处理:无法识别项目处理器接口
我是一个初学者,刚刚开始学习Spring Batch。我在这里按照这个教程创建了一个helloworld示例。当我按照教程操作时,我在尝试将导入java类时遇到了一个问题。因此我在网上搜索,发现我需要在build.gradle.中添加一些东西。问题是,即使我在build.gradle中添加了依赖项,我仍然有导入的错误消息。我正在使用EclipseJavaEE IDE 4.5.0(Mars)来完成这
-
Kotlin Spring Boot注释处理“无法解决配置处理”
我无法在我的Kotlin Spring Boot应用程序中正确地注入应用程序属性。在我的文件中定义并随后在文件中引用的属性(在resources->META-INF下)没有正确地添加到bean表达式上下文中。使用,当我将鼠标悬停在该属性上时,我会看到错误。试图运行应用程序(将配置属性值construction-inject到类中)会导致通过构造函数参数表示的
-
使用处理库——在处理草图的Java文件中?
这是如何使用公共类frome的一个后续步骤。其他处理选项卡中的java文件?;使用来自的Usage类中的示例。java文件-有完整的文档吗?-处理2。x和3。x论坛,我有这个: /tmp/Sketch/Foo.java 这个例子运行得很好,但是如果我取消注释import peasy。组织 行,则编译失败: 当然,我确实在下安装了PeasyCam,如果我导入peasy.*它工作得很好 来自草图。 我
-
通用批处理模式 - 日志项处理和失败
11.1 日志项处理和失败 一个常见的用例是需要在一个步骤中特殊处理错误,chunk-oriented步骤(从创建工厂bean的这个步骤)允许用户实现一个简单的ItemReadListener用例,用来监听读入错误,和一个ItemWriteListener,用来监听写出错误.下面的代码片段说明一个监听器监听失败日志的读写: >public class ItemFailureLoggerListen
-
Java中的流程生成器和流程-如何执行超时的流程?
问题内容: 我需要在Java中执行具有特定超时的外部批处理文件。这意味着,如果批处理执行的时间比指定的超时时间长,我需要取消执行。 这是我编写的示例代码: 批处理文件“ wait.bat”是这样的: 如您在代码中看到的,批处理文件将花费25秒完成(main方法的第一行),并且Timer将在5秒后销毁命令。 这是我的代码的输出: 如您在输出中看到的,最后一行(“ Really Done …”)在第5
-
实现流云数据流转换,为流中的每个元素调用API
我相信,这不是实施这种转变的最佳方式。我想知道是否有更好的方法从数据流作业中进行查找。 跟进: 试图将用例实现为侧输入:
-
来自单个Google云数据流作业的并行数据流流水线
我试图从一个数据流作业中运行两个分离的管道,类似于下面的问题: 一个数据流作业中的并行管道 如果我们使用单个p.run()使用单个数据流作业运行两个分离的管道,如下所示: 我认为它将在一个数据流作业中启动两个独立的管道,但它会创建两个包吗?它会在两个不同的工人上运行吗?
-
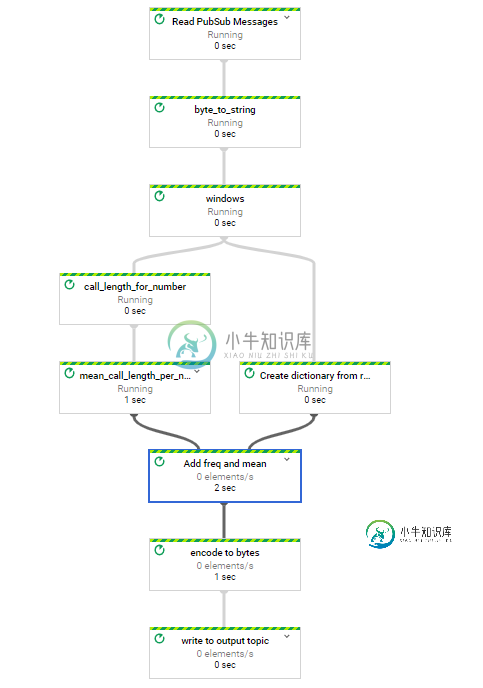 在流式流水线中组合多个边输入时数据流失败
在流式流水线中组合多个边输入时数据流失败我已经用Python SDK(Apache Beam Python 3.7 SDK 2.19.0)构建了一个窗口流数据流管道。初始数据的表示如下: 其思想是找出给定窗口中每行号码的平均通话长度。数据作为CSV的行从pub/sub中读取,我向所有行添加一个与该数字的平均调用长度相对应的值: 我使用以下管道: 有什么想法吗?
-
Spark流媒体-过滤带有地理定位的流媒体后的推文
我是一个初学者,试图使用spark streaming获得推文,使用Scala和一些过滤器关键字。是否有可能在流媒体之后只过滤那些没有地理定位为Null的推文?我正在尝试保存ElasticSearch中的推文。所以,在将tweet地图保存到ElasticSearch之前,我可以过滤那些带有地理定位信息的地图,然后保存它们吗?我正在使用json4s.jsondsl和tweet中的字段创建JSON。这
-
理解Java8和Java9中的序列流拆分器与并行流拆分器
与之间的差异: > 它们可能有不同的特点: 这里讨论的似乎是另一个毫无意义的流拆分器特性策略(并行计算似乎更好):深入理解Java8和Java9中的拆分器特性 在本例中,从禁用拆分功能的顺序流创建了一个拆分器(返回null)。当以后需要转换回一个流时,该流不会从并行处理中受益。一种耻辱。 最大的问题是:作为解决办法,在调用之前总是将流转换为并行流会有什么主要影响?
-
Spring批处理-在处理器上禁用ItemReader缓存跳过,并再次处理筛选的行
几乎我的所有批处理都有一个读取器(JpaPagingItemReader从我的数据库读取数据)、一个处理器和一个创建XML文件的写入器。这3个部分都在一个步骤,我的块大小通常在50左右。 当发生可跳过的异常时,我注意到了两个副作用,我想知道是否有一种方法可以改变这些默认行为=> 我通常在阅读器中读取JPA实体,并将它们发送到处理器,在那里我将更改它们的属性以更新数据库。但是,当发生可跳过的异常并且
-
异常处理模式
问题内容: 这是一种常见的模式,我看到与异常关联的错误代码存储为静态最终整数。当创建要抛出的异常时,将使用这些代码之一以及错误消息来构造该异常。这导致该方法要抓住它,必须先查看代码,然后决定采取的措施。 替代方法似乎是-为每个异常错误情况声明一个类(尽管相关的异常会从通用基类中删除) 有中间立场吗?推荐的方法是什么? 问题答案: 这是一个很好的问题。我相信绝对有中间立场。 我认为错误代码对于显示质