《流处理》专题
-
Kafka流内部数据管理
在我的公司,我们广泛使用Kafka,但出于容错的原因,我们一直使用关系数据库来存储几个中间转换和聚合的结果。现在我们正在探索Kafka流作为一种更自然的方法来做到这一点。通常,我们的需求很简单--其中一个例子是 监听的输入队列 对每个记录执行一些高延迟操作(调用远程服务) 如果在处理时,都已生成,那么我应该处理V3,因为V2已经过时了 为了实现这一点,我将主题作为阅读。代码如下所示 这是预期的,但
-
流量管理 - 故障注入
故障注入 本任务将演示如何注入延迟并测试应用弹性。 开始之前 参考文档安装指南中的步骤安装Istio。 部署BookInfo示例应用。 首先通过请求路由任务,或通过执行下列命令,来初始化应用的版本路由信息: 注意:这里假设尚未设置任何路由。如果已经为示例创建了存在冲突的路由规则,则需要在下列两条命令或其中之一使用replace代替create。 istioctl create -f sampl
-
流量管理 - 规则配置
Istio提供了简单的领域特定语言(DSL),用来控制应用部署中跨多个服务的API调用和4层流量。DSL允许运维人员配置服务级别的属性,如熔断器,超时,重试,以及设置常见的连续部署任务,如金丝雀推出,A/B测试,基于百分比流量拆分的分阶段推出等。详细信息请参阅路由规则参考。 例如,将“reviews”服务100%的传入流量发送到“v1”版本的简单规则,可以使用规则DSL进行如下描述: apiVer
-
流量管理 - 故障注入
虽然Envoy sidecar/proxy为在Istio上运行的服务提供了大量故障恢复机制,但测试整个应用程序端到端的故障恢复能力依然是必须的。错误配置的故障恢复策略(例如,跨服务调用的不兼容/限制性超时)可能导致应用程序中关键服务持续不可用,从而导致用户体验不佳。 Istio启用协议特定的故障注入到网络中,而不是杀死pod,延迟或在TCP层破坏数据包。我们的理由是,无论网络级别的故障如何,应用层
-
流量管理 - 请求路由
此节描述在Istio服务网格中服务之间如何路由请求。 服务模型和服务版本 如Pilot所述,特定网格中服务的规范表示由Pilot维护。服务的Istio模型和在底层平台(Kubernetes,Mesos,Cloud Foundry等)中的表示无关。特定平台的适配器负责用平台中元数据的各种字段填充内部模型表示。 Istio介绍了服务版本的概念,这是一种更细微的方法,可以通过版本(v1,v2)或环境(s
-
频道流水报表管理
获取频道报表 获取频道资金流水 获取频道打赏流水 获取频道发红包/抢红包记录 获取频道付费流水 获取观众观看流水_V2 获取观众观看流水_V1 获取频道报名问卷数据 获取频道问卷列表数据 获取频道观众列表V2 获取频道观众列表
-
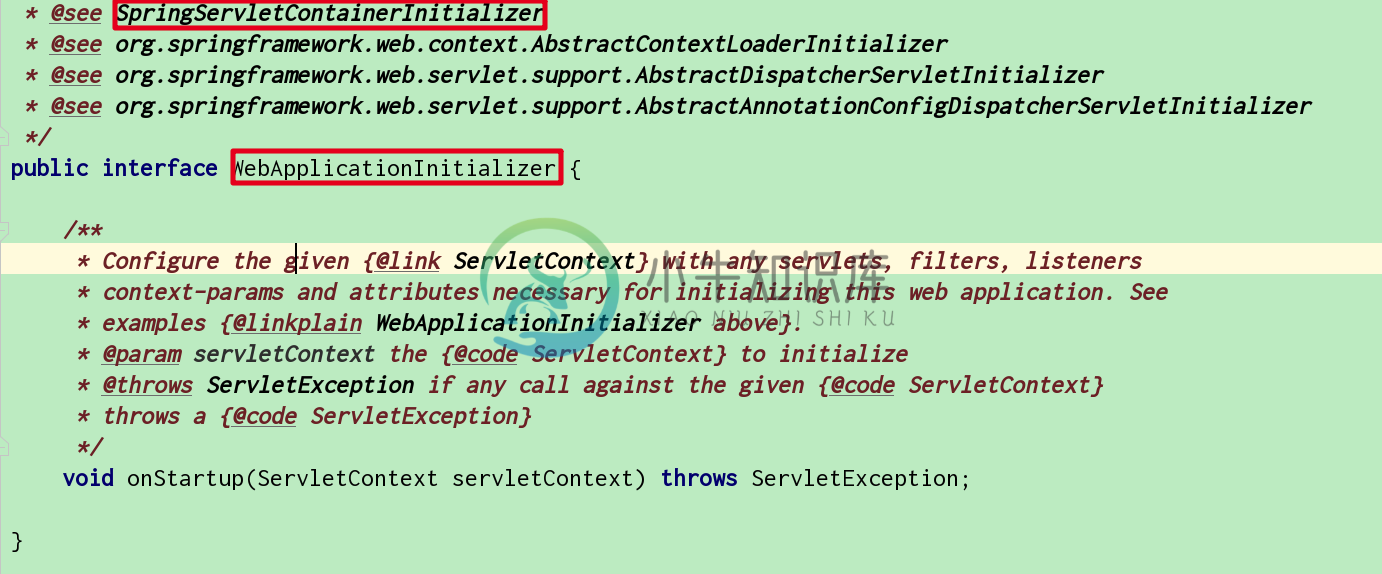 SpringMvc 启动流程和原理
SpringMvc 启动流程和原理主要内容:1.Spi机制处理,2.调用onStarterup方法,3.DispatcherServlet类分析,4.web容器的准备阶段,5.Question这里的SpringMvc是基于注解版的, 在Servlet3.0之后注解版为主要的实现方式。 1.Spi机制处理 Servlet的规范ServletContainerInitializer的实现类上面的注解代表着这个接口的实现都是来自Spi机制的。 于是加载了所有实现WebApplicationInitializer的接口的类 2.调用on
-
Java中是否有未处理的异常处理程序?
问题内容: 如果我在.NET中没有记错的话,可以为未处理的异常注册“全局”处理程序。我想知道Java是否有类似的东西。 问题答案: 是的,有,但只有在没有设置时才会触发。
-
FileServer处理程序和其他一些HTTP处理程序
问题内容: 我试图在Go中启动一个HTTP服务器,该服务器将使用自己的处理程序来提供自己的数据,但与此同时,我想使用默认的http FileServer来提供文件。 我在使FileServer的处理程序在URL子目录中工作时遇到问题。 该代码不起作用: 我期望在localhost:1234 / files /中找到本地目录,但是它返回一个。 但是,如果我将文件服务器的处理程序地址更改为/,它将起作
-
 python数据预处理 :数据共线性处理详解
python数据预处理 :数据共线性处理详解本文向大家介绍python数据预处理 :数据共线性处理详解,包括了python数据预处理 :数据共线性处理详解的使用技巧和注意事项,需要的朋友参考一下 何为共线性: 共线性问题指的是输入的自变量之间存在较高的线性相关度。共线性问题会导致回归模型的稳定性和准确性大大降低,另外,过多无关的维度计算也很浪费时间 共线性产生原因: 变量出现共线性的原因: 数据样本不够,导致共线性存在偶然性,这其实反映了缺
-
基于消息的骆驼特定异常处理处理
我有一个队列系统,骆驼只是其中的一小部分。在此队列系统中,对于某些队列,代理在队列已满时返回 FAIL。为了解决这个问题,我查看我得到的 JMS 异常,从消息中我可以看到原因是否是队列已满。 我想在Camel中实现的是,对于满队列的特定情况,我希望重试传递,而对于任何其他JMS异常(或任何其他异常),我希望将其发送到DLQ。 我假设我必须使用onException(JMSException.cla
-
10.1 字符串处理 - 10.1.1 使用 awk 处理字符串
在 Bash 脚本中可以调用字符串处理工具 awk 来替换内置的字符串处理操作。 样例 10-6. 使用另一种方式来截取和定位子字符串 #!/bin/bash # substring-extraction.sh String=23skidoo1 # 012345678 Bash # 123456789 awk # 注意不同字符串索引系统: # Bash 中第一个字符
-
多处理和子处理之间的区别是什么?
我的工作应该使用并行技术,我是python的新用户。因此,我想知道您是否可以分享一些关于python和模块的资料。这两者有什么区别?
-
Kafka消费者错误处理:混淆错误处理/RetryTemplate
我尝试在使用邮件时进行以下错误处理: 如果出现序列化错误:在DLT中发送消息 我拥有的(2.5.1Kafka客户端的Spring kafka 2.5.5版本)如下: 现在,如果我发送不可序列化的消息,我的消息将不重试地发送到DLT- 在我的中,我有一个,捕获并重新捕获。 我应该没有重试,但我得到了2个重试,每个20秒(而不是10秒?),并在2次重试后向DLT发送了一条消息。 如果我删除errorH
-
基于Spring批处理和AMQP的分布式批处理
我想分散加工大批量。这个想法是使用Spring Batch在云中激发一堆AMQP消费者,然后加载廉价的任务(如项目ID)并将它们提交给AMQP交换。结果的书写将由消费者自己完成。 null