《hive》专题
-
 Hive面试题-1
Hive面试题-1主要内容:1.Hive的特点,2.Hive与RDBMS对比,3.Hive的优缺点,4.Hive的架构,5.Hive 底层与数据库交互原理,6.Hive 的 HSQL 转换为 MapReduce 的过程,7.Hive 的两张表关联,使用 MapReduce 怎么实现,8.hive 中 split、coalesce 及 collect_list 函数的用法,9.Hive保存元数据方式1.Hive的特点 hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提
-
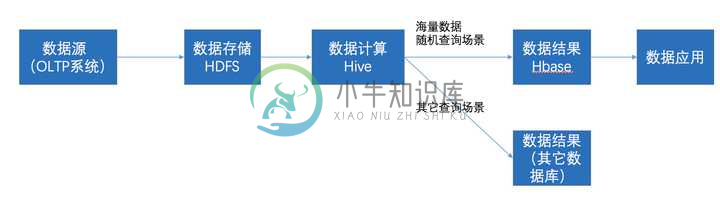 Hive与HBase的区别与联系
Hive与HBase的区别与联系主要内容:1.二者区别,2.二者联系1.二者区别 hive: Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能。 Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。hive需要用到hdfs存储文件,需要用到MapReduce计算框架。 hive可以认为是map-reduce的一个包装。hive的意义就是把好写的hi
-
Hive基本操作
主要内容:1.创建数据库,2.查看数据库,3.切换数据库,4.删除数据库,5.创建表,6.查看所有表,7.查看表信息,8.查看拓展描述信息,9.删除表,10.表加载数据,11.查看数据Hive 用户接口主要有三个:命令行(CLI),客户端(Client) 和 Web界面(WUI)。其中最常用的是 CLI,启动的时候,会同时启动一个 Hive 服务。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点
-
 Hive理论概述
Hive理论概述主要内容:1.Hive,2.Hive和Hadoop,3.Hive和Mysql,4.Hive基本知识1.Hive 2.Hive和Hadoop 越往后延迟越低,越往上算法越多 需要对Hadoop了解 以及对Hadoop的基本操作 3.Hive和Mysql Mysql用于存储数据,Hive用于数据仓库 数据仓库是什么,数据仓库和数据库的区别。 3.1 数据仓库 将原来的数据进行抽取出来,然后集成起来就成为了数据仓库 数据仓库不可以更新和删除 数据仓库是用作查询的 数据仓库的数据谁随着时间的变化产生的
-
hive-third-functions
hive-third-functions是一个hive udf库,包含各类hive udf库,尤其是array,map的各类函数。是hive自带udf函数的有效补充。 1.字符串函数 函数 说明 pinyin(string) -> string 将中文转换为拼音 md5(string) -> string md5 哈希 sha256(string) -> string sha256 哈希 2. 数
-
HiveMQ
HiveMQ 是一个企业级的 MQTT 代理,主要用于企业和新兴的机器到机器M2M通讯和内部传输,最大程度的满足可伸缩性、易管理和安全特性。提供免费的个人版。HiveMQ 提供了开源的插件开发包。
-
HiveMind
HiveMind是一个服务(services)和配置(configuration)的微内核。 服务:HiveMind的服务由一系列容易访问和组合的普通Java对象组成(Plain Old Java Objects)。每一个服务最好用一个被它实现了的接口进行定义(但是HiveMind现在并不强制这点)。在需要的时候HiveMind会负责实例化 每一个服务并且进行必要的配置。另外,HiveMind可以
-
Apache Hive
Apache Hive(TM)数据仓库软件有助于使用SQL读取,写入和管理驻留在分布式存储中的大型数据集。建立在Apache Hadoop(TM)之上,它提供: 通过SQL轻松访问数据的工具,从而实现数据仓库任务,例如提取/转换/加载(ETL),报告和数据分析 一种将结构强加于各种数据格式的机制 访问直接存储在Apache HDFS(TM)或其他数据存储系统(例如Apache HBase(TM))
-
Apache Hivemall
Hivemall 是一个可扩展的机器学习算法工具,可在 Apache Hive、Apache Spark 和 Apache Pig 上运行。 Hivemall 基于 Hive UDF,在工业实践应用中非常方便,方便数据科学家快速构建机器学习模型原型。 项目状态:目前为 Apache 孵化项目,支持列表如下: Binary Classification Metrics Multi-label Cla
-
ensembl-hive
eHive eHive is a system for running computation pipelines on distributed computing resources - clusters, farms or grids. The name comes from the way pipelines are processed by a swarm of autonomous ag
-
hive-dwrf
hive-dwrf 是作为 Apache Hive 项目一部分的 ORC 文件格式的分支。
-
X-Hive/DB
X-Hive/DB是一个为需要高级XML数据处理和存储功能的软件开发者设计的强大的专属XML数据库。X-Hive/DB Java API包含存储、查询、检索、转换和发表XML数据的方法。 本文转自91now资源站 www.91now.com
-
Hive Rise
Hive Rise 是一款新概念的大型网络即时战略游戏,每位玩家需要为了保卫自己或者占领其他玩家的六边形土地而拼搏,这也是名字蜂巢的来源:由海量六边形格子组成的世 界。该游戏支持 Linux 平台,并且免费。近日它的联盟系统结束 Beta 测试状态,标志着游戏系统进入了一个成熟的阶段。 Hive Rise 具有以下特点: 快节奏即时战略 支持上千玩家同场竞技 巨大的地图 具有一定的战术内涵 可以和
-
Hive-IO-Experimental
Hive-IO-Experimental 是一个 Hive 输入输出库。 Hive-IO-Experimental 提供了一个良好的用户界面来建立Hive 工程,而不需要用户通过直接修改或连接 HQL 命令行的形式来建立Hive 工程 现有的功能如下: 1. Simple APIs to read and write a table in a single process. 2. Hadoop c
-
Hive HA
hive让大数据飞了起来,不再需要专人写MR。平常我们都可以用基于thrift的任意语言来调用hive。 不过爱恨各半,hive的thrift不稳定也是出了名的。很容易就出问题,让人无计可施。唯一的办法就是不断kill,不断restart。当然,我们可以用haproxy来解决这个问题,关键,haproxy不管hive是否逻辑可用,不能执行逻辑的hive也“死马当活马”。当然,搞的好的可以用 zoo