《flink》专题
-
在Apache Flink中,处理时间窗口对有限数据源不起作用
我假设所有元素将在不到一秒的时间内生成,并进入一个窗口,因此中将有一个传入元素。然而,当我运行这个时,没有任何东西被打印出来。 如果我把窗户上的东西都拆了,就像 我看到运行后打印的元素。我也尝试了这个与文件源,没有区别。 更新#1,23.09.2018: 我还试验了事件时间窗口,而不是处理时间窗口。如果我这样做: 再一次,什么也没有打印出来。调试器显示触发器的会为每个元素调用,但从未被调用。
-
如何在Flink中打印聚合数据流?
我有一个表示为的自定义状态计算,当我的看到来自Kafka的新事件时,它将不断更新。现在,每次更新状态时,我都希望将更新后的状态打印到stdout。想知道怎么在Flink中做到这一点吗?与所有的窗口和触发器操作很少混淆,我一直得到以下错误。 我只想知道如何将我的聚合流打印到stdout或写回另一个kafka主题? 下面是引发错误的代码片段。
-
Flink中KeyedBroadcastProcessFunction的键控状态是如何管理的?
我正在使用在Flink中执行流计算。我为我的作业定义了一个扩展的类。假设我有一个通过键控的流a,和一个流B,它被广播给所有执行程序,以使用我定义的类处理a中的元素。我知道我可以在这个类的或中注册一个计时器,这样当它超时时,我可以通过调用来删除特定密钥组的关联状态。之后我在想,这个重点群体还存在吗? 例如,在流A中,一个新消息带有,我们生成了这样的密钥组及其关联状态。之后,如果出现另一个带有的消息,
-
如何在Flink中实现键控窗口超时?
我对流中的事件进行了键控,我希望通过键来累积,直到超时(例如,5分钟),然后处理累积到该点的事件(忽略该键之后的所有内容,但首先是第一件事)。 我是一个新的Flink,但从概念上来说,我认为我需要一些类似下面代码的东西。 如何在Flink中完成键控窗口超时?
-
如何在Flink Java API中获取keyBy()后的数据流键
我如何获得我之前指定的密钥?我没有在累加器中注入输入事件的键,因为我觉得我不会很好。
-
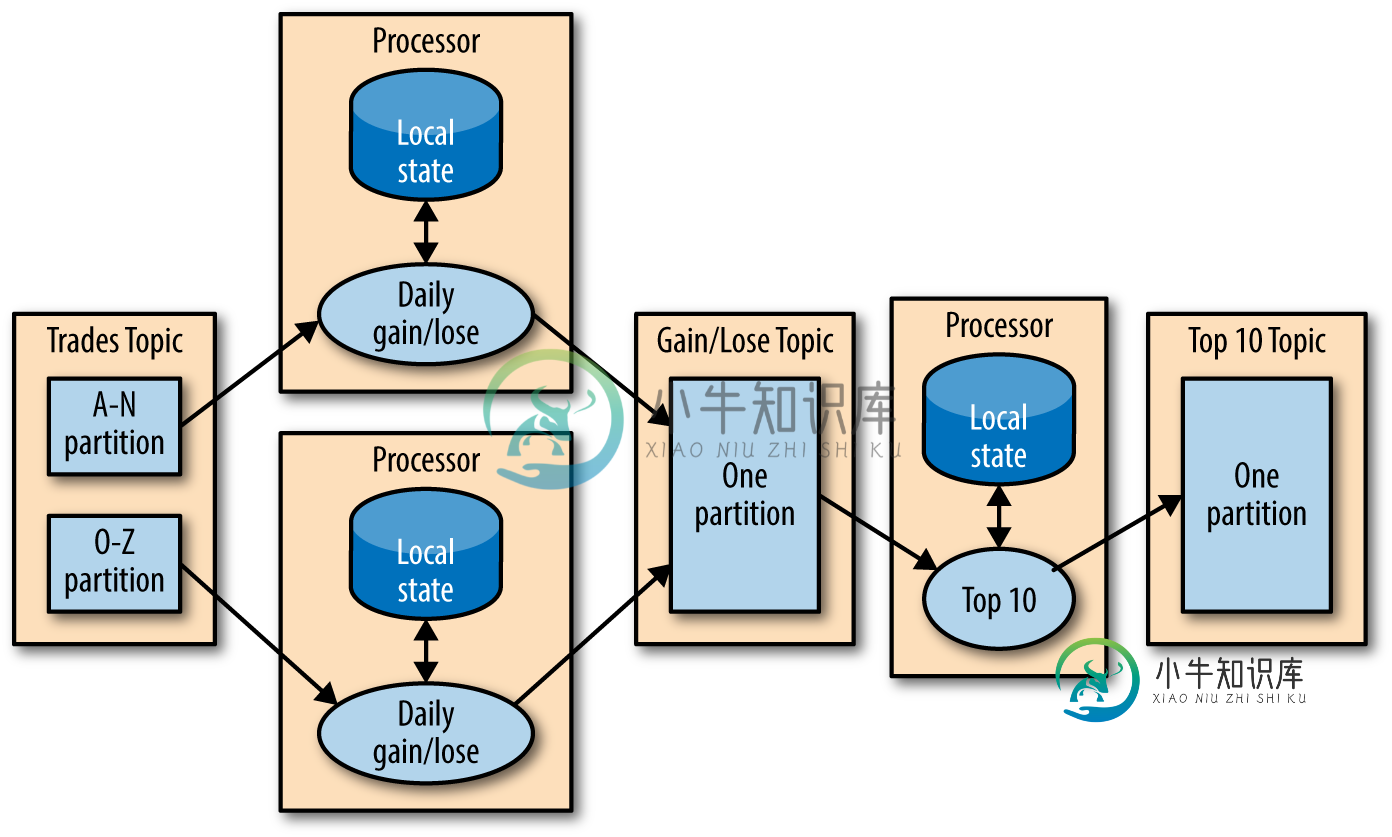 Apache Flink State Store vs Kafka Streams
Apache Flink State Store vs Kafka Streams据我所知,处理Kafka流会在内存、光盘或Kafka主题中本地显示其状态,因为所有的输入数据都来自一个分区,其中所有的消息都是由一个定义的值键控的。大多数时候,计算可以在不知道其他处理器状态的情况下完成。如果是,则有另一个Streams实例来计算结果。就像这张图: Flink的状态到底存储在哪里?Flink是否也可以在本地存储状态,还是总是将它们发布到所有实例(任务)?是否可以配置Flink,使其
-
Apache Flink窗口允许的无限延迟
我有以下用例,如果有明显的解决方案,很抱歉,但我对Flink非常陌生: 谢谢
-
Apache Flink动态添加新流
在我的情况下,有可能,例如,一个新的设备被启动,因此必须处理另一个流。但是如何动态添加这个新流呢?
-
如何在Flink流中执行空窗口上的函数?
-
如何在Flink中将avro文件写入S3?
我想从kafka主题中读取流数据,并以avro或parquet格式写入S3。数据流看起来像是json字符串,但我无法以avro或parquet格式转换并写入S3。 val stream=env.AddSource(myConsumerSource).AddSink(sink) 请帮忙,谢谢!
-
来自KAFKA KRB5 Kerberos问题的FLINK流
我正在尝试使用https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kafka.html从flink kafkaconsumer流式传输数据 在这里,我的KAFKA是Kerberos安全的,并且启用了SSL。 我该如何解决这件事?有没有别的办法通过KRB5?
-
Flink Kafka connector 0.10.0事件时间澄清和ProcessFunction澄清
我正纠结于一个关于Flink的Kafka的消费者连接器的事件时间的问题。引用Flink doc 自从Apache Kafka 0.10+以来,Kafka的消息可以携带时间戳,指示事件发生的时间(参见Apache Flink中的“事件时间”)或消息被写入Kafka代理的时间。 Kafka消费者不会发出水印。 一些问题和问题浮现在我的脑海中: > 我如何知道它的时间戳是发生的时间还是写给Kafka经纪
-
Flink流式事件时间窗口排序
输入: 结果:
-
Flink应用程序抛出类在Java中找不到异常
我有一个带有Yarn的Flink集群,使用flink-quickstart-java原型构建一个演示项目。在使用'mvn clean package-pbuild-jar'命令构建fat-jar之后,并使用'flink run-m yar-cluster-yn2./flink-Snapshot-1.0.jar'提交程序,程序会抛出以下异常: 下面是我的演示: 和一些版本信息: FLink版本:1.
-
Flink作业在第二次提交后崩溃