《HDFS》专题
-
如何从Kafka读取JSON数据并使用Spark结构化流存储到HDFS?
我正在尝试从Kafka读取JSON消息并将它们存储在具有火花结构化流的HDFS中。 我遵循了下面的示例,当我的代码如下所示时: 然后我得到hdfs中具有二进制值的行。 这些行按预期连续写入,但采用二进制格式。 我发现了这个帖子: https://databricks.com/blog/2017/04/26/processing-data-in-apache-kafka-with-structure
-
 Hive为HDFS中的每个插入创建多个小文件
Hive为HDFS中的每个插入创建多个小文件以下是已经实现的 Kafka制作人使用Spark流媒体从推特上获取数据 Kafka消费者将数据摄取到Hive外部表(在HDFS上) 虽然到目前为止这一切都很顺利。我只面临一个问题,当我的应用程序将数据插入配置单元表时,它创建了一个小文件,每个文件的每一行都有数据。 下面是代码 配置单元演示表已填充了一条记录。Kafka consumer循环处理每一行中topic=“topic\u twitter”
-
处理Spark Streaming rdd并存储到单个HDFS文件
> 我正在使用Kafka Spark流媒体来获取流媒体数据。 我正在使用此数据流并处理RDD runConfigParser是一种JAVA方法,它解析文件并生成必须保存在HDFS中的输出。因此,多个节点将处理RDD并将输出写入一个HDFS文件。因为我想把这五个装进蜂箱。 我应该输出runConfigParser的结果并使用sc.parallze(输出)。保存ASTEXTFILE(path),以便所
-
使用spark streaming将每个Kafka消息保存在hdfs中
我正在使用火花流做分析。分析后,我必须将kafka消息保存在hdfs中。每个kafka消息都是一个xml文件。我不能使用,因为它会保存整个rdd。rdd的每个元素都是kafka消息(xml文件)。如何使用火花在hdfs中保存每个rdd元素(文件)。
-
如何转换传入的XML数据。使用flume将txt文件转换为Avro格式并保存到hdfs
xml数据进入文本文件。将flume和kafka吸入hdfs并将其保存。txt文件格式。 退出用例:xml文件正在通过Flume→kafka→Flume拦截器摄取(验证有效模式与否)-- 新的是: 我需要采取有效的kafka主题,需要编写自己的Flume拦截器将xml数据转换为avro格式并发送到→hdfs接收器(hdfs有效位置)最终输出需要为avro文件格式... 任何帮助都将不胜感激 提前感
-
Flume Kafka HDFS:拆分消息
我有以下Flume代理配置来读取来自kafka源的消息并将它们写回HDFS接收器 如果每个轮询周期只有一条kafka消息到达,则kafka消息内容是avro数据,并且正确地序列化为文件。 当两个kafka消息到达同一批次时,它们被分组在同一个HDFS文件上,因为avro消息包含两个模式数据,结果文件包含模式数据模式数据,导致它是无效的. avro文件。 如何拆分avro事件以将不同的kafka消息
-
Flume:目录到Avro->Avro到HDFS-传输后Avro无效
我让用户编写AVRO文件,我想使用Flume将所有这些文件移动到使用Flume的HDFS中。因此,我以后可以使用Hive或Pig来查询/分析数据。 在客户端上,我安装了水槽,并有一个SpoolDir源和AVRO接收器,如下所示: 在hadoop集群上,我有一个AVRO源和HDFS接收器: 问题是HDFS上的文件不是有效的AVRO文件!我正在使用色调UI检查文件是否是有效的AVRO文件。如果我将我在
-
在缓存中找不到Hdfs委派令牌-Spark应用程序中出错
我在Spark版本2.3.0中有一个简单的Spark流应用程序,它将每个处理批次的结果放在HDFS上。我的应用程序运行在部署模式客户端的Thread上,我使用的是kerberized hadoop集群(hadoop2.6.0-cdh5.9.3)。我在spark submit命令中设置了--principal和--keytab。 几天后,我的应用程序无法在HDFS上写入,因为缓存中缺少委托令牌。重新
-
在spark流上下文中将RDD写入HDFS
我有一个火花1.2.0的火花流环境,我从本地文件夹中检索数据,每次我发现一个新文件添加到文件夹中时,我都会执行一些转换。 为了对DStream数据执行分析,我必须将其转换为数组 然后,我使用获得的数据提取我想要的信息,并将其保存在HDFS上。 由于我真的需要使用Array操作数据,因此不可能使用(这将正常工作)在HDFS上保存数据,我必须保存RDD,但使用此先决条件,我终于有了名为part-000
-
在写入HDFS-hive时,如何控制Spark流中的行数和/或输出文件大小?
使用火花流读取和处理来自Kafka的消息并写入HDFS-Hive。由于我希望避免创建许多垃圾文件系统的小文件,我想知道是否有办法确保最小的文件大小,和/或强制在文件中输出行数最少的能力,超时除外。谢谢。
-
通过spark streaming或flume将Xml转换为Avro,从Kafka转换为hdfs
我想将xml文件转换为avro。数据将采用xml格式,并将首先触及Kafka主题。然后,我可以使用flume或spark streaming来摄取xml并将其转换为avro,然后将文件放在hdfs中。我有一个cloudera环境。 当avro文件到达hdfs时,我希望能够稍后将它们读入hive表。 我想知道做这件事最好的方法是什么?我尝试过自动模式转换,比如spark avro(这没有spark流
-
如何在不覆盖的情况下将Spark流输出写入HDFS
经过一些处理后,我得到了一个DStream[字符串,ArrayList[字符串]],所以当我使用saveAsTextFile将其写入hdfs时,每个批处理后它都会覆盖数据,所以如何通过附加到以前的结果来写入新结果 编辑:: 如果有人可以帮助我将输出转换为avro格式,然后写入HDFS并附加
-
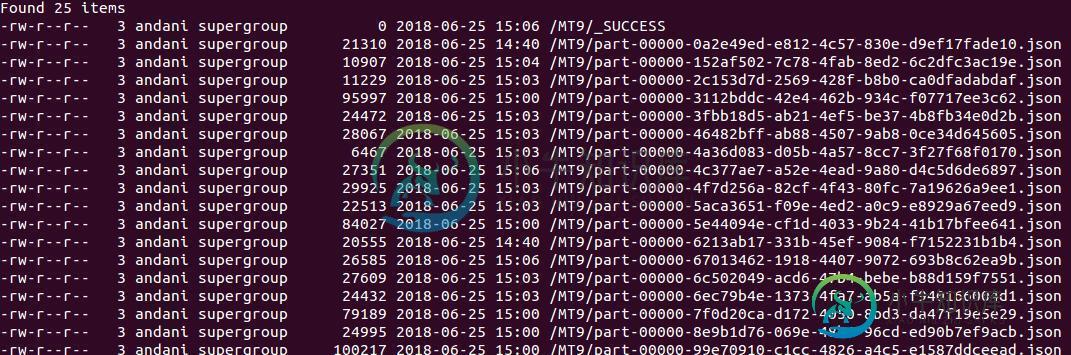 如何在HDFS中附加到相同的文件(火花2.11)
如何在HDFS中附加到相同的文件(火花2.11)我正在尝试使用SparkStreaming将流数据存储到HDFS中,但它会继续在新文件中创建附加到一个文件或几个多个文件中 如果它一直创建n个文件,我觉得效率不会很高 代码 在我的pom中,我使用了各自的依赖项: 火花-core_2.11 火花-sql_2.11 火花-streaming_2.11 火花流-kafka-0-10_2.11
-
将目录从本地系统复制到hdfs Java代码
问题内容: 尝试使用Java代码将目录从本地系统复制到HDFS时遇到问题。我能够移动单个文件,但无法找到一种移动带有子文件夹和文件的整个目录的方法。有人可以帮我吗?提前致谢。 问题答案: 只需使用的copyFromLocalFile方法即可。如果源路径是本地目录,它将被复制到HDFS目标:
-
请写出删除 hdfs 上的/tmp/aaa 目录的命令
本文向大家介绍请写出删除 hdfs 上的/tmp/aaa 目录的命令相关面试题,主要包含被问及请写出删除 hdfs 上的/tmp/aaa 目录的命令时的应答技巧和注意事项,需要的朋友参考一下 hadoop fs -rmr /tmp/aaa