《HDFS》专题
-
使用Java Api操作HDFS过程详解
本文向大家介绍使用Java Api操作HDFS过程详解,包括了使用Java Api操作HDFS过程详解的使用技巧和注意事项,需要的朋友参考一下 如题 我就是一个标题党 就是使用JavaApi操作HDFS,使用的是MAVEN,操作的环境是Linux 首先要配置好Maven环境,我使用的是已经有的仓库,如果你下载的jar包 速度慢,可以改变Maven 下载jar包的镜像站改为 阿里云。 贴一下 pom
-
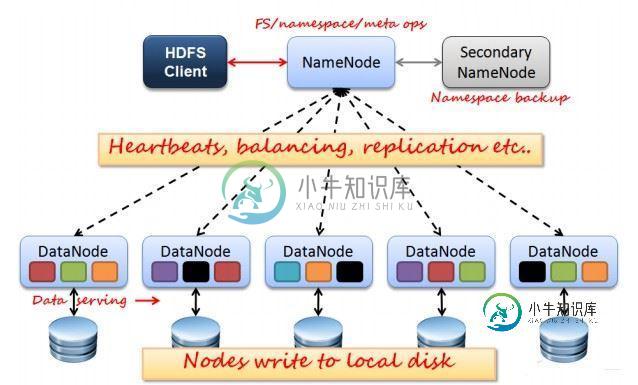 Hadoop 分布式存储系统 HDFS的实例详解
Hadoop 分布式存储系统 HDFS的实例详解本文向大家介绍Hadoop 分布式存储系统 HDFS的实例详解,包括了Hadoop 分布式存储系统 HDFS的实例详解的使用技巧和注意事项,需要的朋友参考一下 HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。 一、HDFS的优缺点 1.HDFS优点: a.高容错性 .数据保存多个副本 .数据丢的失后自动恢复
-
java 中Spark中将对象序列化存储到hdfs
本文向大家介绍java 中Spark中将对象序列化存储到hdfs,包括了java 中Spark中将对象序列化存储到hdfs的使用技巧和注意事项,需要的朋友参考一下 java 中Spark中将对象序列化存储到hdfs 摘要: Spark应用中经常会遇到这样一个需求: 需要将JAVA对象序列化并存储到HDFS, 尤其是利用MLlib计算出来的一些模型, 存储到hdfs以便模型可以反复利用. 下面的例子
-
Java访问Hadoop分布式文件系统HDFS的配置说明
本文向大家介绍Java访问Hadoop分布式文件系统HDFS的配置说明,包括了Java访问Hadoop分布式文件系统HDFS的配置说明的使用技巧和注意事项,需要的朋友参考一下 配置文件 m103替换为hdfs服务地址。 要利用Java客户端来存取HDFS上的文件,不得不说的是配置文件hadoop-0.20.2/conf/core-site.xml了,最初我就是在这里吃了大亏,所以我死活连不上HDF
-
Bosun 用Bash编写的Hadoop HDFS磁盘使用情况
本文向大家介绍Bosun 用Bash编写的Hadoop HDFS磁盘使用情况,包括了Bosun 用Bash编写的Hadoop HDFS磁盘使用情况的使用技巧和注意事项,需要的朋友参考一下 示例 这是一个连续的收集器,使用该hadoop fs -du -s /hbase/*命令来获取有关HDFS磁盘使用情况的详细信息。该度量对于跟踪OpenTSDB系统中的空间非常有用。
-
如何将文件从FTP服务器增量复制到Hadoop HDFS
我们有一个FTP服务器,每天都有很多文件上传到FTP服务器,我需要在HDFS中复制所有这些文件。 每次只应下载增量文件,即首次下载10个文件后,FTP上载了5个新文件;在作业的下一次迭代中,它应该只下载HDFS中的新5个文件。 我们没有使用Nifi或Kafka连接。 我们有什么好的解决方案来完成这项任务吗?
-
如何通过FTP下载Hadoop文件(在HDFS上)?
我想实现一个SSIS作业,该作业能够下载位于远程Hadoop集群上的大型CSV文件。当然,在Hadoop系统上只有一个常规FTP服务器不会公开HDFS文件,因为它使用本地文件系统。 我想知道是否有一个FTP服务器实现位于HDFS之上。我更喜欢这种方法,而不是必须将文件从HDFS复制到本地FS,然后让FTP服务器提供服务,因为我需要分配更多的存储空间。
-
 无法使用Hadoop Web UI在HDFS中打开/下载文件
无法使用Hadoop Web UI在HDFS中打开/下载文件我已经在外部RHEL服务器中配置了一个独立的单节点Hadoop环境。我正在尝试使用Hadoop Web UI查看HDFS中的文件:
-
使用Pig将HDFS数据存储到MongoDB中
我是Hadoop的新手,需要将Hadoop数据存储到MongoDB中。在这里,我使用Pig将Hadoop中的数据存储到MongoDB中。 在给定命令的帮助下,我在Pig Grunt shell中下载并注册了以下驱动程序, 在此之后,我使用以下命令成功地从MongoDB获取了数据。 然后,我尝试使用以下命令将数据从pig bag插入MongoDB,并获得成功。 然后我尝试使用下面的命令Mongo更新
-
hdfs和hbase之间的差异
我是Hadoop的新手。我正在浏览专业Hadoop解决方案的书,以获得一些关于Hadoop和生态系统的知识。我想澄清HDFS和HBase之间的主要区别是什么。我理解的方式就像两者都是存储系统。它们的区别只是在访问数据方面。HBase通过非关系型数据库访问数据,HDFS使用计算框架(MapReduce)处理数据。如果是这种情况,为什么我们不能只有一个存储HDFS或HBase。根据需求,他们将插入和插
-
在AzureSQL数据仓库中使用Polybase访问Hadoop(Azure IaaS)HDFS文件
我正在尝试使用Azure SQLDW中的Polybase访问Cloudera集群中HDFS中的分隔文件(在Azure中配置为IaaS),但遇到以下错误: Msg 105019,Level 16,State 1,Line 40 EXTERNAL TABLE access因内部错误而失败:“调用HdfsBridge\u IsDirExist时引发Java异常。Java异常消息:从DB55/10.0.0
-
如何通过Java API在Google云平台的HDFS中创建目录
我正在Google云平台上运行Hadoop集群,使用Google云存储作为持久数据的后端。我能够从远程机器ssh到主节点,并运行hadoop fs命令。无论如何,当我尝试执行以下代码时,我得到了一个超时错误。 密码 执行hdfs.exists()命令时,我得到一个超时错误。 错误 组织。阿帕奇。hadoop。网ConnectTimeoutException:来自gl051-win7/192的调用。
-
熊猫对HDFStore中的大数据进行“分组依据”查询?
问题内容: 我有大约700万行,其中有60列以上。数据超出了我的内存容量。我正在基于列“ A”的值将数据聚合到组中。熊猫拆分/汇总/合并的文档假定我已经将所有数据都存储在了,但是我无法将整个商店读取到内存中。在分组数据的正确方法是什么? 问题答案: 这是一个完整的例子。 输出量 一些警告: 1)如果您的组密度相对较低,则此方法很有意义。大约数百或数千个组。如果获得的收益更多,则效率更高(但方法更复
-
hdfs 安装或设置
本文向大家介绍hdfs 安装或设置,包括了hdfs 安装或设置的使用技巧和注意事项,需要的朋友参考一下 示例 有关设置或安装hdfs的详细说明。
-
写入hdfs时如何避免小文件问题
我在我的项目中使用spack-sql-2.3.1v、kafka和java8。与 在消费者方面,我尝试使用下面的代码在hdfs me中编写文件 当我存储到hdfs文件夹中时,它看起来像下面的东西,即每个文件都在1.5k即几个KB。 由于这个小文件,它需要大量的处理时间,而我从hdfs中读取更大的数据集 问题: > 如果我想计算给定hdfs文件夹中的记录总数,如何计算? 新更改后 运行成功结果包括: