
Hive为HDFS中的每个插入创建多个小文件

以下是已经实现的
- Kafka制作人使用Spark流媒体从推特上获取数据
- Kafka消费者将数据摄取到Hive外部表(在HDFS上)
虽然到目前为止这一切都很顺利。我只面临一个问题,当我的应用程序将数据插入配置单元表时,它创建了一个小文件,每个文件的每一行都有数据。
下面是代码
// Define which topics to read from
val topic = "topic_twitter"
val groupId = "group-1"
val consumer = KafkaConsumer(topic, groupId, "localhost:2181")
//Create SparkContext
val sparkContext = new SparkContext("local[2]", "KafkaConsumer")
//Create HiveContext
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sparkContext)
hiveContext.sql("CREATE EXTERNAL TABLE IF NOT EXISTS twitter_data (tweetId BIGINT, tweetText STRING, userName STRING, tweetTimeStamp STRING, userLang STRING)")
hiveContext.sql("CREATE EXTERNAL TABLE IF NOT EXISTS demo (foo STRING)")
配置单元演示表已填充了一条记录。Kafka consumer循环处理每一行中topic=“topic\u twitter”的数据,并填充到Hive表中
val hiveSql = "INSERT INTO TABLE twitter_data SELECT STACK( 1," +
tweetID +"," +
tweetText +"," +
userName +"," +
tweetTimeStamp +"," +
userLang + ") FROM demo limit 1"
hiveContext.sql(hiveSql)

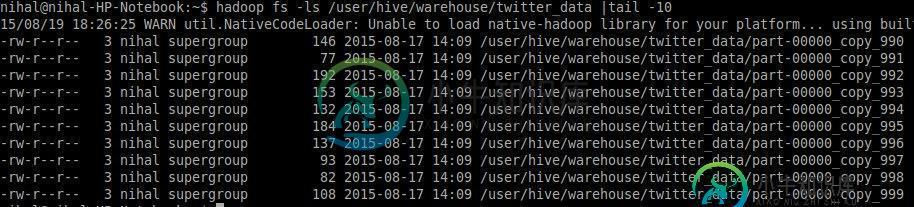
如您所见,文件大小不超过200KB,有没有办法将这些文件合并到一个文件中?
共有3个答案

您可以同时使用这些选项。
- 打开acid

Hive是为大规模批次处理作业而设计的,而不是为事务而设计的。这就是为什么每个LOAD或INSERT-SELECT命令至少有一个数据文件。这也是为什么您没有INSERT-VALUES命令,因此您的帖子中显示的蹩脚语法是必要的解决方法。
好在引入事务支持之前,情况一直如此。简而言之,您需要(a)Hive V0.14和更高版本(b)ORC表(c)在该表上启用事务支持(即锁、定期后台压缩等)
关于Hive中流式数据摄取的wiki可能是一个好的开始。

[采取2]好吧,所以你不能正确地将数据“流式传输”到Hive。但是你可以添加一个周期性的压缩后处理作业...
>
(角色='集合A')、(角色='集合B')、(角色='存档')(角色='activeA')(角色='activeB')然后将您在“A”分区中收集的每条记录转储到“存档”中,希望Hive默认配置能很好地限制碎片
INSERT INTO TABLE twitter\u data PARTITION(role='archive')选择。。。来自twitter\u数据,其中role='activeA';截断表twitter\u数据分区(role='activeA')
在某个时候,切换回“A”等。
最后一句话:如果Hive在每个压缩作业中仍然创建了太多的文件,那么在插入之前,尝试在会话中调整一些参数,例如。
set hive.merge.mapfiles =true;
set hive.merge.mapredfiles =true;
set hive.merge.smallfiles.avgsize=1024000000;
-
我是HDFS和Hive的新手。在阅读了一些书籍和文档之后,我得到了这两个方面的一些介绍。我有一个关于在HIVE中创建一个表的问题,该表的文件存在于HDFS中。我有这个文件在HDFS中有300个字段。我想在HDFS中创建一个访问该文件的表。但我想利用这个文件中的30个字段。我的问题是1。配置单元是否创建单独的文件目录?2.我必须先创建配置单元表,然后从HDFS导入数据吗?3.既然我想创建一个300列
-
问题内容: 在一些示例之后,似乎我们可以注入一个工厂,其中包含一个REST服务的终结点,如下所示 这看起来不错,但可以想象我还有其他端点,即/ users /:id和/ groups /:id,因为您可以想象到不同端点的数量将会增加。 因此,对于每个终结点,都有一个不同的工厂,这是一个好习惯。 还是有另一种推荐的方法? 我确实没有发现任何问题,但是它迫使我创建许多工厂来处理不同的端点。 确实需要任
-
我有一个包含呼叫数据记录的配置单元表。我在电话号码上对表进行了分区,并在CALL_DATE上对表进行了bucked处理。现在,当我在hive中插入数据时,过时的call_date会在我的bucket中创建小文件,这会创建名称、节点、元数据、增加和性能降低。有没有办法把这些小文件合二为一。
-
所以基本上我想创建一个包含csv文件的表
-
问题内容: 我必须在弹性中插入一个json数组。链接中可接受的答案建议在每个json条目之前插入标题行。答案是2岁,市场上是否有更好的解决方案?我需要手动编辑json文件吗? 问题答案: 好的,那么您可以使用简单的Shell脚本来完成一些非常简单的操作(请参见下文)。这个想法是不必手动编辑文件,而是让Python进行编辑并创建另一个文件格式符合端点期望的文件。它执行以下操作: 首先,我们声明一个小
-
我是java新手,我在VSCODE上编码。我创建2.java文件,如下图所示: 这些是每个文件: Main.java: