《HDFS》专题
-
1.3.6 Tensorflow中使用hdfs
简介 Tensorflow自1.0开始支持hdfs,Cloud-ML这边从tensorflow1.3开始全面支持hdfs 使用 参考tensorflow官方给出的文档:https://www.tensorflow.org/deploy/hadoop 生态云集群连接HDFS集群,具体集群的兼容性,请联系Cloud-ML工程师。
-
MinIO HDFS网关
MinIO HDFS网关将Amazon S3 API支持添加到Hadoop HDFS文件系统中。应用程序可以同时使用S3和文件API,而无需任何数据迁移。由于网关是无状态且无共享的,因此您可以弹性地分配所需数量的MinIO实例以分配负载。 运行MinIO Gateway进行HDFS存储 使用二进制 通过core-site.xml 自动从hadoop环境变量 $HADOOP_HOME 中读取来获取N
-
第8章 HDFS——Hadoop分布式文件系统
Hadoop分布式文件系统(HDFS)的设计主旨,在于对超大规模数据集提供可靠的存储功能,并对用户应用程序提供高带宽的输入输出数据流。在大型的集群里,上千台服务器均可直接参与到数据存储和应用程序任务执行。通过多服务器,分布式的存储和计算,计算资源的规模能够按照需要增长,并兼顾在各种规模上经济适用性。 本文主要描述了HDFS的架构,并以Yahoo!企业数据服务为例,介绍了如何使用HDFS系统管理高达
-
第8章 HDFS——Hadoop分布式文件系统之一
原文链接:http://www.aosabook.org/en/hdfs.html 作者:Robert Chansler, Hairong Kuang, Sanjay Radia, Konstantin Shvachko与Suresh Srinivas HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)的设计宗旨,是可靠地存储极大的数据集,并将其以
-
5.2.1.1.8-HDFS-快照操作
命令 功能 hdfs dfs -ls /foo/.snapshot 列出一个可快照目录下的所有快照 hdfs dfs -ls /foo/.snapshot/s0 列出快照s0的所有文件 hdfs dfs -cp -ptopax /foo/.snapshot/s0/bar /tmp 从快照s0拷贝一个文件,注意一下这个例子使用了保留选项来保留timestamps,ownership,permissi
-
5.2.1.1.7-HDFS-缓存
命令 功能 示例 addDirective 增加一个新的缓存指令 hdfs cacheadmin -addDirective -path -pool removeDirective 移除一个缓存指令 hdfs cacheadmin-removeDirective removeDirectives 移除路径列表中所有的缓存指令 hdfs cacheadmin-removeDirectives lis
-
5.2.1.1.5-HDFS-JAVA-API
Overview (Apache Hadoop Main 2.6.0 API).html
-
5.2.1.1.4-HDFS-命令行
HDFS为用户提供了类似本地文件系统的文件和目录操作。 用户命令,通过hdfs dfs命令查看。表1列出了常用的用户命令,包括文件和目录的创建、查看、删除、移动、重命名、设置副本数以及从本地上传下载、和HDFS中文件的合并。 表1 常用用户命令 命令 功能 示例 appendToFile 将本地追加写如hdfs文件 hdfs dfs -appendToFile localfile hdfsfile
-
5.2.1.1.3-HDFS-扩容
1.1 修改hdfs-site.xml配置文件 1.2 重启 datanode 服务 1.3 查看存储量 hdfsadmin dfs -report
-
5.2.1.1.2-HDFS-调研
1.1 Hadoop简介 2005年,Lucene 的创始人 Doug Cutting 主持开发完成了首款支持海量数据存储计算的分布式开源框架—Hadoop。Hadoop的初始定位是服务于大量的具有廉价硬件设备的服务器,且对存储的数据具有较高的容错性,随着 Hadoop功能的逐步完善,目前 Hadoop已经晋升为 Apache的顶级项目。Hadoop框架主要包括 Hadoop分布式文件系统(HDF
-
5.2.1.1.1-HDFS-安装
采用最简配置进行安装。 1. yum 安装 1.1 安装组件 yum install hadoop-hdfs-namenode # 在将要运行 NameNode 的节点上安装。 yum install hadoop-hdfs-datanode # 在将要运行 DataNode 的节点上安装。 1.2 修改配置文件 使用 yum 安装的 cdh 版本 hdfs 配置文件在 /etc/hadoop/
-
 Hadoop分布式文件系统HDFS的工作原理详述
Hadoop分布式文件系统HDFS的工作原理详述Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。要理解HDFS的内部工作原理,首先要理解什么是分布式文件系统。 1.分布式文件系统 多台计算机联网协同工作(有时也称为一个集群)就像单台系统一样解决某种问题,这样的系统我们称之为分布式系统。 分布
-
 HDFS理论概述
HDFS理论概述主要内容:1.分布式存储,2.HDFS结构,3.HDFS体系结构,4.HDFS文件存储的特点以及局限性,5.HDFS数据处理原理总结1.分布式存储 1.1.集群和分布式 1.2.计算机集群结构 1.3.分布式文件系统结构 2.HDFS结构 HDFS存储通过块来存储 默认为64M 2.1 NameNode 2.2 NameNode HDFS 节点结构 2.3 SecondNameNode 2.4 DataNode 2.5 DataNode HDFS结构 3.HDFS体系结构 总结 4.HDFS文件
-
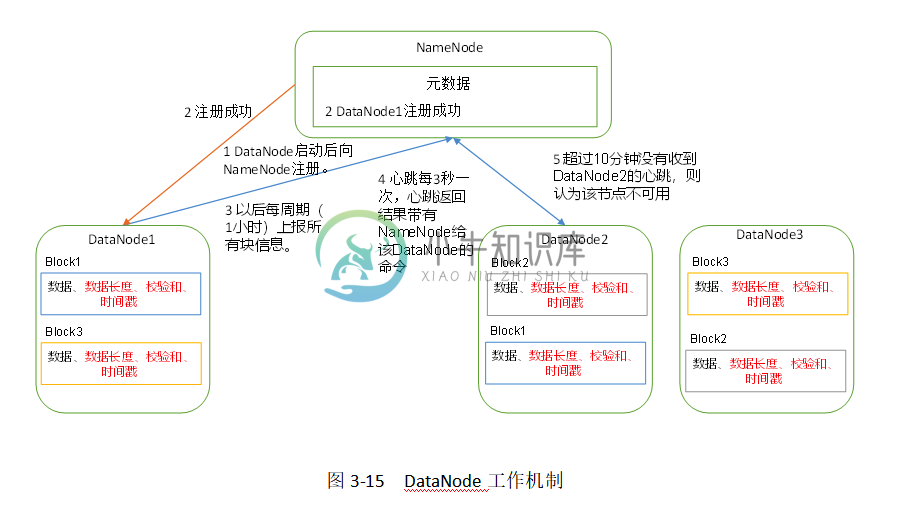 HDFS详解③
HDFS详解③主要内容:6 DataNode(面试开发重点)6 DataNode(面试开发重点) 6.1 DataNode工作机制 DataNode工作机制,如图3-15所示。 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。 2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。 3)心跳是每3秒一次
-
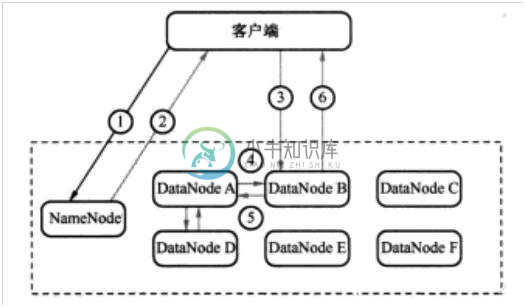
 HDFS详解②
HDFS详解②主要内容:4 HDFS的数据流,5 NameNode和SecondaryNameNode(面试开发重点)4 HDFS的数据流 4.1 HDFS写数据流程 4.1.1 剖析文件写入 HDFS写数据流程 1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。 2)NameNode返回是否可以上传。 3)客户端请求第一个 Block上传到哪几个DataNode服务器上。 4)NameNode返回3个Data