《字节》专题
-
将IPV4地址从字节转换为字符串
我目前正在尝试创建一个聊天服务器作为一个分配,并希望每个消息包含一个头。它将包含ipv4地址,后跟一个字母,然后是用户名 我可以很容易地从字节中解码字符串字母,但现在我很难从字节中解码ipv4地址 我只需要一种方法来尝试和解码四个字节的整数到一个字符串或一些沿这些线的东西 谢谢:D
-
哈希字符串的字节转换,java vs python
我对将纯java Curve25519函数转换为Python等效函数存在问题,具体问题与将哈希字符串转换为字节等效函数的摘要函数有关,java实现: 数据示例: sP=“这是一个用于测试目的的密码短语示例” 生成此字节输出: 82, -57, 124, 58, -105, 76, 123, 3, 119, -21, 121, 71, -54, 73, -75, 54, 31, -33, -49,
-
MQTT Kafka源连接器:有趣的字节字符
mqttpublisher.py mqttsubscriber.py py ConsumerRecord(Topic='mqtt.',partition=0,offset=225,timestamp=1545117270870,timestamp_type=0,key=b'\x00\x00\x00\x01\x16sensor/dist“,value=b'\x00\x00\x00\x00\x01\x
-
字节缓冲到Java中的字符串[重复]
我有这行代码 其中缓冲区是字节缓冲区。 有没有一种方法可以在不分配新字符串和/或复制字符数组的情况下将字节缓冲符转换为字符串?(也就是说,有没有办法将字符串的char[]值安全地指向字节缓冲区的byte[]hb?) 谢谢
-
将证书字符串转换为字节数组
-
C#字节数组到字符串数组[重复]
-
如何将字符串转换为字节数组?
我得到一个错误读数:
-
 字节 字节云 测试开发 面经 社招
字节 字节云 测试开发 面经 社招部门:字节云 岗位:测试开发 社招 3年 有点紧张 流程 1自我介绍 2你未来岗位有啥要求?(给我问懵逼了)为啥想要离职? 3以下问题偏测试(没问项目,可能项目差异太大了) 如何提升产品质量之类 你负责的产品质量怎么样 自动化有啥好处? 4编程语言python 你知道哪些类型 dict是怎么实现的 5做一个SQL题,大概用子查询吧 6编程题,最长回文子串 7你的优势,劣势 许愿,梦想还是
-
从字符串中删除非字母数字字符
问题内容: 我想将以下字符串转换为提供的输出。 我还没有发现,将处理特殊字符,如任何解决方案,,,等。 基本上,我只是想摆脱所有不是字母数字的东西。这是我尝试过的… 尝试多个步骤 结果 任何帮助,将不胜感激。 工作解决方案: 问题答案: 删除非字母数字字符 以下是/正确的正则表达式,用于从输入字符串中去除非字母数字字符: 请注意,这等效于-它包括下划线字符。要删除下划线,请使用例如: 输入格式错误
-
Python,将4字节字符转换为避免MySQL错误“错误的字符串值:”
问题内容: 我需要将(4个字节)的char转换为其他字符(在Python中)。这是将其插入到我的utf-8 mysql数据库中,而不会出现诸如以下的错误:“不正确的字符串值:行1的’行’的’\ xF0 \ x9F \ x94 \ x8E’ 通过向mysql插入4字节的unicode引发的警告显示了这样做的方法: 但是,在注释“ …错误的字符范围..”中,我得到与用户相同的错误,这显然是因为我的Py
-
如何将字符串数据从用户作为字节数组写入套接字
我有一个类,它接收用户发送的消息并在终端上打印出来,但现在我正在尝试编写一个类,从用户那里读取数据,将来自用户的字符串数据转换成字节数组,并将字节数组写入套接字。 我试图使用BufferedReader从用户读取数据,并使用OutputStream将字节数组写入套接字,但由于某些原因,我正在写入套接字的消息没有传递到服务器。 是一个与我发送到的服务器和端口号相同的套接字! 当我运行这个时没有错误,
-
了解Java字节
问题内容: 因此,在昨天的工作中,我不得不编写一个应用程序来计算AFP文件中的页数。因此,我整理了我的MO:DCA规范PDF,找到了结构化字段及其3个字节的标识符。该应用程序需要在AIX机器上运行,所以我决定用Java编写它。 为了获得最大效率,我决定读取每个结构化字段的前6个字节,然后跳过该字段中的其余字节。这会让我: 因此,我检查字段类型,如果是,则增加页面计数器,如果不是,则不增加。然后,我
-
Concat字节数组
问题内容: 有人可以指出以下更有效的版本吗 每个变量都是一个字节片,大小不一 : 码: : 基准测试结果: 问题答案: 如果已经分配了内存,则x = append(x,a …)的序列在Go中非常有效。 在您的示例中,初始分配(制造)的成本可能比附加序列的成本高。这取决于字段的大小。考虑以下基准: 在我的盒子上,结果是: 系统地重新分配缓冲区(甚至是很小的缓冲区)会使此基准测试速度至少慢5倍。 因此
-
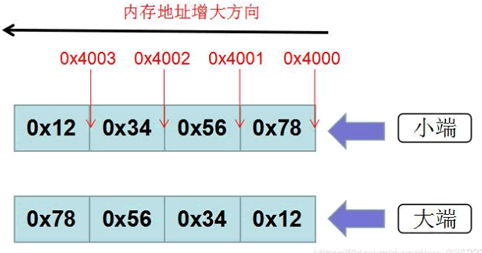 NumPy字节交换
NumPy字节交换主要内容:numpy.ndarray.byteswap()数据以字节的形式存储在计算机内存中,而存储规则可分为两类,即小端字节序与大端字节序。 小端字节序(little-endian),表示低位字节排放在内存的低地址端,高位字节排放在高地址段,它与大端字节序(big-endian)恰好相反。 对于二进制数 0x12345678,假设从地址 0x4000 开始存放,在大端和小端模式下,它们的字节排列顺序,如下所示: 图1:字节存储模式 小端存储后:0x
-
比较字节值?
问题内容: 我很好奇为什么,当我将一个数组与一个值进行比较时… …返回,而… …才不是?是一个数组 问题答案: 比较整数,因为0xFF是整数,此表达式 会将您的字节 扩展为int并将括号内的内容与第二int进行比较。至于你说的是,它将首先被调整为整数且相比于整数,所以这个作品。 将一个字节与int比较: 是一个字节(有符号),其值为。 不等于,因此这就是为什么在比较integer之前必须将data