《分类》专题
-
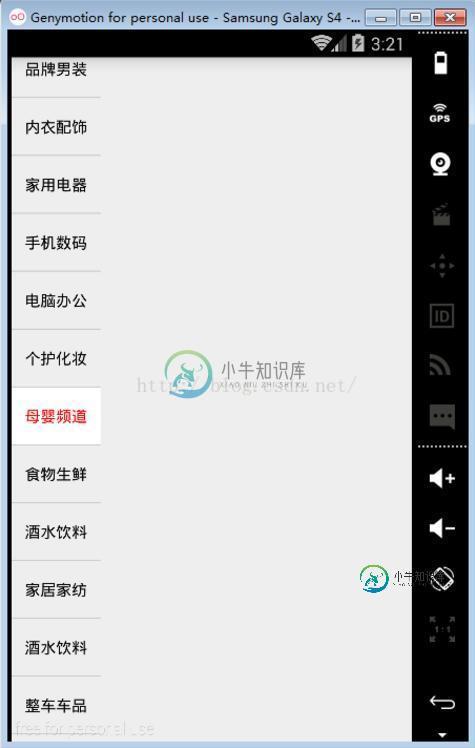 Android仿京东分类模块左侧分类条目效果
Android仿京东分类模块左侧分类条目效果本文向大家介绍Android仿京东分类模块左侧分类条目效果,包括了Android仿京东分类模块左侧分类条目效果的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Android仿京东左侧分类条目效果的具体代码,供大家参考,具体内容如下 代码2: 代码3: 效果图: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
分析文档分类培训文件时发生OpenNLP错误
我正在尝试使用opennlp处理文档分类器。但是我对训练文件有困难。当opennlp读取文件时,我收到以下错误: 我的培训文件如下所示: 我没有得到我可能错过的东西。
-
第9章 案例分析:图像聚类 - 9.4 性能分析
为了展示不同的内核实现对于性能的影响,我们将这些内核都在Radeon HD 7970 GPU上执行了一遍。为了展示对不同数据大小的性能优化,我们也生成除了对应的SURF描述符和集群质心。生成的SURF描述符数量为4096,16384和65536。同时,对应质心的数量为16,64和256。我们选取数量较大的SURF特征,是因为对于一张高分辨率的图来说,通常都包含成千上万个特征。不过,对于质心来说其数
-
CART 分类回归树算法 Cart 算法分类回归树
CART分类回归树算法 与上次文章中提到的ID3算法和C4.5算法类似,CART算法也是一种决策树分类算法。CART分类回归树算法的本质也是对数据进行分类的,最终数据的表现形式也是以树形的模式展现的,与ID3,C4.5算法不同的是,他的分类标准所采用的算法不同了。下面列出了其中的一些不同之处: 1、CART最后形成的树是一个二叉树,每个节点会分成2个节点,左孩子节点和右孩子节点,而在ID3和C4.
-
DisplayTag分页与休眠分页
问题内容: 显示标签提供给定对象的分页功能。Hibernates提供了仅提取每页所需记录的选项。在我的项目中,我们同时使用了这两个概念。 显示广告代码:我需要根据过滤条件提取所有记录并将其存储在会话中。然后这个displaytag将负责所有分页和排序。因此Httpsession拥有很多数据。 hibernate:它仅从数据库中获取请求的对象数,无需为每个请求打开会话。 最好的做事方法是什么?或者如
-
Kafka分区分配的概念?
本文向大家介绍Kafka分区分配的概念?相关面试题,主要包含被问及Kafka分区分配的概念?时的应答技巧和注意事项,需要的朋友参考一下 一个topic多个分区,一个消费者组多个消费者,故需要将分区分配个消费者(roundrobin、range)
-
Hive 分区表和分桶表
一、分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。 分区为 HDFS 上表目录的子目录,数据按照分区存储在子目录中。如果查询的 where 字句的中包含分区条件,则直接从该分区去查找,而不是扫描整个表目录,合理的分区设计可以极大提高查询速度和性能。 这里说明一下分区表并 Hive 独有的概念,实际上这个概念
-
降维 - PCA(主成分分析)
1 主成分分析原理 主成分分析是最常用的一种降维方法。我们首先考虑一个问题:对于正交矩阵空间中的样本点,如何用一个超平面对所有样本进行恰当的表达。容易想到,如果这样的超平面存在,那么他大概应该具有下面的性质。 最近重构性:样本点到超平面的距离都足够近 最大可分性:样本点在这个超平面上的投影尽可能分开 基于最近重构性和最大可分性,能分别得到主成分分析的两种等价推导。 1.1 最近重构性
-
分库分表中间件 ShardingSphere
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(计划中)这 3 款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。 架构 Sharding-JDBC 定位为轻量级 J
-
Python中的主成分分析
问题内容: 我想使用主成分分析(PCA)进行降维。是否已经有numpy或scipy,或者我必须使用自己滚动? 我不只是想使用奇异值分解(SVD),因为我的输入数据具有很高的维数(约460个维数),因此我认为SVD比计算协方差矩阵的特征向量要慢。 我希望找到一个预制的,已调试的实现,该实现已经对何时使用哪种方法以及哪些可能进行的其他优化进行了正确的决策,而这些优化我都不知道。 问题答案: 您可以看看
-
不可分裂的分裂器
我试图了解是如何工作的,以及拆分器是如何设计的。我认识到可能是更重要的方法之一,但是当我看到一些第三方实现时,有时我看到他们的拆分器无条件地为返回null。 问题: 普通迭代器和无条件返回null的拆分器有何不同?这样的分裂者似乎违背了分裂的目的
-
快速排序:分区分析
我正在学习快速排序在第四算法课程,罗伯特塞奇威克。 我想知道quicksort代码的以下分区是长度为n的数组中比较的个数。
-
整数个分区的分区
整数n的划分是将n写成正整数和的一种方式。对于 例如,对于n=7,一个分区是1 1 5。我需要一个程序来查找所有 使用“r”整数对整数“n”进行分区。例如,
-
分库分表合并迁移
本文介绍了 DM 提供的分库分表的合并迁移功能,此功能可用于将上游 MySQL/MariaDB 实例中结构相同/不同的表迁移到下游 TiDB 的同一个表中。DM 不仅支持迁移上游的 DML 数据,也支持协调迁移多个上游分表的 DDL 表结构变更。 简介 DM 支持对上游多个分表的数据合并迁移到 TiDB 的一个表中,在迁移过程中需要协调各个分表的 DDL,以及该 DDL 前后的 DML。针对用户的
-
Zebra 分库分表 API 介绍
zebra API是针对分库分表场景(ShardDataSource),提供的一套可以通过手动指定一些路由参数 的方式来改变zebra默认路由行为的API。通过API,用户可以手动指定SQL本身以外的列 或值 来实现将SQL路由到任意用户想要路由的表上。 zebra API依靠ShardDataSourceHelper类提供的static接口,来实现相关的功能。 zebra API功能有哪些 ze