《集群》专题
-
集合操作 - 集合交集
sinter key1 key2...keyN 返回所有给定key的交集 sinterstore dstkey key1...keyN 同sinter,但是会同时将交集存到dstkey下
-
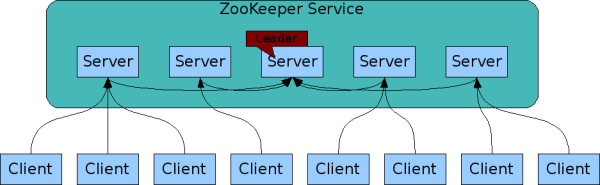 ZooKeeper 集群 ?
ZooKeeper 集群 ?本文向大家介绍ZooKeeper 集群 ?相关面试题,主要包含被问及ZooKeeper 集群 ?时的应答技巧和注意事项,需要的朋友参考一下 为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。ZooKeeper 官方提供的架构
-
Cluster (集群)
稳定性: 2 - 稳定的 一个单一的 Node.js 实例运行在一个单独的线程上。 为了利用多核系统,用户有时会想启动一个 Node.js 进程的集群去处理负载。 cluster 模块可以轻松地创建一些共享服务器端口的子进程。 const cluster = require('cluster'); const http = require('http'); const numCPUs = requ
-
Redis 集群
Redis 集群(Redis Cluster) 是 Redis 提供的分布式数据库方案。 既然是分布式,自然具备分布式系统的基本特性:可扩展、高可用、一致性。 Redis 集群通过划分 hash 槽来分片,进行数据分享。 Redis 集群采用主从模型,提供复制和故障转移功能,来保证 Redis 集群的高可用。 根据 CAP 理论,Consistency、Availability、Partition
-
1.7.5.1 集群
{ "name": "...", "type": "...", "connect_timeout_ms": "...", "per_connection_buffer_limit_bytes": "...", "lb_type": "...", "ring_hash_lb_config": "{...}", "hosts": [], "service_name":
-
1.2.7 集群
1.简介 为了避免单点故障,现在的应用通常至少会部署在两台服务器上。对于一些负载比较高的服务,会部署更多的服务器。这样,在同一环境下的服务提供者数量会大于1。对于服务消费者来说,同一环境下出现了多个服务提供者。这时会出现一个问题,服务消费者需要决定选择哪个服务提供者进行调用。另外服务调用失败时的处理措施也是需要考虑的,是重试呢,还是抛出异常,亦或是只打印异常等。为了处理这些问题,Dubbo 定义了
-
集群(Cluster)
K-means clustering是一种在一组未标记数据中查找聚类和聚类中心的方法。 直觉上,我们可能会认为一个聚类是由一组数据点组成的,它们的点间距离与到聚类外部点的距离相比较小。 给定一组初始的K中心,K-means算法迭代以下两个步骤 - 对于每个中心,识别比其更靠近它的训练点子集(其簇)比任何其他中心。 计算每个聚类中数据点的每个特征的平均值,并且该平均向量成为该聚类的新中心。 迭代这两
-
采集帮助 - 使用采集 - 图片集采集
-
操作etcd集群 - 搭建etcd集群
注:内容翻译自 Clustering Guide 概述 启动 etcd 集群要求每个成员知道集群中的其他成员。在一些场景中,集群成员的 IP 地址可能无法提前知道。在这种情况下,etcd 集群可以在发现服务的帮助下启动。 一旦 etcd 集群启动并运行,通过 运行时重配置 来添加或者移除成员。为了更好的理解运行时重配置背后的设计,建议阅读 运行时重配置的设计。 这份指南将覆盖下列用于启动 etcd
-
集群部署 - NFS 下集群安装
Seafile 集群中,各seafile服务器节点之间数据共享的一个常用方法是使用NFS共享存储。在NFS上共享的对象应该只是文件,这里提供了一个关于如何共享和共享什么的教程。 如何配置NFS服务器和客户端超出了本wiki的范围,提供以下参考文献: Ubuntu: https://help.ubuntu.com/community/SettingUpNFSHowTo CentOS: http://
-
Redis集群等待集群加入Private VPC
我有3个使用Redis运行的EC2实例,如下所示: 服务器001:10.0.1.203,端口:6379 服务器002:10.0.1.202,端口:6380 服务器003:10.0.1.190,端口:6381 每个配置文件: 我可以通过redis连接到每台服务器上的每一台。 但是,当我运行集群创建时,脚本永远不会在服务器001上结束。 服务器002日志: 服务器003日志: 配置中缺少什么?
-
KeyCloak与mysql-InnoDB集群的独立集成
正在尝试让Keyclope与mysql innodb群集配合使用。我已经单独配置了Keyclope。xml符合文档要求。 这是数据源 这是司机 我还添加了module.xml打包mysql jdbc驱动程序(我使用最新版本mysql-connector-java-8.0.21.jar) 运行keydrope时出现的错误是 这方面的任何帮助都会非常有用。
-
Elasticsearch集群'master_not_discovered_exception'
问题内容: 我已经安装了Elasticsearch 2.2.3并在2个节点的集群中进行了配置 节点1(elasticsearch.yml) 节点2(elasticsearch.yml) 如果我知道我有: 进入节点1的日志有: 改为进入节点2的日志: 哪里出错? 问题答案: 我解决了这一行: 每个配置文件的主机名都必须带有此行
-
Elasticsearch集群API
此API用于获取有关集群及其节点的信息,并对其进行更改。 对于调用此API,需要指定节点名称,地址或。 例如, 或者 响应 集群运行状况 此API用于通过追加关键字来获取集群运行状况的状态。 例如, 响应 集群状态 此API用于通过附加’‘关键字URL来获取有关集群的状态信息。状态信息包含:版本,主节点,其他节点,路由表,元数据和块。 例如, 响应 群集统计信息 此API有助于使用’‘关键字检索有
-
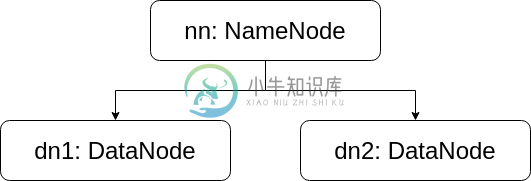 5.0 HDFS 集群
5.0 HDFS 集群主要内容:部署集群HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。 使用 Docker 可以更加方便地、高效地构建出一个集群环境。 每台计算机中的配置 Hadoop 如何配置集群、不同的计算机里又应该有怎样的配置,这些问题是在学习中产生的。本章的配置中将会提供一个典型的示例,但 Hadoop 复