《集群》专题
-
Java 8流收集集
为了更好地理解新的流API,我试图转换一些旧代码,但我被困在这一个。 我似乎无法为它创建有效的收集器:
-
Docker1.12 Worker无法加入集群(集群:待定)
问题内容: 管理员版本, 工人版本。 创建了Swarm管理器: 然后创建工人 我已经检查了工人的日志 在中,我看到了“虫群:待定” 我也做到了!尽管如此,该工作人员仍无法加入集群。所以,我该怎么爱 更新1 卸载并删除配置文件,然后再次安装docker 1.12版本。 仍然面临着相同的问题(无法加入和中的“ Swarm:Pending” ),其中存在DIFFERENT错误 谢谢。 问题答案: 问题是
-
HornetQ集群嵌入时使用JBoss集群吗?
我将使用嵌入在 JBoss EAP 6.2 中的 HornetQ 2.3.12,并且需要一些集群队列。 我是否需要设置 JBoss 集群才能让 JMS 集群由大黄蜂 Q 提供支持,或者大黄蜂 Q 是独立的?根据文档,我认为是后者,因为大黄蜂Q集群是大黄蜂Q的一部分,可以在没有JBoss的情况下存在。 节点通过核心网桥连接,因此部署在每个节点中的应用程序将对队列名称执行本地 JNDI 查找,而无需集
-
为已有 TiDB 集群部署异构集群
本文档介绍如何为已有的 TiDB 集群部署一个异构集群。 前置条件 已经存在一个 TiDB 集群,可以参考 在标准 Kubernetes 上部署 TiDB 集群进行部署。 部署异构集群 什么是异构集群 异构集群是给已经存在的 TiDB 集群创建差异化的实例节点,比如创建不同配置不同 Label 的 TiKV 集群用于热点调度或者创建不同配置的 TiDB 集群分别用于 TP 和 AP 查询。 创建一
-
集群部署 - 可扩展高可用集群
本文档提供一个可扩展、高可用的 Seafile 集群架构。这种架构主要是面向较大规模的集群环境,可以通过增加更多的服务器来提升服务性能。如果您只需要高可用特性,请参考3节点高可用集群文档。 架构" class="reference-link"> 架构 Seafile集群方案采用了3层架构: 负载均衡层:将接入的流量分配到 seafile 服务器上。并且可以通过部署多个负载均衡器来实现高可用。 Se
-
集群部署 - 3节点高可用集群
本文档介绍用 3 台服务器构建 Seafile 高可用集群的架构。这里介绍的架构仅能实现“服务高可用”,而不能支持通过扩展更多的节点来提升服务性能。如果您需要“可扩展 + 高可用”的方案,请参考Seafile 可扩展集群文档。 在这种高可用架构中包含3个主要的系统部件: Seafile 服务器:提供 Seafile 服务的软件 MariaDB 数据库集群:保存小部分的 Seafile 元数据,比如
-
如何从另一个集群 Pod 连接 kubernetes 集群上的 mongo 副本集
我有一个在kubernetes集群(在AWS EKS上)上运行的mongo db副本集,比如集群-1。这在具有cidr的VPC-1中运行192.174.0.0/16. 我在一个单独的VPC中有另一个集群,比如VPC-2,在那里我将在mongo集群之上运行一些应用程序。该VPC cidr范围为192.176.0.0/16。所有VPC对等和安全组入口/出口规则都正常工作,我能够跨两个VPC ping集
-
Kubernetes集群上运行的Spark独立集群的Hadoop集群Kerberos身份验证
我已经在Kubernetes上建立了Spark独立集群,并试图连接到Kubernetes上没有的Kerberized Hadoop集群。我已经将core-site.xml和hdfs-site.xml放在Spark集群的容器中,并相应地设置了HADOOP_CONF_DIR。我能够成功地在Spark容器中为访问Hadoop集群的principal生成kerberos凭据缓存。但是当我运行spark-s
-
采集帮助 - 了解采集 - 采集流程
采集流程: 采集一般可以分为3个过程:1.设置采集规则;2.采集数据内容;3.导出内容,这3个内容是可以独立分开来的。 设置采集规则:这个就是在操作中的添加采集节点,并对这个节点规则进行设置,比如:设置采集内容列表的地址、指定采集标题或者内容的位置(规则)、设置采集内容过滤规则。这个规则是采集最根本最基础的东西,采集规则可以导入导出,方便对这个采集规则进行分享。 采集数据内容:根据不同情况对数据采
-
采集帮助 - 了解采集 - 关于采集
关于采集: 什么是采集呢?我们可以这样理解,我们打开一个网站,看到有一篇文章很不错,于是将文章的标题和内容复制,然后将这篇文章转到我们的网站上,这个过程就可以称作采集,将别人网站上对自己有用的信息转到自己网站上。 采集器也是这样,不过整个过程是由电脑来完成的,我们复制人家的标题和内容,是在知道什么地方是内容,什么地方是标题前提下进行操作的,但电脑是不知道的,所以我们要告诉电脑怎么识别怎么采,这就是
-
在Kubernetes集群上运行自动集成测试
我的团队开发了一个kubernetes集群。我们已经使用< code>kubectl命令行对其进行了手动测试。这些测试用例涉及到,例如: < li >豆荚 < li >服务、负载平衡器等。 < li >部署 < li >水平窗格缩放 < li >回滚部署 < li >入口控制器 Helm-kubernetes的包装经理 < li >持久性卷和持久性卷声明。 < li>DNS 上述手动测试用例的链接
-
空结果集的集合
问题内容: 我希望将空结果集的总计设置为0。我尝试了以下方法: 结果: 子问题:上面的工作在Oracle中行不通吗? 问题答案: 在有关聚合函数的文档页面中: 应该注意的是,除了这些函数, 当没有选择任何行时 ,这些函数将 返回空值 。特别是,没有行返回空值,而不是预期的零值。必要时,该函数可用于将零替换为null。 所以,如果你想保证返回的值,适用于 结果 的,而不是它的参数: 至于Oracle
-
列表子集的子集
在R中,我有一个列表,由12个子列表组成,每个子列表本身由5个子发布者组成,如下所示 列表和子列表 在本例中,我想为每个子列表提取信息“MSD”。 我可以提取每种使用方法的级别“统计信息” 这很有效。它给了我子列表“statistics”中包含的所有值,但是,对于每个列表,我想向下一级,因为我对其他数据(如MSerror、Df等)不感兴趣。。。。。只有MSD 我试过了 还有许多人没有成功。 如果我
-
JS实现的集合去重,交集,并集,差集功能示例
本文向大家介绍JS实现的集合去重,交集,并集,差集功能示例,包括了JS实现的集合去重,交集,并集,差集功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS实现的集合去重,交集,并集,差集功能。分享给大家供大家参考,具体如下: 1. js 实现数组的集合运算 为了方便测试我们这里使用nodejs,代码如set_operation.js 2. 测试 我们这里使用nodejs来测试 测试
-
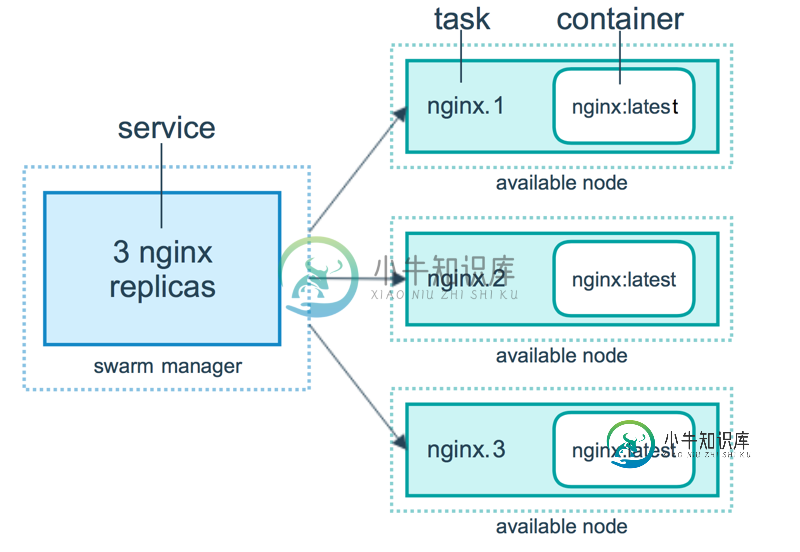 Swarm 集群管理
Swarm 集群管理主要内容:使用简介 Docker Swarm 是 Docker 的集群管理工具。它将 Docker 主机池转变为单个虚拟 Docker 主机。 Docker Swarm 提供了标准的 Docker API,所有任何已经与 Docker 守护程序通信的工具都可以使用 Swarm 轻松地扩展到多个主机。 支持的工具包括但不限于以下各项: Dokku Docker Compose Docker Machine Jen