《监控》专题
-
ap.onPageResume 监听 pageResume 事件
ap.onPageResume(CALLBACK) 当一个页面重新可见时(仅指从下个页面回退),会触发此事件。 如果这个页面通过 popWindow/popTo 到达时传递了 data 参数,此页可以获取到 data。 CALLBACK 参数说明 名称 类型 描述 data Object 通过 popWindow/popTo 传递的 data 参数 代码示例 <script src="https:
-
ap.onPause 监听 pause 事件
ap.onPause(CALLBACK) 当一个页面不可见时,会触发此事件。包括下面两种情况: 被压入后台和锁屏,触发 appPause 的同时会触发此事件。 通过 pushWindow 打开下个页面,当前页面触发 pagePause 的同时会触发此事件。 代码示例 <script src="https://gw.alipayobjects.com/as/g/h5-lib/alipayjsapi/
-
ap.onResume 监听 resume 事件
ap.onResume(CALLBACK) 当一个页面重新可见时,会触发此事件,包括下列两种情况: 从后台被唤起和锁屏界面恢复,触发 appResume 的同时会触发此事件。 通过 popWindow/popTo 从下个页面回退,触发 pageResume 的同时会触发此事件。 此外,如果这个页面是通过 popWindow/popTo 到达,且传递了 data 参数,此页可以获取到 data。 C
-
异常数据监测
1,极值分析 通过scatterplots,histogramas, box和whisker plot分析极值。 查看样本分布(假设高斯分布),去距离1/4和3/4值2-3倍标准差数值的样本。 2,临近方法 基于k-means分析样本质心,去掉离质心特别远的样本。 3,投影方法 通过PCA,SOM,sammon mapping去掉不重要特征。
-
7-SpringBoot事件监听
当一个bean处理完后需要另一个bean继续处理,那么就需要一个bean监听另一个bean 7.1 事件流程 自定义事件:一般是继承ApplicationEvent抽象类 定义事件监听器:一般是实现ApplicationListener接口 启动的时候把监听器加入到spring容器中 发布事件 package com.clsaa.edu.springboot; import org.spri
-
攻击监测预警
分析展示所有安装网防G01服务器产生的日志,以及对网络攻击、入侵行为、内网疑似被控主机的分析结果。 监测日志 攻击分析 入侵分析 监测日志 监测日志,用于记录安装网防G01的服务器遭受网络攻击的情况和服务器自身的行为记录,日志包括:SQL注入漏洞、 Struts2漏洞、 Java反序列化漏洞、 RDP暴力破解、 SSH暴力破解、进程创建行为、进程联网行为、可疑进程创建可执行文件、 黑名单进程执行危
-
第14章 监视Squid
14.1 cache.log告警 在碰到Squid有问题时,应该首先查看cache.log里的警告信息。在正常运行时,你可发现不同的警告或信息,它们会或不会表明问题存在。我在13.1节里讲到了cache.log的结构。这里我重提一些可能在日志文件里见到的警告信息。 在中值响应时间超过限制时,high_response_time_warning指令让Squid打印一条警告。该值是毫秒级的,默认禁止。
-
4.4. 无监督降维
校验者: @程威 翻译者: @十四号 如果你的特征数量很多, 在监督步骤之前, 可以通过无监督的步骤来减少特征. 很多的 无监督学习 方法实现了一个名为 transform 的方法, 它可以用来降低维度. 下面我们将讨论大量使用这种模式的两个具体示例. 4.4.1. PCA: 主成份分析 decomposition.PCA 寻找能够捕捉原始特征的差异的特征的组合. 请参阅 分解成分中的信号(矩阵分
-
2. 无监督学习
2.1. 高斯混合模型 2.1.1. 高斯混合 2.1.1.1. 优缺点 GaussianMixture 2.1.1.1.1. 优点 2.1.1.1.2. 缺点 2.1.1.2. 选择经典高斯混合模型中分量的个数 2.1.1.3. 估计算法期望最大化(EM) 2.1.2. 变分贝叶斯高斯混合 2.1.2.1. 估计算法: 变分推断(variational inference) 2.1.2.1.1.
-
1.14. 半监督学习
校验者: @STAN,废柴0.1 翻译者: @那伊抹微笑 半监督学习 适用于在训练数据上的一些样本数据没有贴上标签的情况。 sklearn.semi_supervised 中的半监督估计, 能够利用这些附加的未标记数据来更好地捕获底层数据分布的形状,并将其更好地类推到新的样本。 当我们有非常少量的已标签化的点和大量的未标签化的点时,这些算法表现均良好。 <cite>y</cite> 中含有未标记的
-
3 无监督学习
聚类和降维:K-Means 聚类,层次聚类,主成分分析(PCA),奇异值分解(SVD)。 我们可以怎样发现一个数据集的底层结构?我们可以怎样最有用地对其进行归纳和分组?我们可以怎样以一种压缩格式有效地表征数据?这都是无监督学习的目标,之所以称之为「无监督」,是因为这是从无标签的数据开始学习的。 我们将在这里探索的两种无监督学习任务是:1)将数据按相似度聚类(clustering)成不同的分组;2)
-
2.3 监督学习 III
非参数化模型:KNN、决策树和随机森林。包含交叉验证、超参数调优和集成模型。 非参数学习器 事情变得有点...扭曲了。 我们目前为止涉及的方法,线性回归,对率回归和 SVM ,它们的模型形式是预定义的。与之相反,非参数学习器事先没有特定的模型结构。在训练模型之前,我们不会推测我们尝试习得的函数f的形式,就像之前的线性回归那样。反之,模型结构纯粹由数据定义。 这些模型对于训练数据的形状更加灵活,但是
-
2.2 监督学习 II
使用对数几率回归(LR)和支持向量机(SVM)的分类。 分类:预测标签 这个邮件是不是垃圾邮件?贷款者能否偿还它们的贷款?用户是否会点击广告?你的 Fackbook 照片中那个人是谁? 分类预测离散的目标标签Y。分类是一种问题,将新的观测值分配给它们最有可能属于的类,基于从带标签的训练集中构建的模型。 你的分类的准确性取决于所选的算法的有效性,你应用它的方式,以及你有多少有用的训练数据。 对数几率
-
监听设备消息
只有监听设备消息后,在就收到消息数据才会返回消息内容,否则,不返回接收的消息内容。 请求方式: "|4|2|2|\r" 返回值: "|4|2|2|1|\r" 监听成功 Arduino样例: softSerial.print("|4|2|2|\r");
-
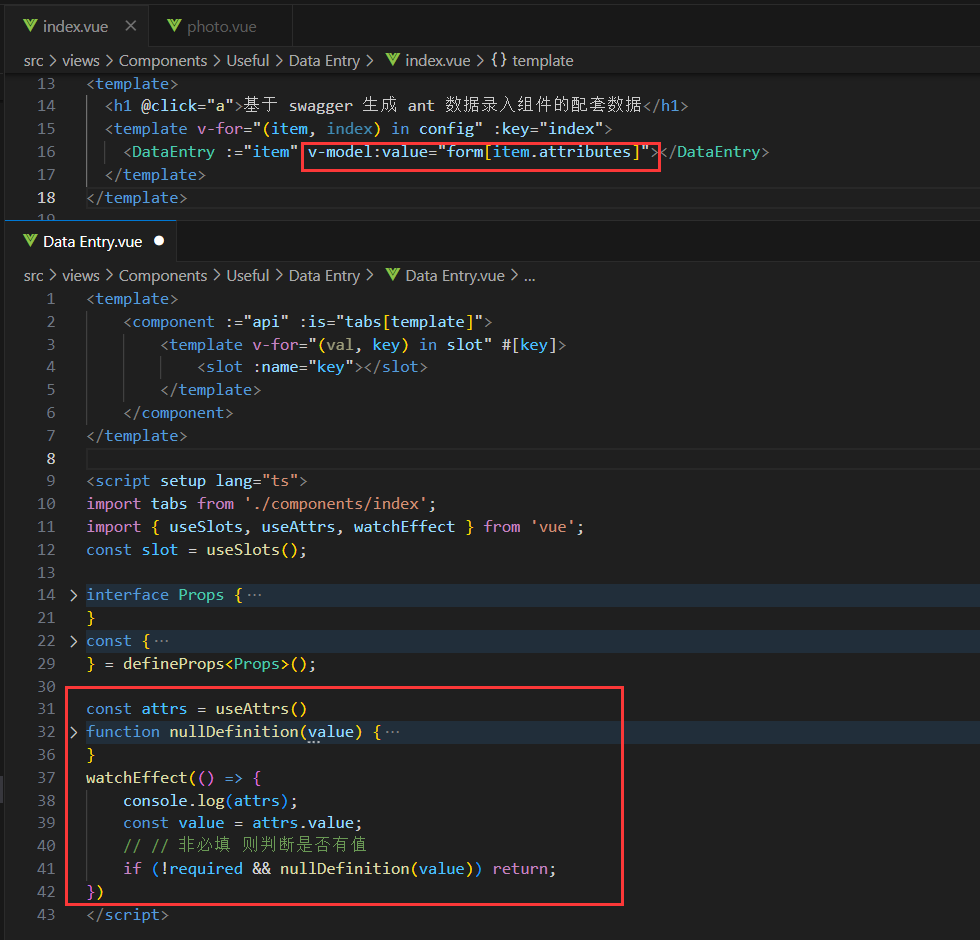 vue3 - watchEffect监听规则?
vue3 - watchEffect监听规则?这是为什么,应该是独立的嘛,怎么全部的监听器都触发了。 如何修改呢? 剥离出来也不行。