《kafka》专题
-
Spark2 Kafka结构化流媒体Java不知道from_json功能
我有一个关于Kafka流上的Spark结构化流的问题。 我有一个模式类型: 我从Kafka主题引导我的流,如下所示: 接下来转换为字符串,字符串类型: 现在我想将value字段(这是一个JSON)转换为之前转换的模式,这将使SQL查询更容易: 看来Spark 2.3.1不知道函数? 这是我的进口: 有没有办法解决这个问题?请注意,我不是在寻找Scala解决方案,而是一个纯粹的基于Java的解决方案
-
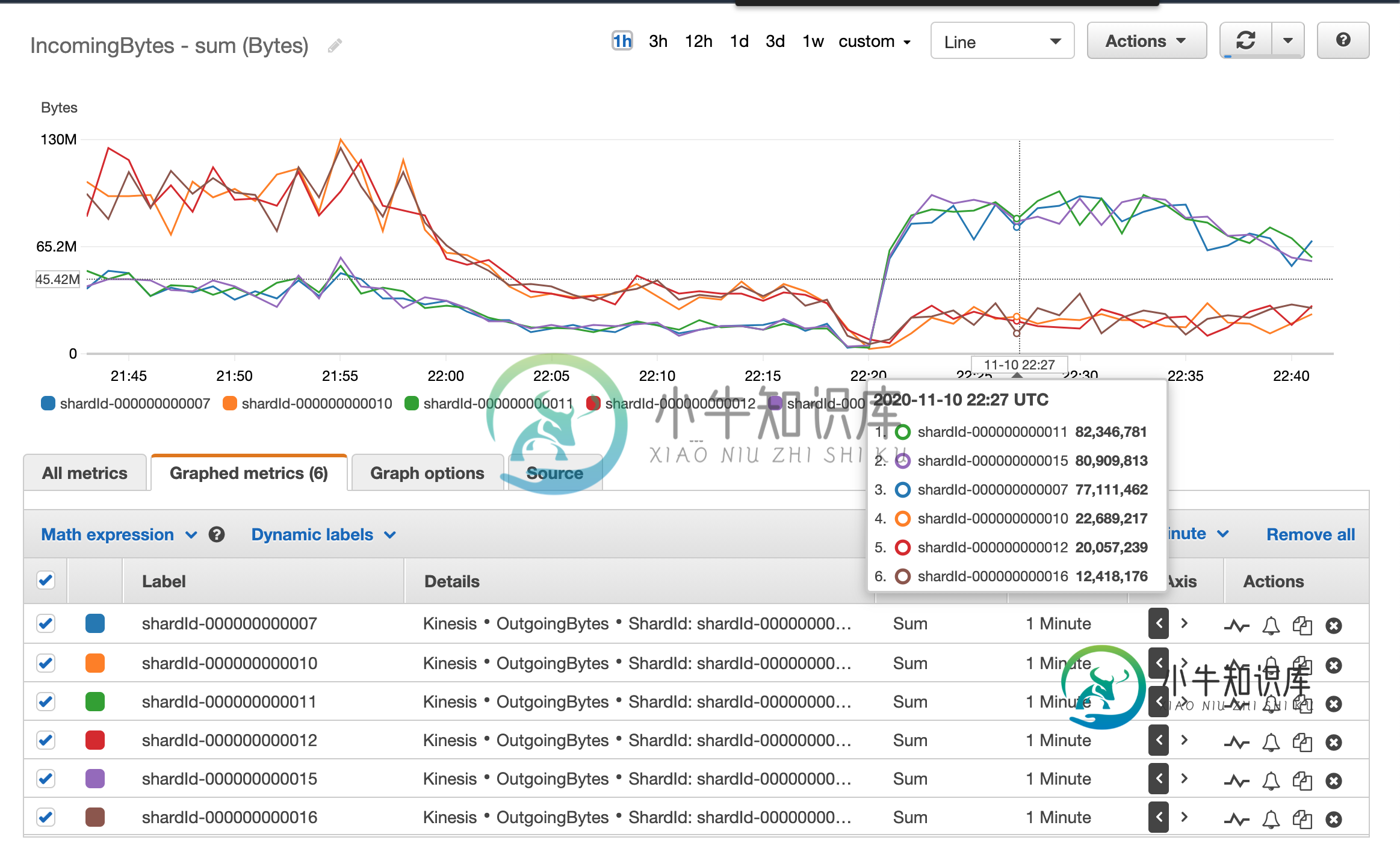 Kafka消费者如何以相似的速度从不同的分区读取数据?
Kafka消费者如何以相似的速度从不同的分区读取数据?在处理Spark结构化流和Kinesis流时,我在重新处理流中积累的数据时遇到了不平衡读取(与读取最新数据相反)。 下一个图表显示了作为流一部分的kinesis片段的读取速度差异。 这使得spark jobs丢弃了很多事件,因为事件时间非常不同的事件会被混淆,而那些认为旧的事件会被丢弃。 最近一位团队成员建议改用Kafka。我对Apache Kafka解决这个问题有点怀疑,因为AFAIK修复我上面
-
如何停止Spring Kafka Listner并调用一些函数在消费者停止后执行?
我有一个场景,我需要停止kafka并调用一些函数在消费者停止后执行。同样,flow是这样的: 消费来自kafka主题的消息 将每个消耗的消息添加到文件中 停止kafka监听器,如果它在过去10秒内没有收到任何消息 为Ex调用一些函数:UploadFileToS3() 我在我的消费者方法中使用了spring kafka的@KafkaListener注释。 我知道停止使用@KafkaListener注
-
在Spring kafka消费者启动后运行一次方法
我有一个使用Spring kafka库的Spring启动应用程序的消费者。我想为每个消费者线程设置租户上下文,即在创建每个线程时调用一个方法(创建时每个线程只调用一次)。目前,我已将其添加到listner中,其中对方法有@KafkaListner注释,但它每次轮询并处理每条记录时都会调用它。我想在消费者线程启动时调用此方法一次。如果我们有任何这样的事情,请在这里帮助我。
-
如何使用Spring-Kafka实现消费者线程安全
我正在使用Spring boot2.1.7。RELEASE和spring-kafka 2.2.7。RELEASE。我正在使用@KafkaListener注释来创建一个消费者,我正在使用消费者的所有默认设置。 这是我的消费者配置: 由于某些原因,我在同一个应用程序中有多个使用者,如下所示。 尽管如此,根据关于“消费者线程安全”的合流文件 一个线程中不能有多个属于同一组的使用者,也不能有多个线程安全地
-
显式启动Kafka消费者在主后方法运行
我有一个spring boot服务,它使用Kafka主题。当我消费时,我会对Kafka信息执行某些任务。在执行这些操作之前,我需要等待服务将一些数据加载到我设置的缓存中。我的问题是,如果我将kafka consumer设置为autostart,它将在缓存加载并出错之前开始使用。 我试图在加载缓存后显式启动使用者,但却出现空指针异常。 Kafka利斯泰纳 要启动和停止的服务 主要方法 以下是例外情况
-
如何配置频率Kafka消费者投票在sping-kafka
我试图在我的spring boot项目中使用spring kafka来阅读来自我的kafka的消息。我正在使用@KafkaListener,但问题是我的消费者总是在运行。只要我从控制台生成一条消息,它就会在我的应用程序中弹出。我想定期投票。我怎样才能做到这一点? } 这是我的消费者配置:
-
在启动Spring kafka-消费者之前运行一个方法
谁能建议在spring启动其kafka消费者之前如何运行初始化我的应用程序的方法?我正在使用spring的@KafkaListener注释创建一个kafka消费者
-
Scala spark kafka代码函数方法
下面是Scala中的代码。我正在使用spark sql从hadoop中提取数据,对结果执行一些分组,序列化它,然后将消息写给Kafka。 我已经写了代码--但我想用函数的方式来写。我是否应该创建一个具有“get categories”函数的新类来从Hadoop中获取类别?我不知道如何处理这件事。 这是代码 提前谢谢你,苏约格
-
Kafka用户挂起的提取永远不会被删除,轮询保持返回0条记录
我们已经写了一个Kafka消费者投票的数据,基于配置…每个轮询返回大约400条我们缓冲的avro记录。在缓冲区之后,我们在端部偏移上进行查找。当缓冲区大小达到2000时,我们使用执行服务线程将它们写入HDFS,然后使用future.get等待全部完成。我们一直在HDFS(staging folder)中追加相同的文件,直到提交大小达到10K。在达到提交大小之后,我们将文件从staging目录移动到
-
Kafka消费者停止消费消息
我有一个简单的Kafka设置。生成器正在以较高的速率向单个分区生成具有单个主题的消息。单个使用者正在使用来自此分区的消息。在此过程中,使用者可能会多次暂停处理消息。停顿可以持续几分钟。生产者停止产生消息后,所有排队的消息都将由使用者处理。生产者产生的消息似乎不会立即被消费者看到。我使用的是Kafka0.10.1.0。这里会发生什么?下面是使用消息的代码部分: 代理上的所有配置都保留为kafka默认
-
无法使用JDBCSinkConnector将Kafka主题中的数据加载到Postgres
我已经把Kafka和博士后的成绩记录下来了。我使用JDBC接收器连接器将数据从Kafka主题加载到Postgres表。首先,我用“AVRO”值格式创建一个主题和一个主题上方的流。 以下是创建接收器连接器的代码: 然后,我使用命令检查Postgres是否有来自Kafka的数据,它返回以下信息:
-
kafka接收器连接器-->postgres,使用avro JSON数据失败
我设置了一个Kafka JDBC接收器以将事件发送到PostgreSQL。我编写了这个简单的生产者,它将带有模式(avro)数据的JSON发送到一个主题,如下所示: producer.py(kafka-python) 价值架构: 连接器配置(无主机、密码等) 但我的连接器出现严重故障,有三个错误,我无法找出其中任何一个错误的原因: TL;博士;日志版本 完整日志 有人能帮我理解这些错误和潜在的原因
-
ConFluent Kafka Sink Connector未将数据加载到Postgres表
我试图通过Kafka Sink连接器将数据加载到Postgres表,但我收到以下错误: 原因:组织。阿帕奇。Kafka。连接错误。ConnectException:无法更改以添加缺少的字段SinkRecordField{schema=schema{STRING},name='A_ABBREV',isPrimaryKey=false},因为它不是可选的,也没有默认值 Postgres DB中的表已经
-
由于组织原因,在分区主题0的生成请求中收到无效元数据错误。阿帕奇。Kafka。常见的错误。NotLeaderorPartitionException
我们使用SpringKafka流生产者来产生Kafka主题的数据。当我们做弹性测试时,我们得到了下面的错误。 `2020-08-28 16:18:35.536警告[,,]26---[ad|producer-3]好的客户。制作人内部。发件人:[Producer clientId=Producer-3]在分区topic1-0上的生成请求中收到无效元数据错误,原因是组织。阿帕奇。Kafka。常见的错误。