《kafka》专题
-
制作人丢失了一些关于Kafka重启的消息
Kafka客户:0.11.0.0-cp1Kafka经纪人: 在Kafka broker滚动重启时,我们的应用程序在发送到broker时丢失了一些消息。我相信滚动重启不应该丢失任何信息。以下是我们正在使用的生产者(将生产者与异步发送()一起使用,而不使用回调/未来等)设置: 我在日志中看到了这些例外 但日志显示重试尝试离开了,我很好奇为什么它没有重试呢?如果有人有任何想法,请告诉我?
-
组织。阿帕奇。Kafka。常见的错误。超时异常
我有两个代理1.0.0Kafka集群,我正在针对这个Kafka运行1.0.0Kafka流API应用程序。我增加了制片人的要求。暂停。毫秒到5分钟来修复生产者超时异常。 目前,在运行一段时间后,我发现以下两种类型的异常。我试图按照ApacheKafka中的建议修复这些异常:TimeoutException,然后什么都不起作用 但不完整的解决方案就在这里。建议使用此解决方案(减少生产批量)。请帮忙。
-
使用脚本时,我无法向Kafka生成数据,但我可以列出脚本中的主题
各位,局域网中有一个虚拟服务器,ip是,我的机器ip是。今天,我尝试使用我的机器()向我的虚拟服务器()发送一些消息,使用Kafka控制台生成器 但有点不对劲。问题描述如下: 但当我使用脚本列出主题时,它是有效的: 这个问题困扰了我很长一段时间,有人能帮我解决吗?
-
Kafka超时异常:批处理已过期
我们在生产方面面临以下问题: 是因为无效的配置,如批量大小、请求超时或其他原因吗?
-
Azure eventhub Kafkaorg.apache.kafka.common.errors.TimeoutException的一些记录
有一个包含80到100条记录的ArrayList,试图将每条记录(POJO,而不是整个列表)流式发送到Kafka主题(event hub)。计划了一个cron作业,比如每小时将这些记录(POJO)发送到事件中心。 能够看到发送到eventhub的消息,但在成功运行3到4次后,会出现以下异常(其中包括发送的多条消息,以及出现以下异常的多条失败消息) 以下是使用的生产者配置, 消息保留期-7分区-6使
-
Kafka监听器中的钩子
在kafka收听消息之前/之后是否有任何类型的钩子可用? 用例:必须为设置MDC关联id以执行日志跟踪 我在找什么?前/后回调方法,以便可以在进入时设置MDC关联id,并最终在退出时清除MDC。 编辑的场景:我正在获取作为Kafka Headers一部分的相关ID,我想在Kafka Listener中收到消息后立即在MDC中设置相同的ID 感谢您的帮助
-
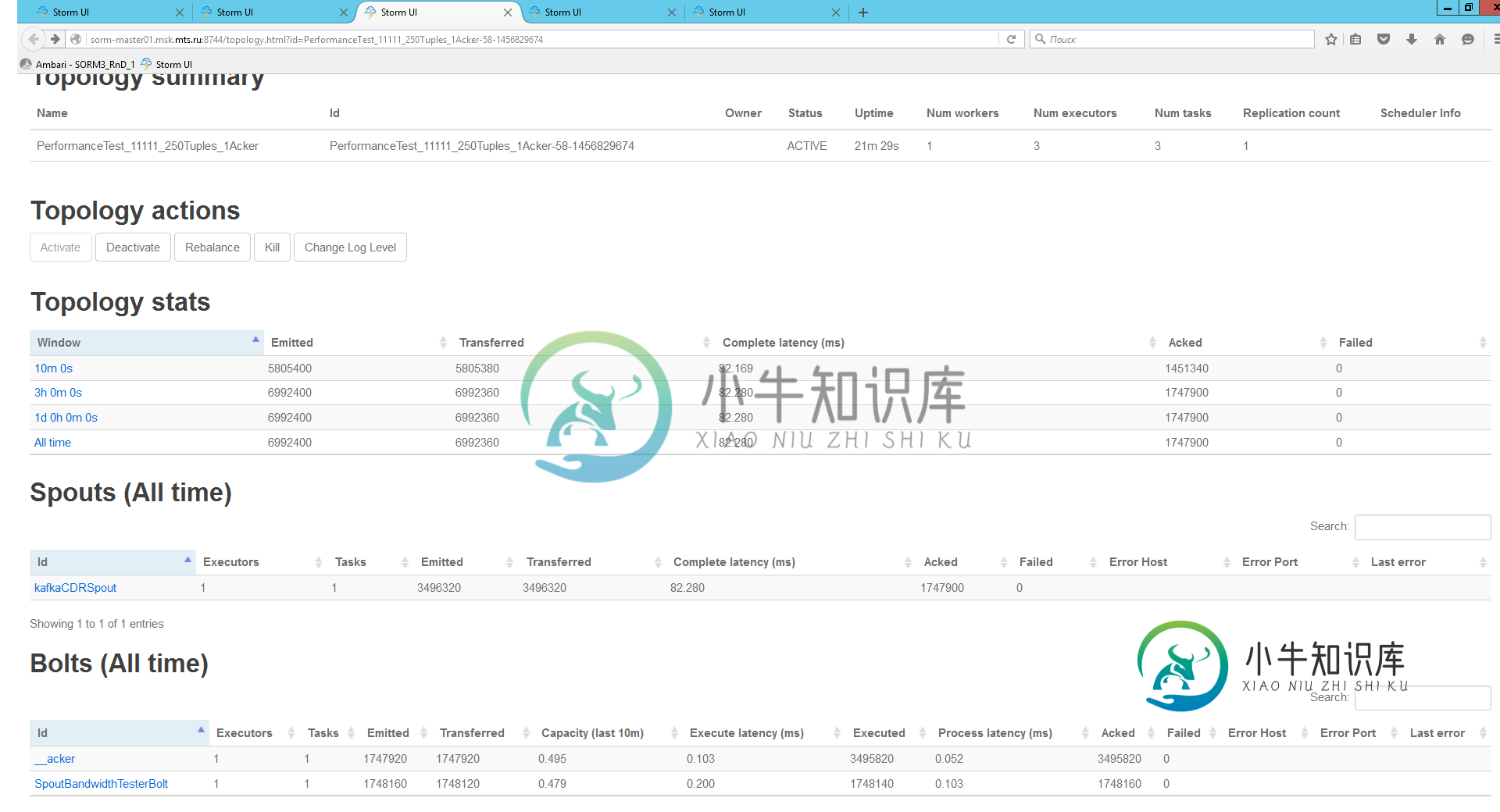 Kafka吐槽糟糕的表演
Kafka吐槽糟糕的表演我正在测试简单拓扑以检查Kafka喷口的性能。它包含kafka spout和Bolt来确认每个元组。Bolt执行方法: 拓扑结构如下所示: 其他拓扑设置: 我在10分钟内得到了1.5kk元组。螺栓的性能约为0,5。所以我的逻辑很简单:如果我双倍喷注和螺栓并行提示-我将得到双倍的性能。下一个测试是1个工人2个Kafka喷口,2个简单的夹子螺栓和Topology.Acker.Executors=2。以
-
降低Log4j2的内部日志级别(使用Kafka Appender)
我使用Log4j2(v2.17.2)直接向kafka发送信息,并使用XML创建配置(正如许多文章提到的那样,XML可以处理更多的配置选项,而属性不能)。我的问题是,我的控制台中充满了不相关的信息日志行(例如): 我已经从programmetically-change-log-level-in-log4j2中试用了所有技术,没有对日志进行任何更改: 有人有运气从INFO中获得日志级别降低吗?我真的不
-
检索无法反序列化的Kafka消息的有效负载和标头
我使用spring kafka 2.1.7来使用JSON消息,我想处理无法正确反序列化的消息<为了覆盖在同一条消息上循环的默认行为,我扩展了JsonDeserializer来覆盖反序列化方法。 这是我的消费者及其配置: 最后,我实现了自己的错误处理程序,以便将错误数据发送到其他主题。 这是当我使用错误消息时发生的情况: CustomKafkaJsonDeserializer尝试反序列化消息并捕获异
-
Kafka将标点时间戳流到上下文时间戳之前
我们正在使用使用STREAM_TIME标点符号的自定义转换器。当我记录通过转换函数发送的消息时,来自context.timestamp()的流时间显示如预期的那样——基于使用时间戳提取器派生的数据的合理日期。 现在——在过去的某个时候,我们收到了一些恶意消息,将流时间提前到2036年。我们现在已经阻止了这些上游,重新启动了Kafka河。 当流启动时,标点符号会在受影响任务的启动时运行,但会显示20
-
Kafka Streams/如何获得一个iterator正在迭代的分区?
在我的Kafka Streams应用程序中,我有一个任务来设置一个预定的(按墙时间)标点符号。标点符号遍历商店的条目并对它们做一些事情。像这样: 由于我在这里使用单个存储(可能是分区的),我假设标点符号的每一次执行都绑定到该存储的单个分区。 有可能找出标点器在哪个分区上运行吗?用于声明此方法在标点符号中返回。 我读过《Kafka流:标点与过程》及其答案。我可以理解,一般来说,任务与特定分区无关。但
-
Kafka将流作为表补丁日志,而不是完整发布
期望的功能:对于给定的密钥key123,许多服务并行运行,并将其结果报告给单个位置,一旦为key123收集了所有结果,就会将其传递给新的下游消费者。 最初的想法:使用AWS DynamoDB保存给定条目的所有结果。每次结果准备就绪时,微服务都会对key123上的数据库执行PATCH操作。输出流检查每个UPDATE以查看条目是否完整,如果是,则将其转发到下游。 新想法:使用Kafka Streams
-
Kafka流程序正在重新处理已处理的事件
我将一些事件转发给Kafka并启动了我的Kafka流程序。我的程序开始处理事件并完成。一段时间后,我停止了我的Kafka流应用程序并重新开始。观察到我的Kafka流程序正在处理已经处理过的先前事件。 根据我的理解,Kafka流在内部维护每个应用程序id的输入主题本身的偏移量。但在这里重新处理已经处理的事件。 如何验证Kafka流处理的偏移量?Kafka流是如何保存这些书签的?根据什么 如果Kafk
-
Quakus/Smallrye反应性kafka-来自消息的endpoint成功/失败响应
我希望使用动态接受主题作为查询参数的成功/失败响应来响应RESTendpoint。在带有小型反应式消息传递的Quakus中,代码看起来就像下面用OutgoingKafkaRecordMetadata包装有效负载一样 即https://myendpoint/PublishToKafka?主题=myDynamicTopic 从Quarkus doco“如果endpoint没有返回CompletionS
-
Quarkus有什么功能可以向Kafka发送消息吗
我是Kafka和quarkus的新手,我想在处理用户请求后向Kafka主题发送消息。 我已经浏览了Quarkus-快速入门中提供的kafka示例。我已经尝试使用KafkaMessage 但我得到了一个结果,那就是不断地向Kafka主题发送消息。 我想知道是否有其他方法或我的代码是否有任何问题。 帮助感谢