
Kafka吐槽糟糕的表演

我正在测试简单拓扑以检查Kafka喷口的性能。它包含kafka spout和Bolt来确认每个元组。Bolt执行方法:
public void execute(Tuple input) {
collector.ack(input);
}
拓扑结构如下所示:
protected void configureTopology(TopologyBuilder topologyBuilder) {
configureKafkaCDRSpout(topologyBuilder);
configureKafkaSpoutBandwidthTesterBolt(topologyBuilder);
}
private void configureKafkaCDRSpout(TopologyBuilder builder) {
KafkaSpout kafkaSpout = new KafkaSpout(createKafkaCDRSpoutConfig());
int spoutCount = Integer.valueOf(topologyConfig.getProperty("kafka.cboss.cdr.spout.thread.count"));
builder.setSpout(KAFKA_CDR_SPOUT_ID, kafkaSpout, spoutCount)
.setNumTasks(Integer.valueOf(topologyConfig.getProperty(KAFKA_CDR_SPOUT_NUM_TASKS)));
}
private SpoutConfig createKafkaCDRSpoutConfig() {
BrokerHosts hosts = new ZkHosts(topologyConfig.getProperty("kafka.zookeeper.broker.host"));
String topic = topologyConfig.getProperty("kafka.cboss.cdr.topic");
String zkRoot = topologyConfig.getProperty("kafka.cboss.cdr.zkRoot");
String consumerGroupId = topologyConfig.getProperty("kafka.cboss.cdr.consumerId");
SpoutConfig kafkaSpoutConfig = new SpoutConfig(hosts, topic, zkRoot, consumerGroupId);
kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new CbossCdrScheme());
kafkaSpoutConfig.ignoreZkOffsets = true;
kafkaSpoutConfig.fetchSizeBytes = Integer.valueOf(topologyConfig.getProperty("kafka.fetchSizeBytes"));
kafkaSpoutConfig.bufferSizeBytes = Integer.valueOf(topologyConfig.getProperty("kafka.bufferSizeBytes"));
return kafkaSpoutConfig;
}
public void configureKafkaSpoutBandwidthTesterBolt(TopologyBuilder topologyBuilder) {
SimpleAckerBolt b = new SimpleAckerBolt();
topologyBuilder.setBolt(SPOUT_BANDWIDTH_TESTER_BOLT_ID, b, Integer.valueOf(topologyConfig.getProperty(CFG_SIMPLE_ACKER_BOLT_PARALLELISM)))
.setNumTasks(Integer.valueOf(topologyConfig.getProperty(SPOUT_BANDWIDTH_TESTER_BOLT_NUM_TASKS)))
.localOrShuffleGrouping(KAFKA_CDR_SPOUT_ID);
}
其他拓扑设置:
topology.max.spout.pending=250
topology.executor.receive.buffer.size=1024
topology.executor.send.buffer.size=1024
topology.receiver.buffer.size=8
topology.transfer.buffer.size=1024
topology.acker.executors=1
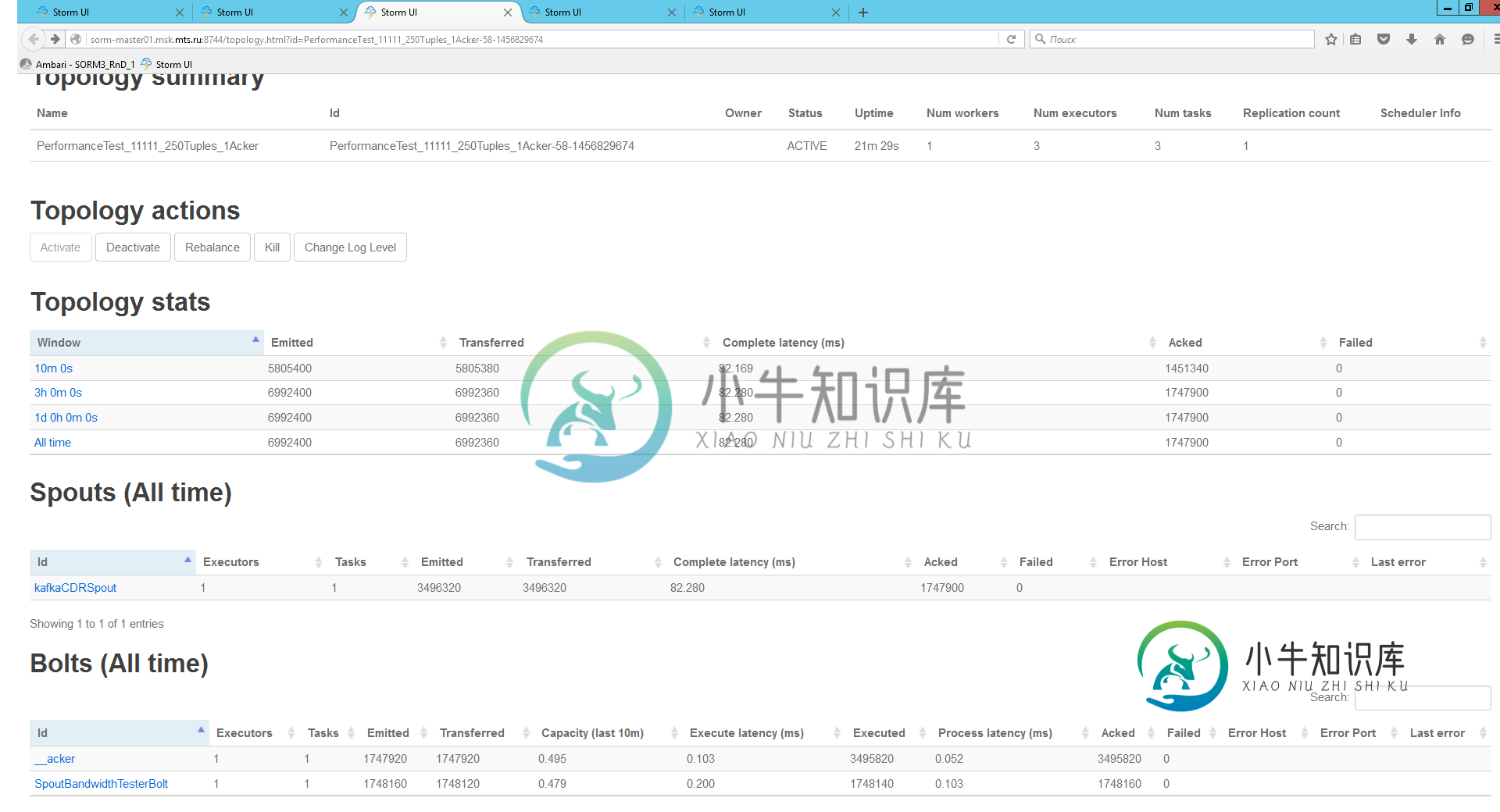
我在10分钟内得到了1.5kk元组。螺栓的性能约为0,5。所以我的逻辑很简单:如果我双倍喷注和螺栓并行提示-我将得到双倍的性能。下一个测试是1个工人2个Kafka喷口,2个简单的夹子螺栓和Topology.Acker.Executors=2。以下是结果:

所以,我得到了更差的性能增加并行化提示。为什么会发生?我如何增加元组每秒处理?实际上,任何喷口并行性提示大于2的测试都比1个喷口执行者显示出更差的结果。
我已经检查过:
1)这不是kafka错误。主题在2个Brokers上有20个分区。拓扑在4个workers上扩展并获得x4性能。
2)这不是服务器错误。服务器有40个内核和32GB RAM。运行拓扑时,它消耗了大约1/8的CPU和几乎没有RAM。
3)更改拓扑.max.spout.pending参数无济于事。
4)增加Bolt或Acker并行性提示也无济于事。
共有1个答案

因此,似乎你的一个员工的表现达到了极限。你只是让一个工人做很多事情,它不能处理所有的事情。
此时,如果您想进一步提高系统的性能,您有两个选择。
- 添加更多员工。
- 提高“一个员工”执行工作的能力。
worker.heap.memory.mb:
worker.childopts:
supervisor.childopts:
supervisor.memory.capacity.mb:
supervisor.cpu.capacity:
-
在我第一次使用JavaFX时,场景被错误地显示,我没有找到原因。例如,在E(fx)clipse页面的第一个基本教程中提出了以下代码: 它应该显示文本“Hello FX”,但显示以下内容: 我的Java版本是适用于Windows 64(Win 7)的8u65。
-
译者注:该小结关于错误处理的观点,译者并不完全赞同,关于本小结的部分想法请参考关于16.10.2小节错误处理的一些见解 依附于第13章模式的描述和第17.1小节与第17.2.4小节的总结。 16.10.1 不要使用布尔值: 像下面代码一样,创建一个布尔型变量用于测试错误条件是多余的: var good bool // 测试一个错误,`good`被赋为`true`或者`false`
-
一进去,面试官迟到,等了近十分钟,面试官到了,开始面试 先狂问我的毕设,具体到其中的算法实现。由于算法不是自己写的,具体细节并不了解,就只能说不会,然后就被质疑是不是自己做的,在毕设中担任了什么工作,怎么具体细节都不清楚,我只能说是使用了别人做的算法包,具体实现细节不是特别清楚 之后开始正式的java坐牢环节 一上来直接问我用的jdk版本,我说了jdk8,然后居然问我为什么用jdk8。我直接一脸问
-
问题内容: 我不是PHP开发人员,但我在很多地方都看到人们似乎把它当作瘟疫之类。为什么? 问题答案: 表示通过GET或POST传递的所有变量都可以作为脚本中的全局变量使用。由于访问未声明的变量不是PHP中的错误(这是警告),因此可能导致非常讨厌的情况。考虑一下,例如: 这本身不是一件坏事(精心设计的代码不应生成警告,因此不应访问可能未声明的变量(并且出于相同原因也不 需要 )),但是PHP代码通常
-
我用jacoco做报道。当我看jacoco报告时,覆盖面似乎不错。但是在Sonarqube中,覆盖率很低,因为它说来自lombok的< code>@Data注释没有被测试覆盖。 编译的类被标记为但 Sonar 不会忽略它。 如何排除分析的?
-
问题内容: 类似于这个问题… 您实际上在Java代码中发现了哪些最差的做法? 我的是: 在Servlet中使用实例变量(实际上,这不仅是错误的做法,而且还是错误) 使用HashMap之类的Collection实现,而不使用适当的接口 使用看似神秘的类名,例如SmsMaker(SmsFactory)或CommEnvironment(CommunicationContext) 问题答案: 我必须维护J