
Kafka消费者如何以相似的速度从不同的分区读取数据?

在处理Spark结构化流和Kinesis流时,我在重新处理流中积累的数据时遇到了不平衡读取(与读取最新数据相反)。
下一个图表显示了作为流一部分的kinesis片段的读取速度差异。
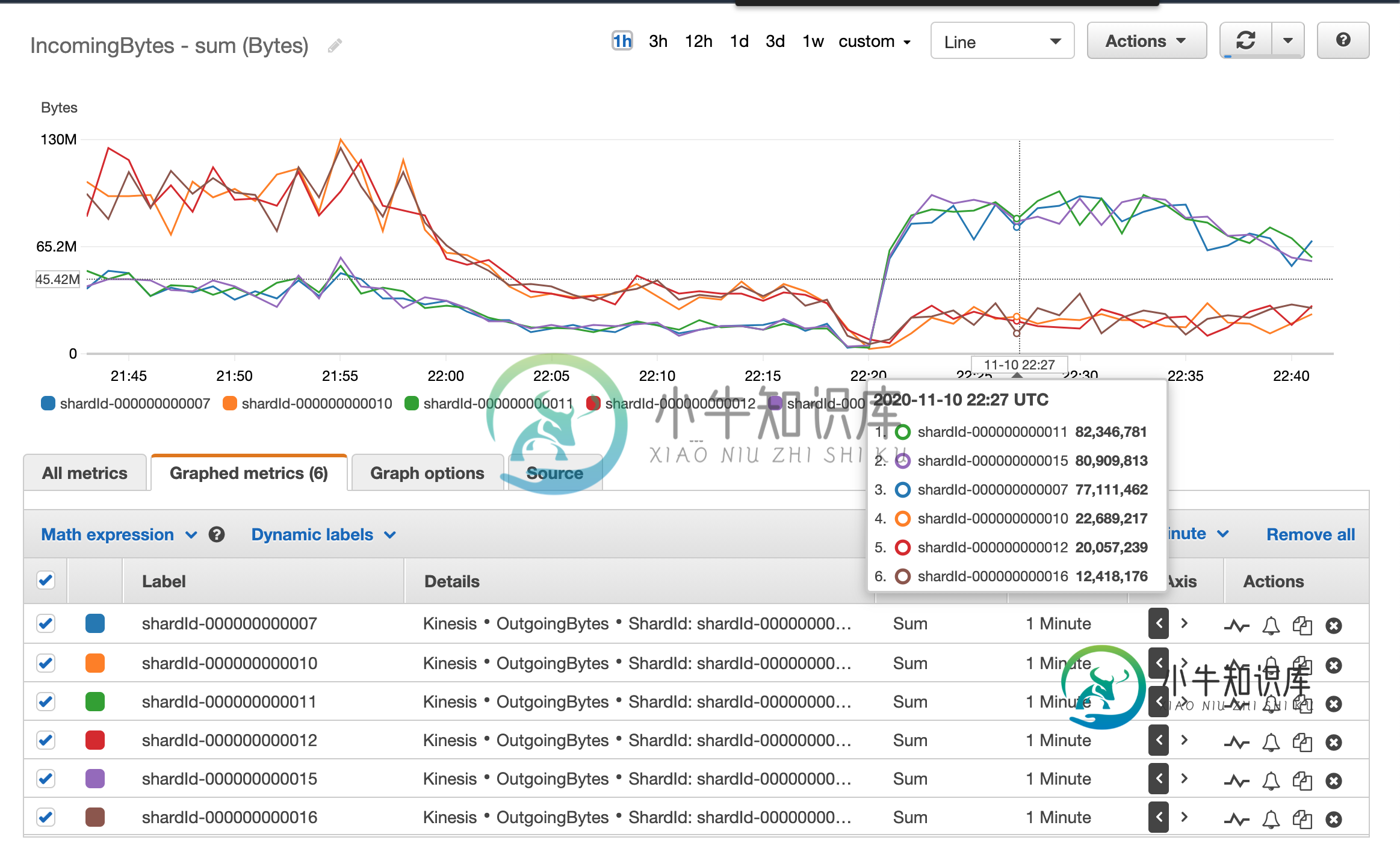
这使得spark jobs丢弃了很多事件,因为事件时间非常不同的事件会被混淆,而那些认为旧的事件会被丢弃。
最近一位团队成员建议改用Kafka。我对Apache Kafka解决这个问题有点怀疑,因为AFAIK修复我上面描述的不平衡读取的唯一方法是在消费者级别引入某种协调。这就是Apache Flink的Kinesis Conector在重新处理Kinesis流(事件时间对齐-碎片消费者)时提供对齐的方式
我一直在更深入地研究Apache Kafka的架构和设计,但我看不到任何类似于消费者群体协调机制的东西。
尽管如此,经过一些测试,来自Kafka主题的消息的重新处理在分区之间更加一致。似乎有某种协调机制。
我知道,在像Kafka这样的分布式系统中引入节点之间的协调会降低吞吐量(这是在Flink连接器中使用碎片对齐进行运动时要付出的代价)。这让我更加好奇,这怎么可能发生?没有协调机制,阿帕奇·Kafka如何实现这一目标?
共有1个答案

Kafka分区人员决定如何在Kafka主题的不同分区之间分发消息。
默认情况下,kafka生产者使用murmur2哈希算法来决定将每个密钥发送到哪里。通过使用此哈希,Kafkapromise您将在同一分区中拥有相同的密钥。
如果您的用例不需要在事件之间排序,那么您可能根本不需要发送密钥。
当不发送密钥时,消息将在“循环”中跨分区分发
当消费者加入消费者组时,会为其分配一个分区,由其单独负责处理。来自同一消费者组的任何其他消费者都不会在分区上共享此所有权。
因此,对于您的问题,如果您的生产者将您的消息均匀地分布在主题的分区中,并且您在消费者组中有偶数个消费者线程,他们将负责相同数量的分区,并且消费将是“相同的”跨消费者
-
我对Kafka有一个概念上的问题。 我们有许多机器在一个主题上充当消费者,有许多分区。这些机器运行在不同的硬件设置上,将会有比其他机器具有更高吞吐量的用户。 现在,使用者和一个或多个分区之间存在直接的相关性。
-
我想知道一个使用者如何从多个分区使用消息,具体来说,从不同的分区读取消息的顺序是什么? 我看了一眼源代码(Consumer,Fetcher),但我不能完全理解。 这是我以为会发生的: 分区是顺序读取的。也就是说:在继续下一个分区之前,一个分区中的所有消息都将被读取。如果我们达到< code>max.poll.records而没有消耗整个分区,则下一次读取将继续读取当前分区,直到耗尽为止,然后继续下
-
我们计划编写一个Kafka消费者(java),它读取Kafka队列以执行消息中的操作。
-
我正在尝试编写一个简单的java kafka consumer,使用与中类似的代码读取数据https://github.com/bkimminich/apache-kafka-book-examples/blob/master/src/test/kafka/consumer/SimpleHLConsumer.java. 看起来我的应用程序可以连接,但它无法获取任何数据。请建议。 下面是我在ecli
-
我有一个多分区主题,由多个使用者(同一组)使用。我的目标是最大化消费处理,即任何消费者都可以消费来自任何分区的消息。 我知道这看起来是不可能的,因为只有一个消费者可以从一个分区中消费。 有没有可能使用REST代理来实现这一点?例如,轮询所有代理消费者实例。 谢了。
-
TL;DR;我试图理解一个被分配了多个分区的单个使用者是如何处理reach分区的消费记录的。 例如: 在移动到下一个分区之前,会完全处理一个分区。 每次处理每个分区中的可用记录块。 从第一个可用分区处理一批N条记录 以循环旋转方式处理来自分区的N条记录 我找到了或分配程序的配置,但这只决定了使用者如何分配分区,而不是它如何从分配给它的分区中使用。 我开始深入研究KafkaConsumer源代码,#