《kafka》专题
-
当Flink中的Kafka数据有新的Avro模式时,如何更新表模式?
我们正在使用Flink表API在Flink应用程序中使用一个Kafka主题。 当我们第一次提交应用程序时,我们首先从我们的自定义注册表中读取最新的模式。然后使用Avro模式创建一个Kafka数据流和表。我的数据序列化器的实现与汇合模式注册表的工作方式类似,方法是检查模式ID,然后使用注册表。因此我们可以在运行时应用正确的模式。
-
生成“假”流数据。Kafka-Flink
如果是,请把我放在轨道上实现。
-
在pyflink中访问kafka时间戳
我正在尝试编写一个用于测量延迟和吞吐量的Pyflink应用程序。我的数据作为来自kafka主题的json对象,并使用类加载到中进行反序列化。下面是对这篇文章的回答(如何在Kafka和Flink环境中测试性能?)我让Kafka的制作人在事件中加上时间戳,但我很难理解我现在如何才能访问这些时间戳。我知道上面提到的文章为这个问题提供了一个解决方案,但是我很难将这个例子转移到python,因为文档/例子很
-
从命令提示符创建Kafka监制器时出现broker断开连接错误
[2020-10-31 10:53:55,832]警告[Producer ClientID=Console-Producer]Bootstrap broker Vagrant-10:9092(ID:-1 Rack:null)已断开连接(org.apache.kafka.clients.NetworkClient)*
-
很少有kafka分区没有分配给任何flink使用者
我有一个带有15个分区的kafka主题[0-14],我正在运行带有5个并行的flink。因此,理想情况下,每个并行flink使用者应该分别使用3个分区。但即使在多次重启之后,很少有Kafka分区不被任何flink工人订阅。 注意:如果我以1个并行度开始作业,则作业工作非常好。 Flink版本:1.3.3
-
在Flink中加入静态和动态Kafka源
今天,我想讨论一个关于Flink的概念性话题,而不是一个技术性话题。 在我们的例子中,我们确实有两个Kafka主题A和B,需要连接。连接应该始终包括主题A中的所有元素,以及主题B中的所有新元素。实现这一点有两种可能:始终创建一个新的使用者并从一开始就开始使用主题A,或者在使用后将主题A中的所有元素保持在一个状态内。现在,技术方法是通过连接两个数据流,这很快就向我们展示了它在这个用例中的局限性,因为
-
Apache Flink:在多个Kafka分区中使用事件时间时没有输出
因此,我将替换为,就像在这个文档示例中一样(具有更高的maxOutOfOrderness延迟),以便处理乱序事件,但我仍然无法获得任何输出。这是为什么?
-
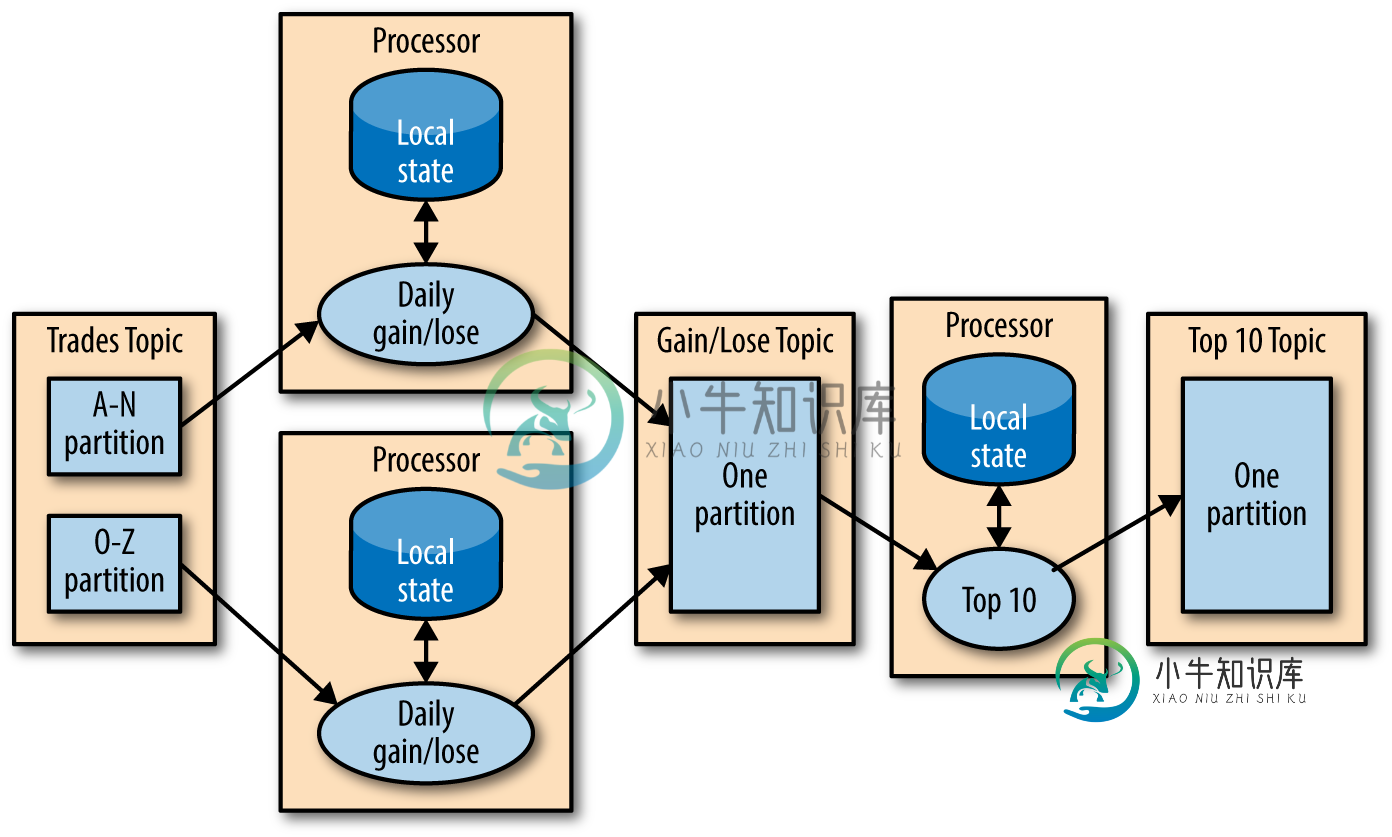 Apache Flink State Store vs Kafka Streams
Apache Flink State Store vs Kafka Streams据我所知,处理Kafka流会在内存、光盘或Kafka主题中本地显示其状态,因为所有的输入数据都来自一个分区,其中所有的消息都是由一个定义的值键控的。大多数时候,计算可以在不知道其他处理器状态的情况下完成。如果是,则有另一个Streams实例来计算结果。就像这张图: Flink的状态到底存储在哪里?Flink是否也可以在本地存储状态,还是总是将它们发布到所有实例(任务)?是否可以配置Flink,使其
-
KafkaStream createTopic不尊重Kafka服务器的Auto.Create.Topics.Enable设置
我们有一个生产Kafka集群,最近被一堆新话题污染了。Kafka群集具有以下设置: 经过调查,我发现这些主题是由使用的createTopic方法的客户团队创建的: 这是否意味着KafKastReam的主题创建不经过的服务器端代理设置?这是否意味着方法不算自动主题创建?如果是这样,我们如何阻止客户团队以编程方式在Kafka集群上创建主题呢? 编辑:kafka集群运行的是10.1.1,客户端运行的是k
-
Apache Kafka根据消息的值对窗口消息进行排序
我的Kafka publisher发送以下格式的字符串消息: 例如: 另外,我们为每个消息添加一些消息键,将它们发送到相应的分区。 我如何在1分钟窗口中重新排序消息并将它们发送到另一个主题?
-
kafka闪烁时间戳事件时间和水印
我正在阅读《Stream Processing with Apache Flink》一书,书中说:“从版本0.10.0开始,Kafka支持消息时间戳。当从Kafka版本0.10或更高版本读取时,如果应用程序以事件时间模式运行,使用者将自动提取消息时间戳作为事件时间戳*“因此在函数中,调用将默认返回Kafka消息时间戳?请提供一个简单的示例,说明如何实现AssignerWithPeriodicalW
-
来自KAFKA KRB5 Kerberos问题的FLINK流
我正在尝试使用https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kafka.html从flink kafkaconsumer流式传输数据 在这里,我的KAFKA是Kerberos安全的,并且启用了SSL。 我该如何解决这件事?有没有别的办法通过KRB5?
-
Flink Kafka connector 0.10.0事件时间澄清和ProcessFunction澄清
我正纠结于一个关于Flink的Kafka的消费者连接器的事件时间的问题。引用Flink doc 自从Apache Kafka 0.10+以来,Kafka的消息可以携带时间戳,指示事件发生的时间(参见Apache Flink中的“事件时间”)或消息被写入Kafka代理的时间。 Kafka消费者不会发出水印。 一些问题和问题浮现在我的脑海中: > 我如何知道它的时间戳是发生的时间还是写给Kafka经纪
-
关于Flink与Kafka流媒体的问题
我有一个Java应用程序午餐一个flink工作来处理Kafka流。
-
如何在Flink独立集群上使用Flink作业中的两个Kerberos keytabs(用于Kafka和Hadoop HDFS)?
Kafka主题之一和HDFS,它们都需要单独的Kerberos身份验证(因为它们属于完全不同的集群)。 我的问题是: 可能吗(如果可能,怎么可能?)在服务器上运行的Flink集群上使用来自Flink作业的两个Kerberos keytabs(一个用于Kafka,另一个用于HDFS)?(因此Flink作业可以使用Kafka主题,同时写入HDFS) 如果不可能,当Kafka和HDFS都受Kerbero