《kafka》专题
-
Kafka的用途有哪些?使用场景如何?
本文向大家介绍Kafka的用途有哪些?使用场景如何?相关面试题,主要包含被问及Kafka的用途有哪些?使用场景如何?时的应答技巧和注意事项,需要的朋友参考一下 总结下来就几个字:异步处理、日常系统解耦、削峰、提速、广播 如果再说具体一点例如:消息,网站活动追踪,监测指标,日志聚合,流处理,事件采集,提交日志等
-
Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理
本文向大家介绍Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理相关面试题,主要包含被问及Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理时的应答技巧和注意事项,需要的朋友参考一下 创建主题时 如果不手动指定分配方式 有两种分配方式 消费组内分配
-
请简述下你在哪些场景下会选择 Kafka?
本文向大家介绍请简述下你在哪些场景下会选择 Kafka?相关面试题,主要包含被问及请简述下你在哪些场景下会选择 Kafka?时的应答技巧和注意事项,需要的朋友参考一下 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、HBase、Solr等。 消息系统:解耦和生产者和消费者、缓存消息等。 用户活动跟踪:Kaf
-
Kafka 都有哪些特点?
本文向大家介绍Kafka 都有哪些特点?相关面试题,主要包含被问及Kafka 都有哪些特点?时的应答技巧和注意事项,需要的朋友参考一下 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。 可扩展性:kafka集群支持热扩展 持久性、可靠性:消息被持久化
-
Kafka 分区的目的?
本文向大家介绍Kafka 分区的目的?相关面试题,主要包含被问及Kafka 分区的目的?时的应答技巧和注意事项,需要的朋友参考一下 分区对于 Kafka 集群的好处是:实现负载均衡。分区对于消费者来说,可以提高并发度,提高效率。
-
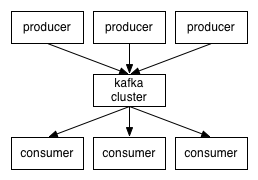 Kafka 的设计架构你知道吗?
Kafka 的设计架构你知道吗?本文向大家介绍Kafka 的设计架构你知道吗?相关面试题,主要包含被问及Kafka 的设计架构你知道吗?时的应答技巧和注意事项,需要的朋友参考一下 简单架构如下 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop 详细如下 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
-
你知道 Kafka 是如何做到消息的有序性?
本文向大家介绍你知道 Kafka 是如何做到消息的有序性?相关面试题,主要包含被问及你知道 Kafka 是如何做到消息的有序性?时的应答技巧和注意事项,需要的朋友参考一下 kafka 中的每个 partition 中的消息在写入时都是有序的,而且单独一个 partition 只能由一个消费者去消费,可以在里面保证消息的顺序性。但是分区之间的消息是不保证有序的。
-
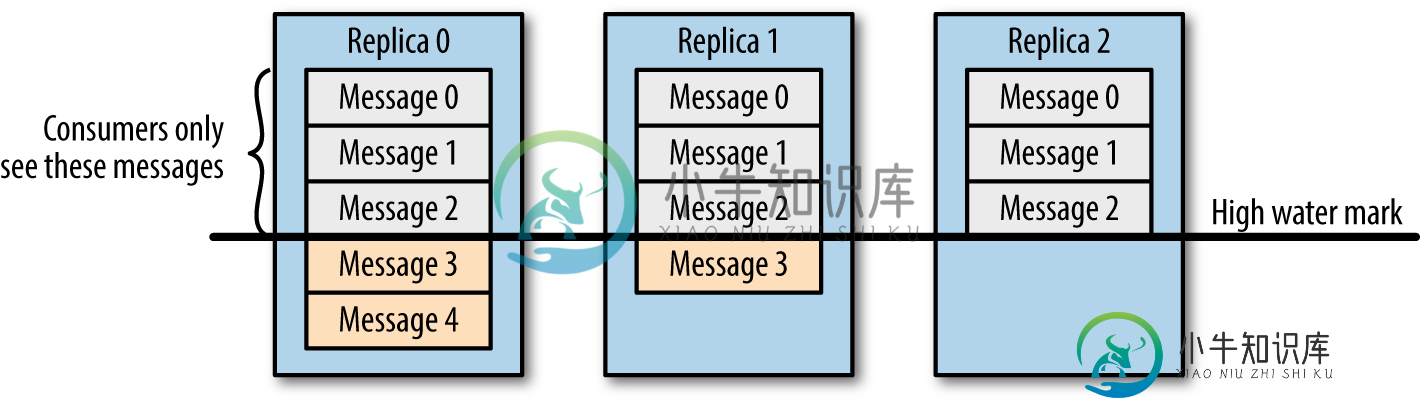 Kafka 的高可靠性是怎么实现的?
Kafka 的高可靠性是怎么实现的?本文向大家介绍Kafka 的高可靠性是怎么实现的?相关面试题,主要包含被问及Kafka 的高可靠性是怎么实现的?时的应答技巧和注意事项,需要的朋友参考一下 数据可靠性 Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 Leader 选举几个角度介绍数据的可靠性。 Topic 分区副本 在 Kafka
-
什么是Apache Kafka?
本文向大家介绍什么是Apache Kafka?相关面试题,主要包含被问及什么是Apache Kafka?时的应答技巧和注意事项,需要的朋友参考一下 答:Apache Kafka是一个发布 - 订阅开源消息代理应用程序。这个消息传递应用程序是用“scala”编码的。基本上,这个项目是由Apache软件启动的。Kafka的设计模式主要基于事务日志设计。
-
如果我指定了一个offset,Kafka Controller怎么查找到对应的消息?
本文向大家介绍如果我指定了一个offset,Kafka Controller怎么查找到对应的消息?相关面试题,主要包含被问及如果我指定了一个offset,Kafka Controller怎么查找到对应的消息?时的应答技巧和注意事项,需要的朋友参考一下
-
Kafka Connect堆空间不足
问题内容: 启动Kafka Connect()后,我的任务在以以下内容启动后立即失败: 在一些Kafka文档中提到堆空间,告诉您使用“默认值”进行尝试,并且仅在出现问题时才对其进行修改,但是没有修改堆空间的说明。 问题答案: 您可以通过设置环境变量来控制最大堆大小和初始堆大小。 以下示例将起始大小设置为512 MB,最大大小设置为1 GB: 当运行Kafka命令(如)时,将调用脚本,该脚本会在环境
-
Kafka使用者-使用者进程和线程与主题分区之间的关系是什么
问题内容: 我最近一直在与Kafka一起工作,对某个消费群体下的消费者有些困惑。混淆的中心是将使用者实现为进程还是线程。对于这个问题,假设我正在使用高级消费者。 让我们考虑一个我尝试过的场景。在我的主题中,有2个分区(为简单起见,我们假设复制因子仅为1)。我创建了一个消费者()过程与组,然后创建尺寸2的主题计数地图,然后产生了2个消费者线程和该过程下。看起来好像正在消耗分区,而且正在消耗分区。这种
-
Kafka不使用消息
我已经更新了我的Kafka从版本0.10.2.0到版本2.1.0,现在Kafka不能消费消息。我使用Spring引导,这是我的配置: 我已经更改了组id,以避免旧组id出现问题。我当前的spring版本是2.1。2.释放。在我的应用程序中,我可以看到我的客户是如何不断地重新连接的 你知道这个问题吗?
-
Spring Kafka消费者不接收消息
我不知道是怎么回事,我的java客户机消费者用@KafkaListener注释后没有收到任何消息。当我通过命令行创建消费者时,它可以工作。同样,Producer也能按预期工作(同样在java中)。有人能帮我理解这种行为吗? application.yml 生产者配置: 消费者配置: 制作人 Spring控制器: 这是我的控制台输出,正如您所看到的,它发送一条消息,但该方法不接收任何内容。如果我没有
-
kafka生产者/消费者重新启动后,消费者未收到消息
我们有一个制作人 在开发过程中,我重新部署了producer应用程序,并做了一些更改。但在此之后,我的消费者没有收到任何消息。我尝试重新启动消费者,但没有成功。问题可能是什么和/或如何解决? 消费者配置: 生产者配置: 编辑2: 5分钟后,消费者应用程序死亡,但以下情况除外: