《kafka》专题
-
 Spring Kafka和Spring Boot配置
Spring Kafka和Spring Boot配置在下面的教程中,我们将演示如何使用Spring Boot配置Spring Kafka。 Spring Boot使用合理的默认配置Spring Kafka。并使用属性文件覆盖这些默认值。 项目设置 Spring Kafka: Spring Boot: Apache Kafka: Maven: 此前已经学习了如何创建一个Kafka消费者和生产者,它可以手动配置生产者和消费者。 在这个例子中,我们将使用
-
Kafka应用
主要内容:推特,LinkedIn,Netflix公司,Mozilla, OracleKafka支持许多最好的工业应用。 在本章中,我们将简要介绍一些Kafka最显着的应用。 推特 Twitter是一种在线社交网络服务,提供发送和接收用户推文的平台。 注册用户可以阅读和发布推文,但未注册的用户只能阅读推文。 Twitter使用Storm-Kafka作为其流处理基础设施的一部分。 LinkedIn 在LinkedIn上使用Apache Kafka来获取活动流数据和运营指标。 Kafk
-
Kafka工具
主要内容:复制工具Kafka工具包装在下。 工具分为系统工具和复制工具。 系统工具 系统工具可以使用脚本从命令行运行。 语法如下 - 下面提到了一些系统工具 - Kafka迁移工具 - 此工具用于将代理从一个版本迁移到另一个版本。 Mirror Maker - 此工具用于将一个Kafka集群镜像到另一个。 消费者偏移量检查器 - 此工具显示指定的一组主题和使用者组的消费者组,主题,分区,偏移量,日志大小,所有者。
-
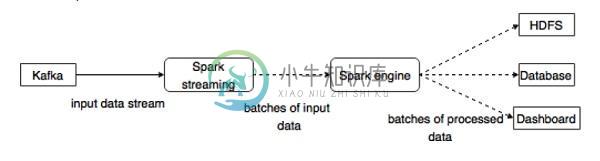 Kafka与Spark整合
Kafka与Spark整合主要内容:Spark是什么?,与Spark整合在本章中,将讨论如何将Apache Kafka与Spark Streaming API集成。 Spark是什么? Spark Streaming API支持实时数据流的可扩展,高吞吐量,容错流处理。 数据可以从Kafka,Flume,Twitter等许多来源获取,并且可以使用复杂算法进行处理,例如:映射,缩小,连接和窗口等高级功能。 最后,处理后的数据可以推送到文件系统,数据库和现场仪表板上。 弹
-
Kafka与Storm整合
主要内容:Storm是什么?,与Storm整合,提交到拓扑在本章中,我们将学习如何将Kafka与Apache Storm集成。 Storm是什么? Storm最初是由Nathan Marz和BackType团队创建的。 在很短的时间内,Apache Storm成为分布式实时处理系统的标准,用于处理大数据。 Storm速度非常快,每个节点每秒处理超过一百万个元组的基准时钟。 Apache Storm持续运行,从配置的源(Spouts)中消耗数据并将数据传递
-
Kafka费者群组示例
消费者群组是来自Kafka主题的多线程或多机器消费。 消费者群组 消费者可以通过使用加入一个组。 一个组的最大并行度是该组中的消费者的数量 ← 分区的数量。 Kafka将一个主题的分区分配给组中的使用者,以便每个分区仅由组中的一位消费者使用。 Kafka保证只有群组中的单个消费者阅读消息。 消费者可以按照存储在日志中的顺序查看消息。 重新平衡消费者 添加更多流程/线程将导致Kafka重新平衡。 如
-
Kafka简单的生产者例子
主要内容:KafkaProducer API,生产者API,配置设置,SimpleProducer应用程序,简单的消费者实例,SimpleConsumer应用程序在这一节中将创建一个使用Java客户端发布和使用消息的应用程序。 Kafka生产者客户端由以下API组成。 KafkaProducer API 下面来了解Kafka生产者API。 KafkaProducer API的核心部分是类。 类提供了一个选项,用于将Kafka代理的构造函数与以下方法连接起来。 类提供方法来异步发送消息到主题。 的
-
Kafka环境安装配置
主要内容:第1步 - Java安装,第2步 - ZooKeeper框架安装,第3步 - Apache Kafka安装以下是在您的机器上安装Java的步骤。 第1步 - Java安装 查看是否在机器上安装了java环境,只需使用下面的命令来验证它。 如果计算机上已成功安装Java,则可以看到已安装的Java版本。例如 - 如果没有安装好Java,那么可以参考以下步骤来安装。 Ubuntu上安装Java: https://www.xnip.cn/java/how-to-install-java-on
-
Kafka工作流
主要内容:发布订阅消息传递的工作流,队列消息/消费者组的工作流,ZooKeeper的角色截至目前,我们已经了解了Kafka的核心概念。 现在让我们来看看Kafka的工作流程。 Kafka只是分成一个或多个分区的主题集合。 Kafka分区是消息的线性排序序列,每个消息由其索引标识(称为偏移量)。 Kafka集群中的所有数据都是不相关的分区联合。 传入消息写在分区的末尾,消费者依次读取消息。 通过将消息复制到不同的经纪人来提供持久性。 Kafka以快速,可靠,持久的容错和零停机方式提供基
-
 Kafka群集体系结构
Kafka群集体系结构有关Kafka群集体系结构,请看下面的结构图。 它显示了Kafka的集群图。 下表描述了上图中显示的每个组件。 Broker - Kafka集群通常由多个代理组成,以保持负载平衡。 Kafka经纪人是无状态的,所以他们使用ZooKeeper维护他们的集群状态。 一个Kafka代理实例可以处理每秒数十万次的读写操作,每个Broker都可以处理TB消息,而不会影响性能。 Kafka经纪人的领导人选举可
-
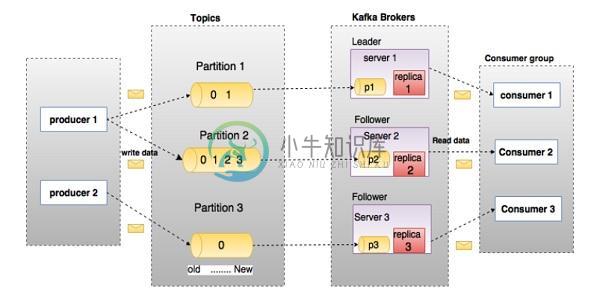 Kafka基本原理
Kafka基本原理在深入学习Kafka之前,需要先了解topics, brokers, producers和consumers等几个主要术语。 下面说明了主要术语的详细描述和组件。 在上图中,主题(topic)被配置为三个分区。 分区1(Partition 1)具有两个偏移因子和。分区2(Partition 2)具有四个偏移因子,,和,分区3(Partition 3)具有一个偏移因子。replica 的id与托管它
-
 Kafka简介
Kafka简介主要内容:什么是消息系统?,什么是Kafka?,优点,用例在大数据中,使用了大量的数据。 关于大数据,主要有两个主要挑战。第一个挑战是如何收集大量数据,第二个挑战是分析收集的数据。 为了克服这些挑战,需要使用消息传递系统。 Kafka专为分布式高吞吐量系统而设计。 Kafka倾向于非常好地取代传统的信息中间服务者。 与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和固有容错功能,因此非常适合大型消息处理应用程序。 什么是消息系统? 消息
-
Kafka教程
主要内容:面向读者,前提条件,问题反馈Apache Kafka起源于LinkedIn,后来于2011年成为Apache开源项目,然后于2012年成为Apache项目的第一个类别。Kafka是使用Scala和Java编写的。 Apache Kafka是基于 - 发布订阅的容错消息系统。 它具有快速,可扩展和设计分布的特点。 本教程将探讨Kafka的原理,安装和操作,然后它将引导您完成Kafka集群的部署。 最后,我们将教程结束实时应用,
-
Docker在无法连接到kafka的Azure容器实例上使用zookeeper、kafka和python脚本编写多容器
我正在尝试使用zookeeper/kafka非集群设置,以便能够使用python脚本与容器对话。我希望能够运行一个zookeeper/kafka容器和2个或多个容器,其中包含与zookeeper-kafka通信的python脚本,所有这些容器都在Azure上的容器或容器组中运行。 为了测试这一点,我创建了下面的docker容器组,其中zookeeper和kafka作为2个服务,第3个服务启动一个简
-
如何使Apache Kafka在Localhost和域名上都可用
我将Apache Kafka安装在一个Azure虚拟机上,带有zookeeper,配置如下 有了这个,我可以从外部计算机访问经纪人,甚至在本地计算机上,但如果我尝试在本地计算机上使用“localhost:9092”或“127.0.0.1:9092”,则可以使用“my.domain:9092”访问经纪人,其拒绝连接或不连接。 我想知道我缺少什么或需要更改的任何其他配置。动物园管理员处于默认设置。感谢