《kafka》专题
-
Kafka Connect可以成为我的Hadoop集群的一部分吗?
我目前正在使用一个由10个节点(1个名称节点和9个数据节点)组成的Hadoop集群,其中运行Hbase、Hive、Kafka、Zookeeper和Hadoop的其他echo系统。现在我想从RDBMS中获取数据,并将其实时存储在HDFS中。我们可以在同一个集群中使用Confluent Source Connector和HDFS2 Sink Connector吗?还是我需要为Kafka Connect
-
分发模式下的Kafka连接行为
我在分布式模式下运行Kafka连接,有两个不同的连接器,每个连接器都有一个任务。每个连接器都在不同的实例中运行,这正是我想要的。 Kafka connect集群是否总是确保相同的行为来适当地分担负载?
-
Kafka REST API源连接器,带有认证头
我需要为REST API创建kafka源连接器,并使用头验证,如curl-H“Authorization:Basic”-H“clientID:”“https: 我还尝试使用“connector.class”:“com.tm.kafka.connect.rest.RestSourceConnector”,我的joson文件如下 但没有希望。知道如何通过身份验证获取RESTAPI数据。我的身份验证参数
-
Kafka Connect using REST API with Strimzi with kind: KafkaConnector
我正在尝试使用 Kafka Connect REST API 来管理连接器,为简单起见,请考虑以下实现: 由于我使用< code>KafkaConnector作为资源,所以我不能使用Kafka Connect REST API,因为连接器操作符将KafkaConnector资源作为其唯一的事实来源,直接使用Kafka Connect REST API进行的手动更改(如< code>pause)会被
-
Apache Strimzi Kafka Bridge 实现
这对社区来说是一个非常普遍的问题,尤其是Kafka·斯特里姆齐桥的人,如果他们正在读这本书的话。 我正在尝试将他们的Apache Kafka HTTP Bridge作为POC来实现。文档非常糟糕,无法提供任何帮助。我真的只需要知道如何使用桥发布和使用来自Kafka主题的消息。我已经开始了这座桥,但由于文档缺乏基本示例,我不知道除此之外的任何事情。
-
如何部署Strimzi KafkaMirrorMaker
我正在使用 strimzi 运算符并在 k8s 上运行 kafka 集群。我想使用 Kafka Mirror Maker,我使用 CRD yml 部署了 Kafka Mirror Maker,但我的 KMM pod 处于崩溃环回状态。我不明白问题是什么?这是我的Kafka MirrorMaker yml 还有我的Kafka集群yml: 我的第二个Kafka集群: 我的窗格列表及其状态: 吊舱日志:
-
斯特里姆齐·Kafka在GKE的装置
有人能帮忙列出在GKE从零开始用strimzi operator安装Kafka需要的步骤吗.. 我们在其中一个 VM 上安装了一个融合的 kafka 。我们必须摆脱并从头开始在我们的 GKE 环境中安装 strimzi kafka。, 涉及的所有步骤是什么. 浏览本文档:https://strim zi . io/docs/operators/in-development/full/deployi
-
Strimzi kafka在GKE中私下访问
我有两个集群, 一个集群安装了我的应用程序微服务,另一个集群安装了Strimzi kafka。两者都是私有的GKE集群。 我的挑战是如何从我的应用程序连接到这个 kafka。大约有 10 个微服务正在运行,每个微服务都必须连接到 kafka。 我现在有一种方法,将Strimzi kafka作为Nodeport服务,并在应用程序代码中提供Ip和nodeIp。 这种方法的问题在于,如果 GKE 节点自
-
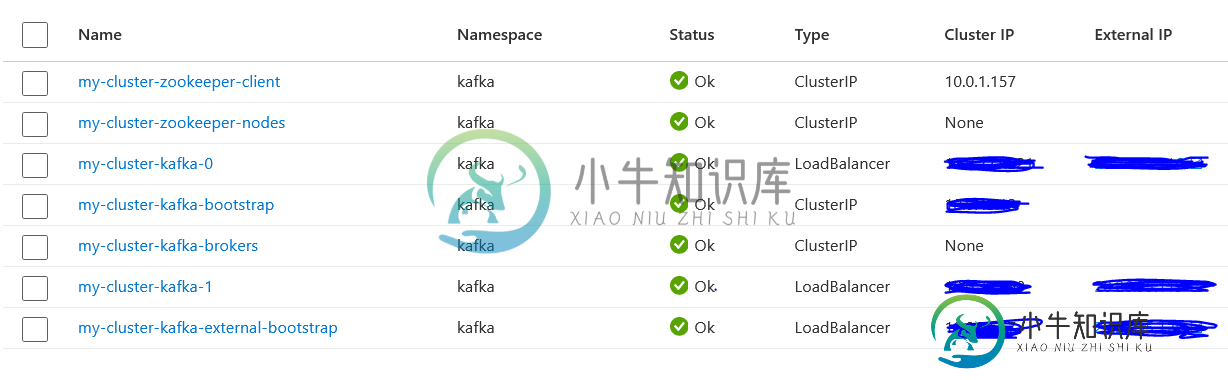 Kafka在Strimzi上的部署
Kafka在Strimzi上的部署我正在尝试使用 Strimzi 部署 Kafka,问题是,它将 Kafka 代理暴露为负载均衡器并为其分配外部 IP。我希望 Kafka 代理在内部可用,并且仅通过负载均衡器公开。下面是我的部署文件。 下面的集群截图 如您所见,有 3 个分配了外部 IP 的负载均衡器,而我希望它是一个具有外部 IP 的负载均衡器和 2 个 Kafka 代理。
-
哈斯特里姆兹Kafka-桥的文献?
我们正在考虑使用strim zi Kafka-Bridge(https://strim zi . io/docs/Bridge/latest/# proc-creating-Kafka-Bridge-consumer-Bridge)作为现有Kafka集群的HTTP(s)网关。 留档提到使用任意名称创建消费者以参与消费者组。这些名称随后可用于消费消息、查找或同步偏移量、… 问题是:我的假设是否正确?
-
使用9093作为负载平衡器端口strimzi kafka
是否可以将9093用作loadbalncer类型的侦听器端口,或者它将仅与9094一起用于strimzi kafka? 谢谢,sgv
-
如何在YARN中运行Kafka连接工作人员?
我正在玩Kafka-Connect。我让 在独立模式和分布式模式下工作。 他们宣传工人(负责运行连接器)可以通过 进行管理 但是,我还没有看到任何描述如何实现这一目标的文档。 我如何着手让< code>YARN执行工人?如果没有具体的方法,是否有通用的方法来让应用程序在< code>YARN中运行? 我已经使用< code>spark-submit将< code>YARN与SPARK一起使用,但是
-
自定义Kafka Connect-ElasticSearch接收器连接器
我有Kafka主题,有多种类型的消息流入并使用Kafka Connect写入弹性搜索。流看起来不错,直到我不得不将唯一的消息集分离到唯一的索引中。也就是说,我必须根据字段(JSON消息)为新的数据集获取新的索引。 我如何配置/定制Kafka connect以实现同样的功能?每个消息都包含一个表示消息类型和时间戳的字段。 示例 Json 如下所示: Sample1: {“log”:{“data”:“
-
Kafka连接:基于架构的单主题接收器到多个表
我是Kafka连线的新手。我有一个如下的用例: > 有一个共享主题,我在其中收到不同实体的消息,例如员工、部门(实际表名称不同) 员工和部门的模式在模式注册表中注册 使用Kafka接收器连接器,是否可以根据架构分离每个实体的数据并写入相应的表示例,进入主题的员工数据应转到员工表,部门数据应转到部门表 如果没有,还有其他更好的方法吗?
-
来自多个独立经纪人的Kafka接收器
我想将多个数据库的更改聚合到一个数据库中,所以我想在每个数据库旁边运行一个Debezium连接器和一个Kafka服务器/代理,并使用Kafka接收器连接器从所有这些Kafka中消费写入一个数据库。 问题是,我是否可以使用单个 Kafka 接收器连接器实例同时使用来自多个独立(不是集群)的 Kafka 代理。