《stream》专题
-
使用Spring Cloud Stream处理Avro反序列化异常
我有一个使用Spring Cloud Stream和Spring Kafka的应用程序,它处理Avro消息。该应用程序运行良好,但现在我想添加一些错误处理。 目标是:捕获反序列化异常,使用异常详细信息原始Kafka消息自定义上下文信息构建新对象,并将此对象推送到专用Kafka主题。基本上是DLQ,但原始消息将被截获并修饰。 问题是:虽然我可以拦截异常,但我不知道如何从Kafka那里获取原始消息(下
-
Spring-Cloud-Stream榆树。版本无法更改Serde
我无法使用留档(https://docs.spring.io/spring-cloud-stream/docs/Elmhurst.RELEASE/reference/htmlsingle/#_configuration_options_3)中指定的语法更改通道(或绑定)的序列。 假设我的通道是pcin,我知道我应该使用以下属性指示valueSerde和keySerde。云流动Kafka。流。绑定。
-
带有融合模式注册表的Spring Cloud Stream Kafka无法将消息发送到通道输出
我想用Confluent Schema Registry和Avro Schema evolution测试Spring Cloud Stream,以将其与我的应用程序集成。我发现Spring Cloud Stream不支持到融合模式注册中心的安全连接,实现仍然非常基础。因此,我决定将Confluent Schema Registry Client与Spring Kafka一起用于模式注册表部分,其余
-
无法使用ConFluent Schema注册表和Spring Cloud Stream反序列化Avro消息
我正在使用Spring Cloud Stream和Confluent Schema Registry注册Avro模式。 架构注册成功。但是,当我的流侦听器接收到消息时,负载仍然以字节为单位。 这是我的财产。 在接收消息时,我注意到“AbstractAvroMessageConverter”中的“convertFromInternal”从未被调用,而这应该是用来解码消息的。
-
带有Avro的Spring Cloud Stream无法正确转换字符串消息
我有一个问题,源发送GenericMessage[payload=xxxxx,...]而接收器接收消息作为10,120,120,120,120,120。 这个问题发生在我设置Avro消息转换器之后。如果我删除Avro消息转换器并使用StreamListener来处理消息转换,它会正常工作。 源应用程序。属性 水槽应用 消息转换器 应用程序类 我是否缺少配置?谢谢
-
使用Stream API在每个对象上调用方法的“好”方法
是否可以在使用者中运行方法,如方法引用,但要在传递给使用者的对象上运行: 会是这样的: 但那不起作用... 方法引用是否有可能,或者是-
-
处理Spark Streaming rdd并存储到单个HDFS文件
> 我正在使用Kafka Spark流媒体来获取流媒体数据。 我正在使用此数据流并处理RDD runConfigParser是一种JAVA方法,它解析文件并生成必须保存在HDFS中的输出。因此,多个节点将处理RDD并将输出写入一个HDFS文件。因为我想把这五个装进蜂箱。 我应该输出runConfigParser的结果并使用sc.parallze(输出)。保存ASTEXTFILE(path),以便所
-
使用spark streaming将每个Kafka消息保存在hdfs中
我正在使用火花流做分析。分析后,我必须将kafka消息保存在hdfs中。每个kafka消息都是一个xml文件。我不能使用,因为它会保存整个rdd。rdd的每个元素都是kafka消息(xml文件)。如何使用火花在hdfs中保存每个rdd元素(文件)。
-
使用Spark Streaming API测试Twitter
我是Spark流媒体框架的新手,正在尝试处理推特流。我正在编写测试用例,并了解我可以使用Spark StreamingSuite Base,这将帮助我将输入测试为函数流。但我编写了一个函数,它以DStream[状态]作为输入,处理后将DStream[字符串]作为输出。我在StreamingSuite数据库中使用的api是testOperation。 这是发送输入的函数。。 但是由于DStream[
-
使用kafka的spark streaming时,无法迭代从将数据流转换为列表检索到的密钥列表
下面是Kafka的spark streaming代码。在这里,我试图获取批处理的密钥作为Dstream,然后将其转换为列表。以便对其进行迭代,并将与每个键相关的数据放入以该键命名的hdfs文件夹中。 关键基本上是-模式。表\u名称 正在提取密钥,但其类型为DStream[字符串] 将其转换为列表并更新var final\u list\u of\u键 现在尝试遍历列表。 但我遇到了一个错误-不支持在
-
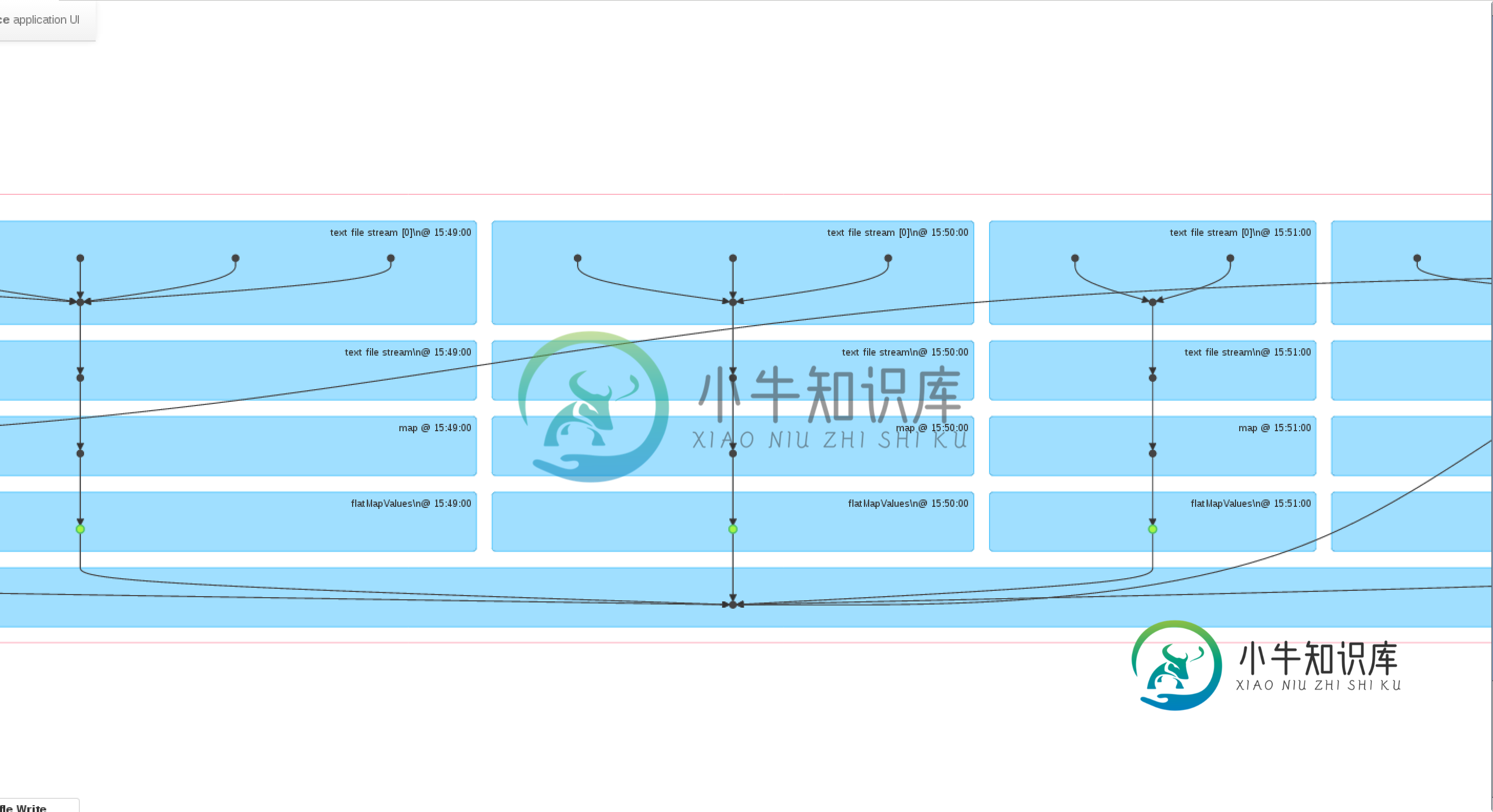 Spark Streaming-windows()是否缓存DStreams?
Spark Streaming-windows()是否缓存DStreams?有人能解释一下Spark Streaming是如何执行window()操作的吗?从Spark 1.6.1文档来看,窗口批处理似乎会自动缓存在内存中,但从web UI来看,似乎会再次执行以前批处理中已执行的操作。为方便起见,我在下面附上了我正在运行的应用程序的屏幕截图: 通过查看webUI,看起来好像是在缓存的是194 MapValures()RDD(绿点-这是我在DStream上调用windows
-
Spark Streaming提前写入日志重启后不重放数据
为了有一种简单的方法来测试Spark Streaming预写日志,我创建了一个非常简单的自定义输入接收器,它将生成字符串并存储这些字符串: 然后我创建了一个简单的应用程序,它将使用自定义接收器来流式传输数据并对其进行处理: 正如您所看到的,在每秒存储字符串的同时,对每个接收到的RDD的处理都有2秒的睡眠时间。这会创建积压工作,新字符串会堆积起来,应该存储在WAL中。实际上,我可以看到检查点目录中的
-
当接收器发生故障且WAL存储在s3中时,Spark streaming无法从预写日志记录中读取数据
这是错误日志- 组织。阿帕奇。火花SparkException:无法从组织中的预写日志记录文件BasedWriteHeadLogSegment(s3n://****/检查点/接收数据/20/日志-14392986600-1439298758600136785069)读取数据。阿帕奇。火花流动。rdd。WriteAheadLogBackedBlockRDD。org$apache$spark$stre
-
使用Spring Cloud Stream在使用者端设置到同一目的地和组的多个绑定失败
我打算为Kafka用户弹性设置多个绑定。更具体地说,备份侦听器与主侦听器期望代理IPS具有相同的目的地和组。备份侦听器的自动启动在启动时关闭,但在故障转移发生时将以编程方式打开。 启动消费者时引发异常-(不能为微服务中的不同通道分配相同的组名) https://github.com/garyrussell/spring-cloud-stream/commit/5b87b8cae494ae9568d
-
使用Spring Cloud Stream Kafka绑定器时无法设置groupId和clientId
我有严重的问题处理Spring云流Kafka活页夹。Spring Cloud 3.0.2.Release的配置设置中存在许多模糊性和一致性问题。我一直试图为Kafka主题设置组ID和客户端ID,但是尽管尝试了各种不同的组合,我还是无法正确配置组ID。 文档声称,我们应该能够通过配置以下设置之一来设置组id和客户端id:https://cloud.spring.io/spring-cloud-sta