《stream》专题
-
Codingbat挑战:not Alone Stream API解决方案
给定CodingBat中的任务notAlone: 如果数组中的元素前后都有值,并且这些值与它不同,那么我们会说它是“单独的”。返回给定数组的一个版本,其中给定值的每个单独实例都被其左侧或右侧较大的值替换。 我对这个问题的解决方案通过了绝大多数测试,但不是所有测试: 我的问题如下: 如何解决我的问题? 是否可以使用Stream API解决此任务? 测试结果
-
Codingbat挑战:zeroFront Stream API解决方案
给定来自CodingBat的zeroFront notAlone任务: 返回一个数组,该数组包含与给定数组完全相同的数字,但重新排列以使所有零都在数组的开头分组。非零数字的顺序并不重要。因此变为。您可以修改并返回给定数组或制作一个新数组。 我对这个问题的解决方案在某些情况下会抛出ArrayIndexOutOfBoundsException: 我的问题如下: 如何解决我的问题? 如何使用Stream
-
Node.js文件上传(Express 4,MongoDB,GridFS,GridFS-Stream)
问题内容: 我试图在我的node.js应用程序中设置文件API。我的目标是能够直接将文件流写入gridfs,而无需最初将文件存储到磁盘。似乎我的创建代码正在运行。我能够将文件上传保存到gridfs。问题是正在读取文件。当我尝试通过Web浏览器窗口下载保存的文件时,看到文件内容包裹着以下内容: 所以我的问题是,在将文件保存到gridfs之前,我该怎么做才能从文件流中剥离边界信息?这是我正在使用的代码
-
使用socket.io-stream将文件从服务器流传输到客户端
问题内容: 我设法将文件从客户端大块上传到服务器,但是现在我想实现相反的方式。不幸的是,此部分缺少官方模块页面上的文档。 我要执行以下操作: 向服务器发出流和带有文件名的“下载”事件 服务器应创建一个readstream并将其通过管道传输到客户端发出的流 当客户端到达流时,将出现一个下载弹出窗口,并询问将文件保存在何处 我不想使用简单的文件超链接的原因令人困惑:服务器上的文件已加密并重命名,因此我
-
 Node.js中流(stream)的使用方法示例
Node.js中流(stream)的使用方法示例本文向大家介绍Node.js中流(stream)的使用方法示例,包括了Node.js中流(stream)的使用方法示例的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要给大家介绍了关于Node.js 流(stream)的使用方法,分享出来供大家参考学习,下面话不多说,来一起看看详细的介绍: 流是基于事件的API,用于管理和处理数据,而且有不错的效率.借助事件和非阻塞I/O库,流模块允许在其可
-
JAVA8 STREAM COLLECT GROUPBY分组实例解析
本文向大家介绍JAVA8 STREAM COLLECT GROUPBY分组实例解析,包括了JAVA8 STREAM COLLECT GROUPBY分组实例解析的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了JAVA8 STREAM COLLECT GROUPBY分组实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 实体类Peop
-
为什么我将MIME类型的.csv文件作为“ application / octet-stream”获得?
问题内容: 我正在开发一个必须将Excel文件导入MySQL的PHP应用程序。所以我需要将Excel文件转换为.csv格式。但是当我想使用来获得它的类型时,我就得到了它的mime-type。 我认为这里有问题。因为我将以下列表收集为.csv文件mime-type: 怎么了 ? 问题答案: 在这种情况下,官方的HTTP规范总是很有帮助的。从RFC 2616 7.2.1 (我的重点已添加): 任何
-
如何在Java中使用flexjson从Reader Stream反序列化Java对象?
本文向大家介绍如何在Java中使用flexjson从Reader Stream反序列化Java对象?,包括了如何在Java中使用flexjson从Reader Stream反序列化Java对象?的使用技巧和注意事项,需要的朋友参考一下 该Flexjson 是一个轻量级 的序列化和反序列化Java对象和从JSON格式的库。我们可以使用JSONDeserializer类的deserialize ()
-
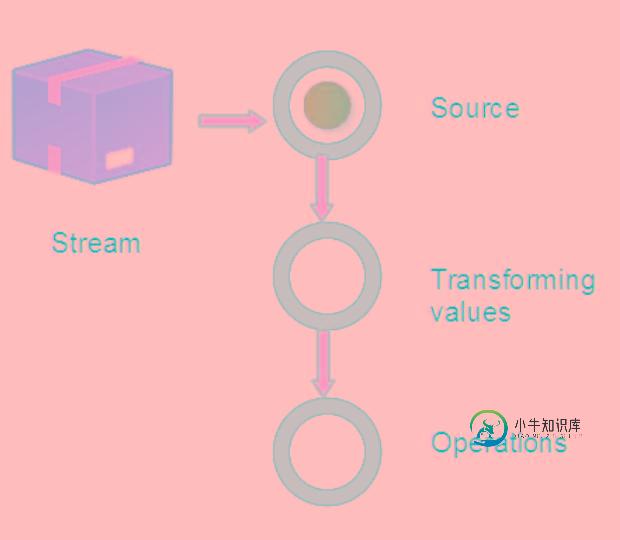 java8中Stream的使用示例教程
java8中Stream的使用示例教程本文向大家介绍java8中Stream的使用示例教程,包括了java8中Stream的使用示例教程的使用技巧和注意事项,需要的朋友参考一下 前言 Java8中提供了Stream对集合操作作出了极大的简化,学习了Stream之后,我们以后不用使用for循环就能对集合作出很好的操作。 本文将给大家详细介绍关于java8 Stream使用的相关内容,下面话不多说了,来一起看看详细的介绍吧 1. 原理 S
-
是否有人在使用AWS kinesis streams、lambda和firehose时遇到数据丢失的问题?
我目前正在向aws kinesis stream发送一系列xml消息,我已经在不同的项目中使用了它,所以我很有信心这一点是可行的。然后,我编写了一个lambda来处理从kinesis流到kinesis firehose的事件: 我已将kinesis流设置为lamdba触发器,并将批大小设置为1,起始位置设置为最新。 对于驱动消防软管,我有以下配置: 我发送了162个事件,我从s3中读取它们,最多的
-
Spark-Streaming Kafka直接流API及并行性
我理解了Kafka分区和Spark RDD分区之间的自动映射,并最终理解了Spark任务。然而,为了正确地调整我的执行器(核心数量)的大小,并最终确定节点和集群的大小,我需要理解文档中似乎掩盖了的一些内容。 null 例如,关于如何使用 --master local启动spark-streaming的建议。每个人都会说,在spark streaming的情况下,应该把local[2]最小化,因为其
-
在KCL的Kinesis中,stream的最新位置是如何工作的?
我们正在构建基于Kinesis/DynamoDB流的服务,我们对检查点的行为有以下问题。 我们有一个worker,它以以下配置开始,即InitialPositionInStream(InitialPositionInStream.LATEST),并且KCL应用程序的名称始终相同。 通过关闭和再次打开工作线程,我们观察到,它不会从流的末尾开始消耗,因为我们有一个滞后指标,我们看到,当工作线程打开时,
-
使用Dynamodb streams Kinesis适配器时,Kinesis客户端库使用者是否支持将AT\U时间戳作为起始位置
根据doc Dynamodb streams和Kinesis data streams,低级API是相似的,但它们并非完全相同。 我注意到Dynamodb流的GetShardIterator有点不同,即它不支持AT_TIMESTAMP作为分片迭代器类型。 所以,我 我的推理正确吗?我还没有实现它。如果这似乎是一个阻碍点,我宁愿寻找另一个解决方案。
-
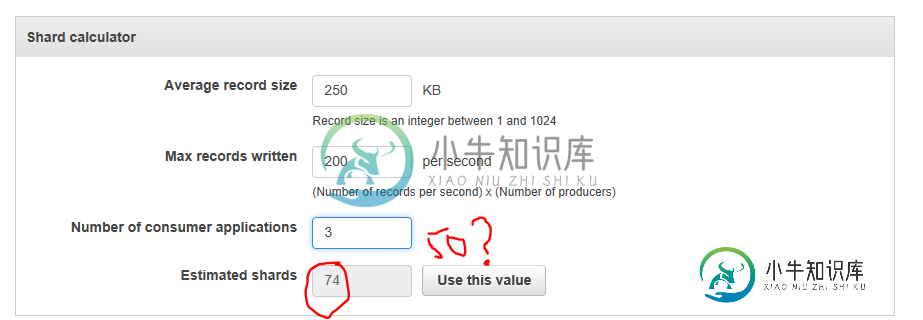 amazon streams动画片计数计算器公式如何工作
amazon streams动画片计数计算器公式如何工作我正在尝试学习aws运动流,并按照aws运动流留档。每个分片最多摄取1MB/秒或1000条记录/秒,并允许读取高达2MB/秒和每秒5个事务进行读取。 所以有人能解释一下这里的逻辑吗?谢谢。
-
使用功能接口创建的Spring cloud stream应用程序未在Spring cloud数据流中通信数据
我使用Spring云函数方法传输流量创建了3个简单的Spring云流应用程序(源/处理器/接收器)。 源应用程序: 处理器-应用程序: 下沉应用: 我添加的依赖项包括: 我已经在Spring云数据流中注册了这些应用程序,并部署在流中。 我能够单独通过HTTP和RabbitMQ将数据传输到这些应用程序并接收输出。但是,消息不会跨应用程序进行通信(Source- 当前我的应用程序属性文件完全为空。