
Spark Streaming-windows()是否缓存DStreams?

有人能解释一下Spark Streaming是如何执行window()操作的吗?从Spark 1.6.1文档来看,窗口批处理似乎会自动缓存在内存中,但从web UI来看,似乎会再次执行以前批处理中已执行的操作。为方便起见,我在下面附上了我正在运行的应用程序的屏幕截图:
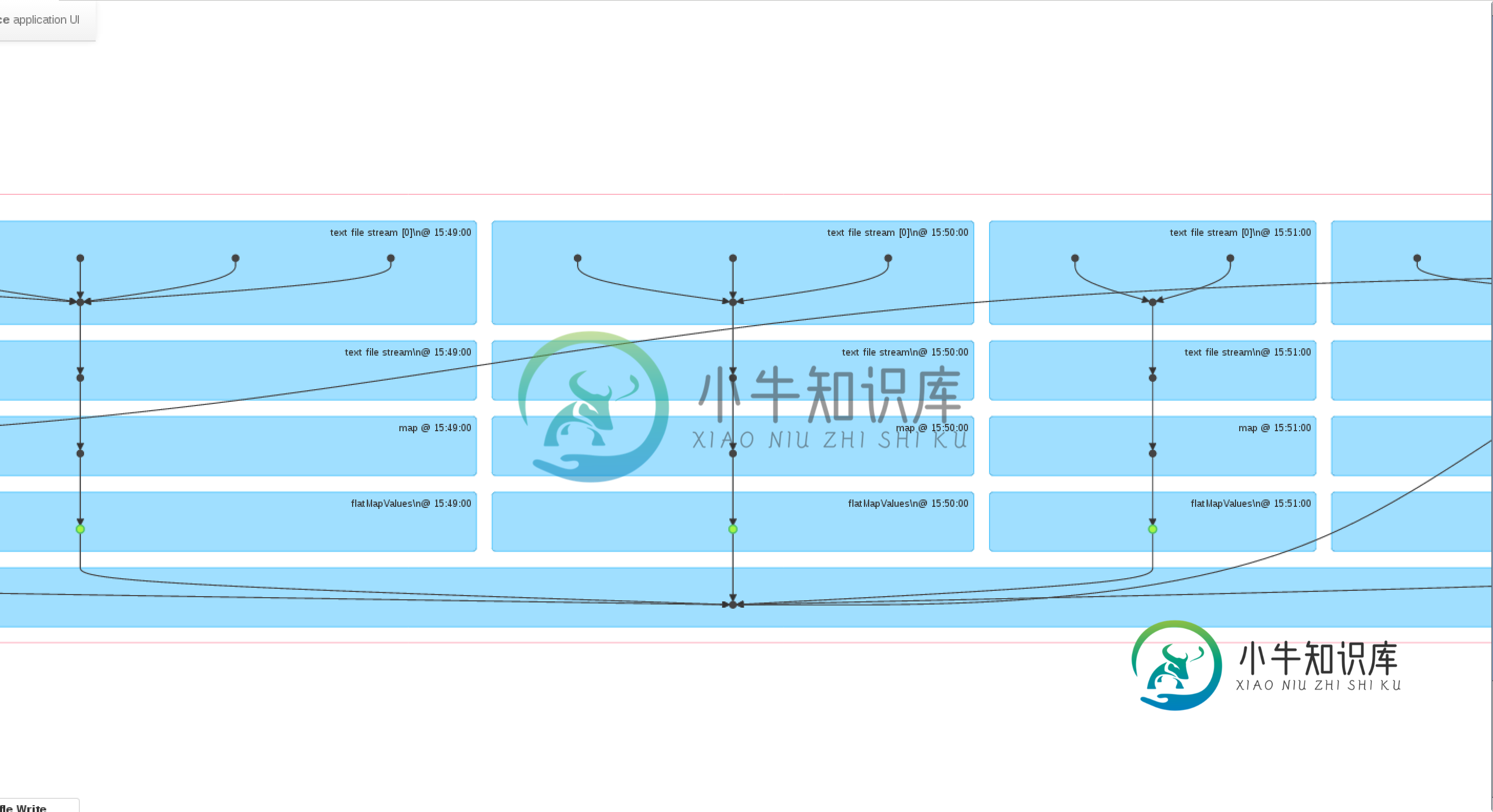
通过查看webUI,看起来好像是在缓存的是194 MapValures()RDD(绿点-这是我在DStream上调用windows()之前执行的最后一个操作),但是,与此同时,看起来也会再次执行之前批次中所有导致了194 MapValures()的转换。如果是这种情况,windows()操作可能会诱发巨大的性能损失,特别是如果窗口持续时间是1或2小时(正如我对我的应用程序所期望的那样)。你认为当时对DStream进行检查点会有所帮助吗?考虑一下预期的滑动窗口大约是5分钟。
希望有人能澄清这一点。
我添加了一个代码片段。Stream1和Stream2是从HDFS读取的数据馈送
JavaPairDStream<String, String> stream1 = cdr_orig.mapToPair(parserFunc)
.flatMapValues(new Function<String, Iterable<String>>() {
@Override
public Iterable<String> call(String s) {
return Arrays.asList(s.split(","));
}
}).window(Durations.seconds(WINDOW_DURATION), Durations.seconds(SLIDE_DURATION));
JavaPairDStream<String, String> join = stream2.join(stream1);
这两个流由另一个系统定期生成。这些流是异步的,这意味着时间t的stream 2中的记录出现在时间t的stream 1中。
共有1个答案

首先,yes window()通过对数据流调用persist来缓存它。这里的缓存是指数据保存在内存中。默认存储级别为StorageLevel。MEMORY\u ONLY\u SER,即。
将RDD存储为序列化Java对象(每个分区一个字节数组)。这通常比反序列化对象更节省空间,尤其是在使用快速序列化程序时,但读取起来更占用CPU。
窗口转换所做的是返回一个新的数据流,其中每个RDD包含在该数据流上的滑动时间窗口中看到的所有元素。在内部,它创建了一个WindowedDStream对象,该对象调用persist()来缓存数据流,根据Spark API文档,“它默认在父级持久化,因为这些RDD显然将被重用。”
所以,您不能依赖Window来缓存数据流。如果要减少转换,应该在转换之前和其他转换之前对该数据流调用persist()。
在您的情况下,请尝试调用persist,如图所示:
cdr_orig.persist(StorageLevel.MEMORY_AND_DISK);
在进行mapToPair变换之前。您将看到一个更紧凑的DAG将在顶部形成绿色圆点。
-
问题内容: 它可能是实现细节,但是对于Oracle和IBM JDK而言,至少是对已编译模式进行了缓存,还是作为应用程序开发人员我们需要自己对已编译模式进行缓存? 问题答案: 我不认为结果会被缓存,并且代码或文档中也没有这种行为的证据。自己实现这样的缓存(当然)是比较琐碎的,但是我对这样的缓存很有用的用例感兴趣。 回覆。下面的注释和String.split(),有一种不同的方法,即代码采用简单的1或
-
我注意到,每次我运行一个新作业时,它所花费的时间比我再次启动它时长20%左右? 如果一个作业运行多次,flink是否缓存一些结果并重用它们?如果是,我如何控制这一点? 我想测量我的任务运行了多长时间,但每次我重新运行它们时,速度都比以前快。
-
void is_cached(string template, [string cache_id]) This returns true if there is a valid cache for this template. This only works if caching is set to true. 在指定模板的缓存存在是返回真。只有在缓存设置为真时才可用。 Example 13-18
-
问题内容: 我想知道,您可以在现有缓存中调用的方法吗?还是在性能关键代码中最好将其存储在本地int中? 当您在调用之间不添加/删除项目时,我希望它确实已缓存。 我对吗? 更新 我不是在谈论内联或类似的东西。我只想知道方法本身是否在内部缓存值,或者每次调用时它都会动态计算。 问题答案: 我想我不会说它是“缓存的”-但是它只是存储在一个字段中,因此它足够快以经常调用。 Sun JDK的实现只是:
-
问题内容: 但 为什么仅在分配字符串时才获得相同的id()结果? 编辑:我用“字符串”代替“ ASCII字符串”。感谢您的反馈 问题答案: 这与ASCII与非ASCII无关(您的“非ASCII”仍然是ASCII,只是标点符号,而不是字母数字)。CPython作为实现细节,将仅包含“名称字符”的字符串常量进行实习。在这种情况下,“名称字符”与正则表达式转义的含义相同:字母数字加下划线。 注意:这可以
-
但是 为什么只有在赋值字符串时才能得到相同的id()结果? 编辑:我将“ascii字符串”替换为“字符串”。感谢您的反馈