《数据结构》专题
-
python dict到numpy结构化数组
问题内容: 我有一个字典,需要将其转换为NumPy结构化数组。我正在使用arcpy函数,因此NumPy结构化数组是唯一可以使用的数据格式。 我已经试过了: 但我不断 下面的方法有效,但是很愚蠢,显然不适用于真实数据。我知道有一个更优雅的方法,我只是想不通。 问题答案: 您可以使用: 产量 如果您不想创建元组的中间列表,则可以改用: 在Python2中: 在Python3中: 为什么使用该列表不起作
-
使用HiveQL爆炸结构数组
问题内容: 下面是表2中的数据 我可以使用以下查询来爆炸以上数据,并且对于以上数据也可以正常工作- 这样我会得到很好的输出 但是在某些情况下,我在下表中有这样的数据,对于相同的product_id- 我需要使用HiveQL查询为上述数据输出类似的结果- 这有可能做到这一点吗? 任何建议将不胜感激。 PS我几天前问这个问题,但是在这种情况下,数据是不同的,现在数据完全不同了,我需要类似的输出。 问题
-
javascript - 数组结构转为对象?
转为 用num作为key
-
启动参数总结
启动参数总结 -h, --help 打印帮助信息 --switch=SWITCH 交换机类型,包括 [kernel user ovsk] --host=HOST 模拟主机类型,包括 [process] --controller=CONTROLLER 控制器类型,包括 [nox_dump none ref remote nox_pysw] --topo=TOPO,arg1,arg2,...argN
-
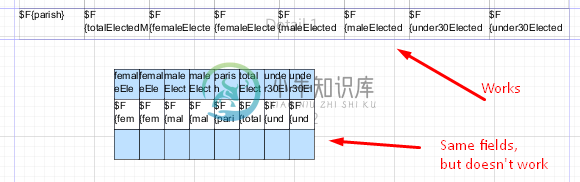 将数据从主数据集传递到表数据集
将数据从主数据集传递到表数据集我正在使用一个表在Jaspersoft Studio 5.6.1中创建简单的报告。 通过 JRBeanCollectionDataSource 从 Java 向此报告发送数据。 在报告中,我已经可以获取此数据 vie 字段:报告- 现在我可以显示输入的数据了。 但如果我想在表中执行,我需要创建数据集(为什么?)并选择“使用用于填充主报告的相同连接”。将相同的字段添加到新数据集没有帮助,也没有为数据
-
将数据库架构复制到现有数据库
问题内容: 我正在使用Microsoft Sql Server Management Studio。我目前有一个包含数据的现有数据库,我将其称为DatabaseProd。我还有一个第二个数据库,其中包含用于测试的数据,因此数据既不完全正确也不是最新的。我将这个数据库称为DatabaseDev。 但是,DatabaseDev现在包含新添加的表和新添加的列等。 我想将此新模式从DatabaseDev复
-
如果您想成为Java / C ++程序员,是否必须学习数据结构?
问题内容: 那么,我真的需要了解它们吗?有没有一种有趣的方法来学习堆栈,链接列表,堆等?我觉得这很无聊。 **发布此问题时,它显示了一些警告。我不可以发布这样的问题吗?管理员请澄清,我将其删除:/ 警告::您要提出的问题似乎很主观,很可能已被关闭。 好吧..我明白了,学习它们的最好方法是什么?我要看什么书?什么网站? 问题答案: 如果您想成为一名程序员,则必须学习数据结构。数据结构是您的基础,如果
-
将数据结构持久保存到python中的文件的最简单方法?
问题内容: 假设我有这样的事情: 通过 编程 将其 打包 到以后可以从python加载的文件中,最简单的方法是什么 ? 我可以以某种方式将其另存为python源(从python脚本中,而不是手动!),然后再保存吗? 还是应该使用JSON之类的东西? 问题答案: 使用泡菜模块。
-
第三章 计算机程序的构造和解释 - 3.3 递归数据结构
在第二章中,我们引入了偶对的概念,作为一种将两个对象结合为一个对象的机制。我们展示了偶对可以使用内建元素来实现。偶对的封闭性表明偶对的每个元素本身都可以为偶对。 这种封闭性允许我们实现递归列表的数据抽象,它是我们的第一种序列类型。递归列表可以使用递归函数最为自然地操作,就像它们的名称和结构表示的那样。在这一节中,我们会讨论操作递归列表和其它递归结构的自定义的函数。 递归列表结构将列表表示为首个元素
-
如何在SQL中以树状结构汇总从子级到父级的数据?
问题内容: 我有一个查询,用于选择树状结构中每个部门的金额。我想在各自的父母上显示孩子的总和。 是否可以在不使用游标的情况下将其归档在查询中? 以下是要汇总的数据的结果集。完整示例也可以在sqlfiddle上找到。 结果 : 问题答案: 这将获得完整的报告 第一个查询通过修改不包含金额的分部的部门名称结构来获得滚动总和,第二个查询获得叶子。 第一个查询无法显示叶子,因为它们将被分组。我还没有找到任
-
如何从Kafka读取JSON数据并使用Spark结构化流存储到HDFS?
我正在尝试从Kafka读取JSON消息并将它们存储在具有火花结构化流的HDFS中。 我遵循了下面的示例,当我的代码如下所示时: 然后我得到hdfs中具有二进制值的行。 这些行按预期连续写入,但采用二进制格式。 我发现了这个帖子: https://databricks.com/blog/2017/04/26/processing-data-in-apache-kafka-with-structure
-
用于检查项目是否在间隔范围内的概率数据结构
我正在尝试解决以下问题: 给定一组区间[[s1,e1],[s2,e2],[s3,e3],[s4,34],…]如果每个间隔由开始和结束组成,并且所有间隔都是不相交的,则说明点X是否属于其中一个间隔,是否在允许误报但不允许误报的恒定时间内,并使用与输入无关的恒定内存量[此类散列等…] 因此,bloom filter主要可用于点查询,但将每个点存储在bloom filter中的时间间隔中效率不高,使用T
-
有效计算动态有向无环图上可达权和的数据结构
我有一个有向无环图,其中每个顶点都有一个“权重”属性。初始顶点的可达顶点是从初始顶点开始跟随一条或多条边可达的所有顶点的集合。可达权重和是初始顶点可达顶点上所有权重的总和。此外,我可以随意向图中添加有向边和顶点,但图将始终保持无环。 我是否可以使用任何数据结构来扩充图,这些数据结构将有助于从任何给定的初始顶点有效计算可达权重和,并且在图更新时可更新?
-
在endpoint和元素之前/之后以恒定时间插入的数据结构?
我正在寻找一种数据结构: 具有无界的大小。 保持其元素的插入顺序。 在列表的开头和结尾有效地插入(理想情况下为常量时间)。 在现有元素之前或之后有效地插入(理想情况下是在恒定时间内)。 我排除了,因为它在列表开头插入时效率不高。 表面上应该是一个完美的匹配,但实际上Java实现在插入现有元素之前或之后并不有效(即它遍历整个列表以查找插入位置)。 (我个人不需要存储重复的元素,但其他人可能会) 动机
-
如何在0的数据库表结构中引入新概念。。1个实例?
我遇到了一个新需求问题,不知道如何最好地构造数据库表。基本情况如下: 我将员工存储在员工表中。由于产量增加,该公司不得不雇用许多临时雇员。所有这些员工,包括长期员工和临时员工,都必须将数据输入ERP系统。因此,从本质上讲,员工将输入“Orders”,Orders表有一个名为“EnteredBy”的字段。在理想情况下,我会将这两种类型的员工都存储在employees表中。 由于公司的不同系统和公司内