《数据结构》专题
-
C语言数据结构之学生信息管理系统课程设计
本文向大家介绍C语言数据结构之学生信息管理系统课程设计,包括了C语言数据结构之学生信息管理系统课程设计的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了学生信息管理系统设计的具体代码,供大家参考,具体内容如下 建立一个动态链表,链表中每一结点包括:学号、姓名、性别、年龄、成绩。程序能实现以下功能: 建立链表 显示链表 查找链表中是否存在某个元素,并显示这个
-
C++ 数据结构之对称矩阵及稀疏矩阵的压缩存储
本文向大家介绍C++ 数据结构之对称矩阵及稀疏矩阵的压缩存储,包括了C++ 数据结构之对称矩阵及稀疏矩阵的压缩存储的使用技巧和注意事项,需要的朋友参考一下 对称矩阵及稀疏矩阵的压缩存储 1.稀疏矩阵 对于那些零元素数目远远多于非零元素数目,并且非零元素的分布没有规律的矩阵称为稀疏矩阵(sparse)。 人们无法给出稀疏矩阵的确切定义,一般都只是凭个人的直觉来理解这个概念,即矩阵中非零元素的个
-
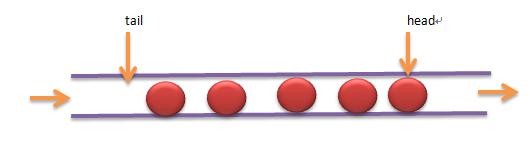 PHP 数据结构队列(SplQueue)和优先队列(SplPriorityQueue)简单使用实例
PHP 数据结构队列(SplQueue)和优先队列(SplPriorityQueue)简单使用实例本文向大家介绍PHP 数据结构队列(SplQueue)和优先队列(SplPriorityQueue)简单使用实例,包括了PHP 数据结构队列(SplQueue)和优先队列(SplPriorityQueue)简单使用实例的使用技巧和注意事项,需要的朋友参考一下 队列这种数据结构更简单,就像我们生活中排队一样,它的特性是先进先出(FIFO)。 PHP SPL中SplQueue类就是实现队列操作,和栈一
-
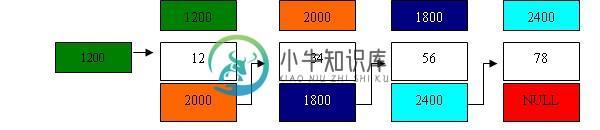 C语言创建和操作单链表数据结构的实例教程
C语言创建和操作单链表数据结构的实例教程本文向大家介绍C语言创建和操作单链表数据结构的实例教程,包括了C语言创建和操作单链表数据结构的实例教程的使用技巧和注意事项,需要的朋友参考一下 1,为什么要用到链表 数组作为存放同类数据的集合,给我们在程序设计时带来很多的方便,增加了灵活性。但数组也同样存在一些弊病。如数组的大小在定义时要事先规定,不能在程序中进行调整,这样一来,在程序设计中针对不同问题有时需要3 0个大小的数组,有时需要5 0个
-
Firebase数据已标准化。我应如何基于此结构获取集合?
问题内容: 我想我已经接近了,我能够打印出属于用户的书的ID,但一直尝试从Firebase图书参考中获取属于用户的书的列表失败。 我在这里大致遵循该教程:http : //www.thinkster.io/pick/eHPCs7s87O/angularjs-tutorial-learn-to-rapidly-build- real-time-web-apps-with- firebase#item
-
存储一组四个(或更多)值的最佳数据结构是什么?
问题内容: 说我有以下内容及其对应的内容,它们代表一个。 请注意,可能是不同的(,,,引用到任何-其他对象,等等)。 将会有很多(至少> 100,000)。当所有这四个(实际上是)放在一起时,每个都会。换句话说,不存在与所有4个相同的事物。 我试图找到一个高效的数据结构,这将让我(商店)获取基于其中任何一项的时间复杂度。 例如: 的调用方式如下: 以上应该返回 以上应该返回 而且,将来我可能需要在
-
面向微服务体系结构的分布式数据库设计风格
另一种方式,我认为是水平分割当前结构。所以我的领域是基于一些教育大学。因此,一半的大学低于一分贝,剩下的将低于另一分贝。并根据两个地区部署服务(两个针对两套大学)。 目前,我决定继续采用最后提到的方法。我对这些类型的任务是新的,因为它涉及一些体系结构任务。我也是微服务和分布式数据库领域的初学者。有人能证实我的方法能解决我的问题吗?我可以继续我的第二种方法--根据域对象对数据库进行水平分区吗?
-
 JavaScript数据结构与算法之队列原理与用法实例详解
JavaScript数据结构与算法之队列原理与用法实例详解本文向大家介绍JavaScript数据结构与算法之队列原理与用法实例详解,包括了JavaScript数据结构与算法之队列原理与用法实例详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript数据结构与算法之队列原理与用法。分享给大家供大家参考,具体如下: 队列是一种列表,不同的是队列只能在队尾插入元素,在队首删除元素。队列用于存储按顺序排列的数据,先进先出,这点和栈不一样(
-
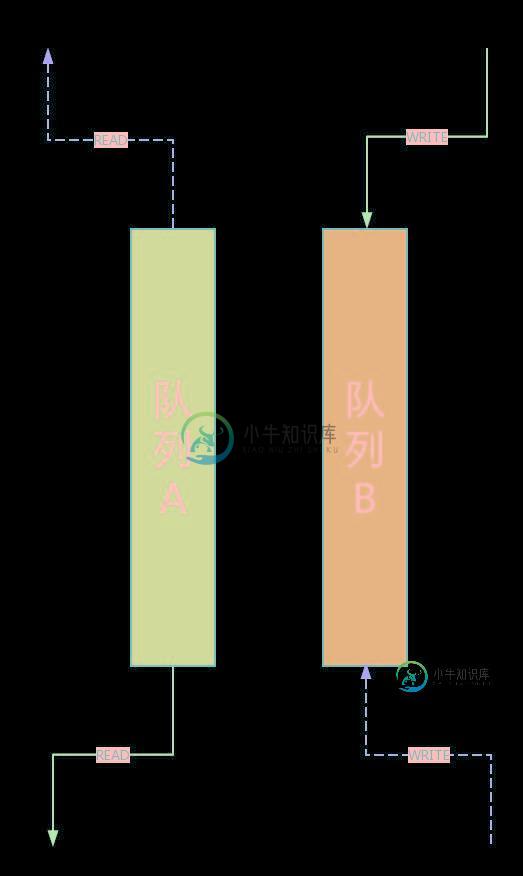 C++数据结构与算法之双缓存队列实现方法详解
C++数据结构与算法之双缓存队列实现方法详解本文向大家介绍C++数据结构与算法之双缓存队列实现方法详解,包括了C++数据结构与算法之双缓存队列实现方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C++数据结构与算法之双缓存队列实现方法。分享给大家供大家参考,具体如下: “双缓存队列”是我在一次开发任务中针对特殊场景设计出来的结构。使用场景为:发送端持续向接收端发送数据包——并且不理会接收端是否完成业务逻辑。由于接收端在任何情
-
如何将spark结构化流数据重置为上次可用偏移量
我正在用Kafka运行一个结构化流应用程序。我发现如果系统因为某种原因停机几天...检查点变得过时,并且在Kafka中找不到与该检查点相对应的偏移量。我如何让Spark结构化流应用程序选择最后一个可用的偏移量,并从那里开始。我尝试将偏移量重置设置为“早期/最新”,但系统崩溃,出现以下错误:
-
搜索用于存储和检索元素的完美数据结构[复制]
我必须选择一个数据结构为我的需要下面我解释的条件有以下值 现在,举个例子,如果我得到了ytr,那么我将能够检索到R1B1,或者,假设,我得到了rGGty的值,那么我将能够检索到R1B2 现在的情况是,重要的是搜索、复杂性和事情按顺序进行所需的时间 例如,它将首先选择要搜索的第一行,它将首先与不匹配的匹配,然后必须与匹配,然后再与不匹配的匹配,最后与匹配,最后找到键 类似地,如果需要搜索第二个字符串
-
具有快速排序插入、排序删除和查找的数据结构
我正在寻找一个非常具体的数据结构。假设已知元素的最大数量。所有元素都是整数。允许复制。行动包括: 查阅如果我插入n个元素,是最小的元素,是最高的元素是k个最小的元素。所需运行时间: 插入。执行排序的插入,其中是一个整数。所需的运行时: 删除。删除(i)删除第i个元素。所需的运行时: 我想要一种数据结构,是这样吗?我的问题与语言无关,但我用C语言编写代码。
-
具有O(1)插入和O(log(n))搜索复杂性的数据结构?
即使在最坏的情况下,是否有任何数据结构可以提供O(1)——即常数——插入复杂性和O(log(n))搜索复杂性? 排序后的向量可以进行O(log(n))搜索,但插入需要O(n)(考虑到我并不总是在前面或后面插入元素这一事实)。而列表可以进行O(1)插入,但不能提供O(log(n))查找。 我想知道这样的数据结构是否可以实现。
-
Java数据结构,保持自然秩序,并提供访问索引?[复制]
我正在研究一个编码面试,发现了一个问题,从时间复杂性方面来说,它将从像这样的数据结构中受益匪浅,但它允许通过索引获取元素。类似地,允许插入的在保持自然秩序的同时也会起作用。Java中有这样的数据结构吗?
-
弹性搜索--用弹性C#API处理原始JSON(非结构化数据)
我们正在开发一个应用程序,在这个应用程序中,我们从不同的源和不同的格式接收json格式的数据,用户也可以将这些源添加到自己的那里,所以我们不知道json格式会有什么属性 我们的应用程序将该数据表示为网格格式,网格提供了对该数据的过滤、排序、分页、分组等标准操作。 我们决定使用弹性搜索来存储如此大的、非结构化的数据。在后端,我们使用。NET(C#)。 开始使用大容量API对数据进行索引。下面是示例j