《数据结构》专题
-
在Go中实现Merkle-tree数据结构
问题内容: 我目前正在尝试在Go中实现Merkle- tree数据结构。基本上,我的最终目标是存储一小组结构化数据(最大10MB),并使该“数据库”可以轻松地与网络上分布的其他节点同步(请参阅参考资料)。由于没有类型检查,因此我已经在Node中有效地实现了这一点。这就是Go的问题,我想利用Go的编译时类型检查,尽管我也想拥有一个可以与任何提供的树一起使用的库。 简而言之,我想将结构用作merkle
-
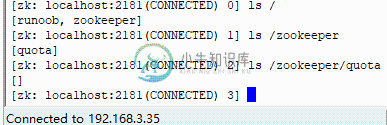 5.0 ZooKeeper 数据模型 znode 结构详解
5.0 ZooKeeper 数据模型 znode 结构详解数据模型 在 zookeeper 中,可以说 zookeeper 中的所有存储的数据是由 znode 组成的,节点也称为 znode,并以 key/value 形式存储数据。 整体结构类似于 linux 文件系统的模式以树形结构存储。其中根路径以 / 开头。 进入 zookeeper 安装的 bin 目录,通过sh zkCli.sh打开命令行终端,执行 "ls /" 命令显示: 我们直观的看到此时
-
如何实现这个数据库结构?
我想创建一个食谱网站,在那里你可以添加/修改/删除食谱,每个模型都应该有一个配料的列表,与所需的量的那个配料。 我试图使用这样的dict:,但结果是EF Core并不真正喜欢dicts的思想,所以我试图创建一个“映射器”模型,如下所示: 问题是,它仍然没有真正起作用。我不能添加菜谱,也不能删除,因为它进入了一个永远循环。 你将如何实施它? 谢谢
-
如何使用MongoDB构造数据结构?
商店1 第1节 第2节 2号商店 null null null 我会在'store'属性中设置区段,因为不同的商店有不同的区段。 到目前为止我认为一切都是正确的。我的问题是如何将用户分配到商店中的特定区段。会是user.company.store[3].section[1]吗?如果一个节/存储区被删除,那么节/存储区的indexOf值不会改变吗?人们通常是怎么做这样的事情的?我基本上是在创建与文件
-
3.22.有序列表抽象数据结构
我们现在将考虑一种称为有序列表的列表类型。例如,如果上面所示的整数列表是有序列表(升序),则它可以写为 17,26,31,54,77和93。由于 17 是最小项,它占据第一位置。同样,由于 93 是最大的,它占据最后的位置。 有序列表的结构是项的集合,其中每个项保存基于项的一些潜在特性的相对位置。排序通常是升序或降序,并且我们假设列表项具有已经定义的有意义的比较运算。许多有序列表操作与无序列表的操
-
8.11 简化数据结构的初始化
问题 你写了很多仅仅用作数据结构的类,不想写太多烦人的 __init__() 函数 解决方案 可以在一个基类中写一个公用的 __init__() 函数: import math class Structure1: # Class variable that specifies expected fields _fields = [] def __init__(self,
-
如何从Python读取Perl数据结构?
问题内容: 我经常看到人们使用Perl数据结构代替配置文件。即一个仅包含以下内容的独立文件: 使用纯Python将这些文件的内容转换为等效于Python的数据结构的最佳方法是什么?目前,我们可以假设没有要评估的真实表达式,只有结构化数据。 问题答案: 不知道用例是什么。这是我的假设:您将要进行一次从Perl到Python的转换。 Perl有这个 在Python中, 所以,我想这是一堆可替换的RE
-
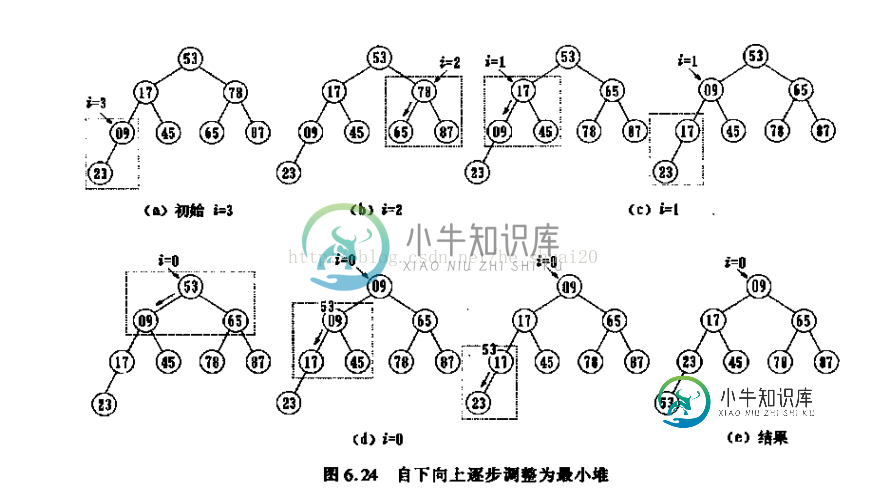 C++ 数据结构 堆排序的实现
C++ 数据结构 堆排序的实现本文向大家介绍C++ 数据结构 堆排序的实现,包括了C++ 数据结构 堆排序的实现的使用技巧和注意事项,需要的朋友参考一下 堆排序(heapsort)是一种比较快速的排序方式,它的时间复杂度为O(nlgn),并且堆排序具有空间原址性,任何时候只需要有限的空间来存储临时数据。我将用c++实现一个堆来简单分析一下。 堆排序的基本思想为: 1、升序排列,保持大堆;降序排列,保持小堆; 2、建立堆之后,将
-
C++ 数据结构之布隆过滤器
本文向大家介绍C++ 数据结构之布隆过滤器,包括了C++ 数据结构之布隆过滤器的使用技巧和注意事项,需要的朋友参考一下 布隆过滤器 一、历史背景知识 布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远超过一般的算法,缺点是有一定的误识别率和删除错误
-
调整SQLServer2000运行中数据库结构
本文向大家介绍调整SQLServer2000运行中数据库结构,包括了调整SQLServer2000运行中数据库结构的使用技巧和注意事项,需要的朋友参考一下 开发过程中的数据库结构结构,不可避免的会需要反复的修改。最麻烦的情况莫过于开发者数据库结构已经修改,而实际应用中数据库又有大量数据,如何在不影响 数据库中数据情况下,更新数据结构呢?当然,我们可以手工对应用数据库表结构各个添加、更正、删除的字段
-
数据结构中的区域四叉树
本文向大家介绍数据结构中的区域四叉树,包括了数据结构中的区域四叉树的使用技巧和注意事项,需要的朋友参考一下 区域四叉树可用于通过将区域划分为四个相等的象限,子象限等,以二维方式表示空间分区,每个叶节点由对应于特定子区域的数据组成。树中的每个节点都与正好有四个子节点或没有子节点(叶节点)相关联。遵循这种分解策略的四叉树的高度(即细分子象限,直到并且除非子象限中有需要进一步完善的有趣数据为止)敏感并取
-
数据结构中的希尔伯特树
本文向大家介绍数据结构中的希尔伯特树,包括了数据结构中的希尔伯特树的使用技巧和注意事项,需要的朋友参考一下 希尔伯特R树是R树的变体,被定义为多维对象的索引,例如线,区域,3-D对象或基于高维特征的参数对象。可以将其想象为对多维对象的B +树的扩展。 R树的性能取决于将数据矩形聚集在节点上的算法的质量。Hilbert R树实现了空间填充曲线,特别是Hilbert曲线,用于对数据矩形强加线性排序。
-
数据结构中的时空复杂性
本文向大家介绍数据结构中的时空复杂性,包括了数据结构中的时空复杂性的使用技巧和注意事项,需要的朋友参考一下 算法分析 可以在实施之前和实施之后的两个不同阶段进行算法效率分析,如下 先验分析-这被定义为算法的理论分析。通过假设所有其他因素(例如处理器速度)是恒定的,并且对实现没有影响,来衡量算法的效率。 后验分析-定义为算法的经验分析。所选算法是使用编程语言实现的。接下来,所选算法在目标计算机上执行
-
 获取Lua表结构table数据实例
获取Lua表结构table数据实例本文向大家介绍获取Lua表结构table数据实例,包括了获取Lua表结构table数据实例的使用技巧和注意事项,需要的朋友参考一下 只是获取一个全局变量什么的太没意思了,今天我们来玩个高难度的——获取Lua表结构的数据。 (旁白:O O!我是不是该说点什么?) 1. 什么是table table是Lua里最强大的数据类型,我们可以当成是数组,但是它又和数组有点不一样,建议大家看看Lua的语法教程,
-
AngularJS数据结构:客户端还是API?