《架构思维》专题
-
 字节网络开发——系统架构面经
字节网络开发——系统架构面经7.22一面 项目: 介绍下项目,交流下他们部门主要做的,好像有重合,但是做的不太一样(网络监控、流量调度),流长对应到的实际问题场景是什么 C++ new和malloc的区别。延申问了vector中的allocator。 vector是怎么开辟空间的,适用什么场景。 map和set的底层以及区别。 动态链接库和静态链接库的区别,在实际应用中如何考虑,一般情况下内存充足,保证应用程序时间响应 操作
-
3.1.2 电商网站详情页系统架构
电商网站的商品详情页系统架构 小型电商网站的商品详情页系统架构 小型电商网站的页面展示采用页面全量静态化的思想。数据库中存放了所有的商品信息,页面静态化系统,将数据填充进静态模板中,形成静态化页面,推入 Nginx 服务器。用户浏览网站页面时,取用一个已经静态化好的 html 页面,直接返回回去,不涉及任何的业务逻辑处理。 下面是页面模板的简单 Demo 。 <html> <body>
-
架构比MVC更适合Web应用程序?
问题内容: 我一直在为我的新工作学习Zend及其MVC应用程序结构,发现与它一起工作只会使我感到困扰,原因是我无法完全动手。然后在学习过程中,我遇到了诸如MVC:NoSilverBullet之类的文章,以及有关MVC和Web应用程序的播客。播客中的那个人非常反对将MVC作为Web应用程序体系结构,并钉住了很多困扰我的东西。 但是,问题仍然存在,如果MVC并非真的很适合Web应用程序,那是什么? 问
-
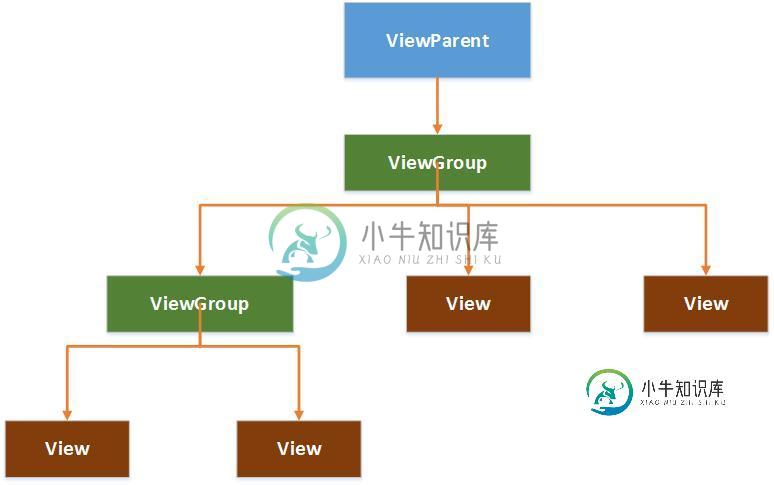 Android视图控件架构分析之View、ViewGroup
Android视图控件架构分析之View、ViewGroup本文向大家介绍Android视图控件架构分析之View、ViewGroup,包括了Android视图控件架构分析之View、ViewGroup的使用技巧和注意事项,需要的朋友参考一下 在Android中,视图控件大致被分为两类,即ViewGroup和View,ViewGroup控件作为父控件,包含并管理着子View,通过ViewGroup和View便形成了控件树,各个ViewGoup对象和View
-
MongoDB-错误:无效的架构,预期的mongodb
问题内容: 我是使用MEAN Stack构建应用程序的新手,我正在尝试构建实时聊天应用程序,这是我的服务器端: 我确定我创建了一个与mongodb聊天的数据库,mongo也正在等待连接。但是当我使用节点server.js运行服务器时,会发生错误: 在这个阶段,我被封锁了几个星期,有人可以帮忙吗? 谢谢。 问题答案: 这是因为您使用的连接字符串格式不正确。 您正在使用它应该是 连接字符串的模式是 供
-
错误:尚未为模型“项”注册架构
我知道以前有人问过这个问题,但我找不到适合我的问题。我正在使用mongo为我的项目创建模式并创建路由,但由于某些原因,它一直给我一个错误。 扔新的猫鼬。错误。MissinSchemaError(名称);^MongooseError[MissinSchemaError]:模式尚未注册为模型“项目”。使用mongoose.model(名称,模式)在Mongoose.model(C:\用户\samib\
-
Laravel框架查询构造器简单示例
本文向大家介绍Laravel框架查询构造器简单示例,包括了Laravel框架查询构造器简单示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Laravel框架查询构造器。分享给大家供大家参考,具体如下: 更多关于Laravel相关内容感兴趣的读者可查看本站专题:《Laravel框架入门与进阶教程》、《php优秀开发框架总结》、《php面向对象程序设计入门教程》、《php+mysql数据库
-
Spring->Oracle存储过程调用架构问题
作为重构的一部分,我正在尝试将数据库调用更改为使用Spring 4.1.0。释放以处理连接和异常,并允许在函数和类之间传递结果集。 我的MS SQL Server存储过程调用工作正常,但当我尝试执行Oracle存储过程时,收到以下错误消息: 我通过编写两个非常简单的写入测试表的存储过程来简化问题:一个接受参数并写入,另一个不接受参数,只写入硬编码值。这些过程位于INV模式中,这是我的数据源配置使用
-
无法使用SYS架构执行flyway迁移
我的许多迁移脚本中的第一个创建了模式和表空间,其余的迁移脚本在其中创建表、执行插入等。这样做是为了删除整个模式,然后使用flyway从头开始。cmd flyway migrate命令连接为“SYS as SYSDBA”,验证我的迁移文件,然后给出以下错误: 错误:找到不带元数据表的非空架构“SYS”!使用baseline()或将baselineOnMigrate设置为true来初始化元数据表。 在
-
在Spring启动时在postgres中创建架构
当Spring启动加载时,我需要在Postgres中创建一个新模式。因此,它应该检查模式是否不存在,然后创建一个新模式。我正在使用application.properties进行数据库配置。 Postgres使用的默认模式是公共的,我需要更改使我自己的模式,我将在env中定义。
-
架构在使用SSE/AVX Intrinisics时的影响
我想知道编译器是如何处理内部函数的。 如果使用SSE2内部函数(使用代码),则包括 如果使用AVX2内部函数(使用代码),则包括 编译器如何处理内部函数 如果使用内部函数,是否有助于编译器理解循环中的依赖关系以更好地进行矢量化? 例如,这里发生了什么-https://godbolt.org/z/Y4J5OA(或https://godbolt.org/z/LZOJ2K)? 查看所有3个窗格。 我正在
-
在tomcat context.xml中指定Oracle DB/架构名称
我正试图在Tomcat中添加JDBC会话持久性,正如这里所解释的:Tomcat链接我在Oracle中的my_schema数据库/schema中创建了一个会话表,并试图将其映射到Tomcat context.xml中。我的映射如下:
-
如何连接融合云架构注册表?
我正在使用ConFluent托管的Kafka集群和Schema注册表服务。我可以管理连接汇合云kafka集群,将以下属性添加到生产者配置(Scala) 但是不能连接到汇合云模式注册表。汇合云模式注册表提供了访问的键和秘密,但我不知道如何设置键和秘密。是否有任何配置设置用于访问汇合云模式注册表。
-
30小时以上查询的最佳架构
问题内容: 我有一个有趣的问题要解决。我的一位客户让我开发了一个库存分析程序,该程序具有将近50年的库存数据以及近一千个交易品种。我已经开发了一系列过滤器,可在任何一天应用,以查看是否有任何交易失败。 我们希望针对每个库存的每天数据运行此过滤器。基本上,您的开始日期和结束日期类型报告。但是,每个符号每周需要花费6分钟进行过滤。我们估计大约需要40个小时才能对整个数据集运行报告。 首要要求是我的客户
-
如何引用与属性相同的架构?
我的办公自动化系统中有以下内容。yaml文件: 它不喜欢“description:”这句话:如果有内部异常,那么内部异常。如果我去掉这个,它就不喜欢“属性:”。我尝试了很多东西,但都不管用。我不明白什么?