《高可用》专题
-
高可用原理 - 发现原理
Sentinel发现分为发现从服务器和发现其他sentinel服务两类: Sentinel实例可以通过询问主实例来获得所有从实例的信息 Sentinel进程可以通过发布与订阅来自动发现正在监视相同主实例的其他Sentinel,每个 Sentinel 都订阅了被它监视的所有主服务器和从服务器的 __sentinel__:hello 频道, 查找之前未出现过的 sentinel进程。 当一个 Sent
-
第 22 章 高可用性模式
注意 The High Availability features are only available in the Neo4j Enterprise Edition. Neo4j High Availability or “Neo4j HA” provides the following two main features: 1.It enables a fault-tolerant data
-
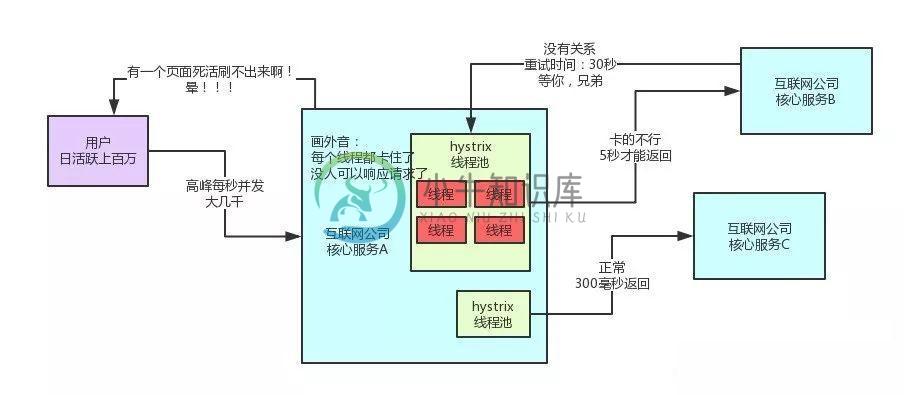 你的系统该怎么抗高并发还能高可用?
你的系统该怎么抗高并发还能高可用?主要内容:一、概述,二、业务场景介绍,三、线上经验—如何设置Hystrix线程池大小,四、线上经验—如何设置请求超时时间,五、服务降级,六、总结一、概述 上一篇文章讲了一个朋友公司使用Spring Cloud架构遇到问题的一个真实案例,虽然不是什么大的技术问题,但如果对一些东西理解的不深刻,还真会犯一些错误。 如果没看过上一篇文章的朋友,建议先看看:《我进了新公司结果不会用SpringCloud,人生第一次被辞退了!》因为本文的案例背景会基于上一篇文章。 这篇文章我们来聊聊在微服务架构中,到底如
-
2.1 服务发现 - 2.1.6 Consul高可用
Consul Cluster集群架构图如下: 这边准备了三台CentOS 7的虚拟机,主机规划如下,供参考: 主机名称 IP 作用 是否允许远程访问 node0 192.168.11.143 consul server 是 node1 192.168.11.144 consul client 否 node2 192.168.11.145 consul client 是 搭建步骤: 启动node0机
-
 详解Keepalived+Nginx实现高可用(HA)
详解Keepalived+Nginx实现高可用(HA)本文向大家介绍详解Keepalived+Nginx实现高可用(HA),包括了详解Keepalived+Nginx实现高可用(HA)的使用技巧和注意事项,需要的朋友参考一下 keepalived的HA分为抢占模式和非抢占模式,抢占模式即MASTER从故障中恢复后,会将VIP从BACKUP节点中抢占过来。非抢占模式即MASTER恢复后不抢占BACKUP升级为MASTER后的VIP。下面分别介绍Cent
-
Redis发布/订阅和高可用性
目前,我正在开发一个分布式测试执行和报告系统。我计划将Redis PUB/SUB用作消息队列和消息分发系统。 我是Redis的新手,所以我试着阅读尽可能多的文档,并尝试着使用它。最重要的主题之一是高可用性。正如我所说,我不是专家,但我知道可能的选择——使用Sentinel、复制、集群等。 我不清楚的是Pub/Sub功能和HA选项是如何相互关联的。使用Redis构建可靠消息传递系统的最佳实践是什么?
-
使用 Heartbeat 构建高可用服务
Even in the future, nothing works! — Spaceballs 一切迟早都会发生故障。高可用服务就是指当一个主机或网络线路失效时仍旧能够提供服务。 高可用性的主要技术就是冗余,另外,这个问题的解决就是以投放更多硬件设备而著称的。 虽然最终肯定会有单独的一台服务器失效,但是两台服务器同时失效的概率是不太高的, 这对大多数的应用程序提供了一个良好的冗余水平。 最简单的方
-
html高效可伸缩表列
我正在尝试创建一个带有可伸缩列的动态html表。在实际情况下,我可以有20列每个标题和最多400个值。我想这样呈现数据: 我希望能够点击和colx.1,展开或显示同一标题下的所有列,折叠(或隐藏)其他标题的其他列。在上表中单击任何COL2.1单元格,然后将该表更改为: 我试着做了这样的事情:在所有可以显示/隐藏的td元素上使用hideable类,并且做了这样的事情: 我还需要相应地更改页眉和页脚的
-
可见时更新JPopupMenu高度
我的应用程序中有一个弹出菜单,我想用一个自定义的菜单替换它,这样它就能与应用程序的其他部分相匹配。从本质上说,我不想在弹出窗口中使用普通的菜单项,而是想重用应用程序中其他地方已经存在的组件,该组件允许您以“分页”的方式而不是子菜单来导航项的层次结构。因此,如果单击列表中包含子项的项,则将显示下一页,用所单击项的子项列表替换列表中的当前项。 当运行上面的示例时,您将看到,如果在单击内部面板后关闭和打
-
具有高可用性的嵌入式Neo4j
我在一个POC中使用了最近嵌入的Spring数据Neo4j。它在一台机器上快速工作。在投入生产之前,我想将数据库与应用服务器分离。我配置了三个Neo4j服务器实例和HA代理,并使用Spring数据Neo4j Rest进行连接。但速度最差。每个查询的执行时间超过30秒。 我正在考虑使用嵌入HA的Neo4j?有人能给我提供链接/教程,用HA代理在嵌入式模式下配置Spring Data Neo4j吗。
-
基于 Zookeeper 搭建 Kafka 高可用集群
一、Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群。 1.1 下载 & 解压 下载对应版本 Zookeeper,这里我下载的版本 3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/ # 下载 wget https://archive.apache.
-
基于 Zookeeper 搭建 Spark 高可用集群
一、集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 和 hadoop003 上分别部署备用的 Master 服务,Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Mas
-
基于 Zookeeper 搭建 Hadoop 高可用集群
一、高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解: 1.1 高可用整体架构 HDFS 高可用架构如下: 图片引用自:https://www.edureka.
-
2.1 服务发现 - 2.1.2 Eureka的高可用
按照前文对Eureka的讲解,我们即可构建出一个简单的注册中心。但此时的Eureka是单点的,不适合于生产环境,那幺如何实现Eureka的高可用呢? 添加主机名: 127.0.0.1 peer1 peer2 修改application.yml --- spring: profiles: peer1 # 指定profile=peer
-
 keepalived+nginx高可用实现方法示例
keepalived+nginx高可用实现方法示例本文向大家介绍keepalived+nginx高可用实现方法示例,包括了keepalived+nginx高可用实现方法示例的使用技巧和注意事项,需要的朋友参考一下 1.keepalived介绍 keepalived最初是专为LVS负载均衡软件设计的,用来管理并监控LVS集群系统中各个服务节点的状态,后来又加入了实现高可用的VRRP功能。keepalived除了能够管理LVS软件外,还能支持其他服务