《高并发》专题
-
Laravel合并关系
问题内容: 有没有办法在laravel中合并2个关系? 这是现在设置的方式,但是有没有办法我可以将两者合并? 问题答案: 试用属性的getter方法,该方法返回从关系返回的合并集合。 或者,您可以在返回集合之前调用其他方法以获取不同的结果集。
-
Haskell合并排序
本文向大家介绍Haskell合并排序,包括了Haskell合并排序的使用技巧和注意事项,需要的朋友参考一下 示例 有序合并两个有序列表 保留重复项: 自顶向下版本: 定义这种方式是为了清楚而非效率。 使用示例: 结果: 自下而上的版本:
-
合并哈希(Raku)
常见问题,Int Raku,如何合并,合并两个哈希? 说: 如何获取
-
Pyspark:并行化UDF
我想循环两个列表,将组合传递给函数,并获得以下输出: 由于这是Pyspark,我想将其并行化,因为函数的每个迭代都可以独立运行。 注:我的实际函数是pyspark中的一个长而复杂的算法。只是想贴一个简单的例子来概括。 最好的方法是什么?
-
TestNG并行执行
我有4个@Test方法,希望每个方法都运行3次。我想在12个线程中同时执行所有这些。 我创建了一个testng。像这样的xml文件 如果我设置并行="方法",TestNG在Test1的4个线程中执行4个测试方法,之后对Test2执行相同的操作,然后对Test3执行相同的操作。但是我不想在运行Test2之前等待Test1完成。TestNG能够运行Test1、Test2 有没有办法告诉TestNG不要
-
Akka流并行性
根据文档[1],我一直试图在Akka stream中并行化一个流,但由于某些原因,我没有得到预期的结果。 我遵循了留档中列出的步骤,我不认为我错过了什么。然而,我的流的计算都是按顺序一个接一个地发生的。 我错过了什么? [1] https://doc.akka.io/docs/akka/current/stream/stream-parallelism.html 示例输出 我希望看到两个计算同时进
-
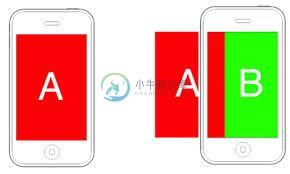 碎片并排android
碎片并排android对不起,我的英语不好。我如何并排显示片段,这样当用户点击片段a中的一个按钮时,片段B就显示出来了(80%)?
-
级联并行流
我想加快任务的速度,所以我考虑让流并行。通常,这只是意味着我可以在流构造和终端操作之间的任何地方插入,结果将是相同的。IntStream.Concat的JavaDoc表示,如果任何输入流是并行的,结果流将是并行的。因此,我认为使或流或流或级联流生成相同的结果。 实际上我错了:如果我将添加到结果流中,那么输入流似乎仍然是连续的。此外,我可以将输入流(其中任何一个或两个)标记为,然后将结果流转换为,但
-
合并RTF文件?
我还需要在两个文件之间创建一个分页符,在新的组合rtf文件中。我访问了MS word,并能够将两个rtf文件组合在一起,但这只是创建了一个没有分页符的长rtf文件。 我有一个代码,但它只复制一个文件到另一个文件相同的方式,但我需要帮助调整这段代码,以便我可以复制两个文件到一个文件 如何在FileInputStream文件的顶部添加另一个FileInputStream对象,并在文件和对象之间设置分页
-
并行使用StanfordCoreNLP
假设我有+10000个句子,我想像这个例子一样分析。有可能并行处理这些和多线程吗?
-
Spring Boot Webclient-合并
我想合并两个响应并返回一个流量。 这就是我正在做的,正在工作,但我希望在调用Mono.just(获取(状态))之前等待合并。我将解释,sendGetRequest返回一个Mono,该Mono进行API调用,并从结果将东西保存到db。随后,合并操作将调用带有读取方法的数据库,但该数据尚未更新。如果我再打一次电话,我就会得到更新的数据。
-
合并两个ObjectNode
我想将两个ObjectNode合并在一起,但要具有最佳的复杂性。我知道一种方法,我可以使用setAll方法,但它返回JsonNode,因此我必须转换它。我发现的转换过程的最佳方法是如何将JsonNode转换为ObjectNode。我认为这种转换一旦迭代Json,也许我们可以找到一个更好的解决方案。 我认为第二种方法是迭代第二个ObjectNode,然后用put方法一个接一个地添加到第一个Objec
-
JavaScript归并排序
我的最新博客地址:我的最新博客 定义 归并排序(英语:Merge sort,或mergesort),是创建在归并操作上的一种有效的排序算法,效率为O(nlogn)。1945年由约翰·冯·诺伊曼首次提出。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。 算法逻辑思想 采用分治法: 分割:递归地把当前序列平均分割成两半。 集成:在保持元素顺序
-
分支与合并
Git 有几个实现大部的分支及合并功能的实用命令。 git branch git branch 命令实际上是某种程度上的分支管理工具。 它可以列出你所有的分支、创建新分支、删除分支及重命名分支。 Git 分支 一节主要是为 branch 命令来设计的,它贯穿了整个章节。 首先,我们在 分支创建 一节中介绍了它,然后我们在 分支管理 一节中介绍了它的其它大部分特性(列举及删除)。 在 跟踪分支 一节
-
配置并行数
后台任务由在Hangfire Server的子系统中运行的专用工作线程池进行处理。当您启动后台任务服务器时,它将初始化线程池并启动固定的worker。您可以通过将值传递给 UseHangfireServer 方法来指定并行数。 var options = new BackgroundJobServerOptions { WorkerCount = Environment.ProcessorCoun