《本周投递记录》专题
-
 wxg一周速通
wxg一周速通时间线:4月22号一面 → 4月24号二面 → 4月25号面委面 → 4月29号HR面 → 下午转录用评估 → 4月30号下午oc → 5点发邮件offer btw,今年蓝桥杯终于拿省一了,太开心了
-
按级别筛选传递给父记录器的日志消息(logback)
在我看来,我想要达到的目标是很普通的,但我并没有让它起作用: 根记录器可以记录从其他特定记录器传递的信息消息,但是对于这个特定的记录器,我不希望任何信息消息被向上传递到层次结构上。
-
Python中的递归、记忆和可变缺省参数
“BASE”表示不只是使用LRU_Cache。所有这些都是“足够快的”--我不是在寻找最快的算法--但是时间让我吃惊,所以我希望我能学到一些关于Python是如何“工作”的东西。 现在很清楚了,我(和前面的许多人一样)只是偶然发现了Python的可变缺省参数。这种行为解释了执行速度的实际和明显的提高。
-
无法使用JMeter测试脚本记录器在Internet explorer中记录本地主机上运行的应用程序
我正在尝试使用JMeter(版本4)测试脚本记录器记录测试脚本,以测试我的应用程序的性能。配置代理后,记录器未记录在 Internet Explorer (IE 9) 的本地主机上运行的应用程序 URL。但是其他网址也被记录在JMeter中。我试图使用Chrome录制我的应用程序,这工作正常。我已取消选中 代理设置中的本地地址的绕过代理服务器。
-
如何将变量从python脚本传递到bash脚本
问题内容: 我有一个bash脚本a.sh,其中有一个python脚本b.py。python脚本计算某些内容,我希望它返回一个值,该值稍后将在a.sh中使用。我知道我能做 在a.sh中: 在b.py中: 但这不是那么方便,因为我还在b.py中打印了其他消息 有什么更好的方法吗? 编辑: 我现在正在做的只是 这意味着我可以在b.py中打印很多东西,但是只有最后一行(假设它不包含“ \ n”,这是最后一
-
如何找到给定月份的周六和周日?
问题内容: 我想查找给定月份中的所有星期六和星期日。我该怎么办? 问题答案: 在 最简单 的方法是只迭代所有在一个月的日子里,检查一周的某一天为他们每个人。例如: 我 绝对可以确定 ,这样做的方式要高效得多-但这就是我的出发点,当发现速度太慢时进行优化。 请注意,如果您能够使用Joda Time,那将使您的生活更加轻松…
-
周期性加载数据/关闭周期性加载
参数: url - 返回JSON格式数据,数据格式与添加(更新)数据定义的data相同 liveLoadCallback - 当加载完成时执行的回调函数 duration - 周期性数据加载时间(以毫秒为单位) 周期性地从一个数据源加载数据,用法: var url = "dynamicallyAPI/data"; // 使用liveLoad() API加载URL中的数据。 // 设置回调。 //
-
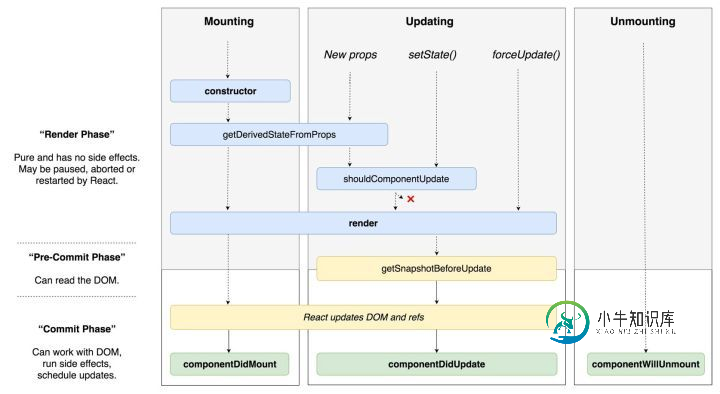 react16跟之前的版本生命周期有哪些变化?
react16跟之前的版本生命周期有哪些变化?本文向大家介绍react16跟之前的版本生命周期有哪些变化?相关面试题,主要包含被问及react16跟之前的版本生命周期有哪些变化?时的应答技巧和注意事项,需要的朋友参考一下
-
在本地测试中,由于找不到DayOf周而失败
我创建了一个简单的quarkus(版本0.21.2)应用程序,它使用hibernate orm和panache将实体保存到h2数据库。该实体包括一个,共。我还做了一些测试来确保凝乳有效。这些测试都可以正常工作,但当我在本地运行它们时,我会遇到以下异常: 我的实体如下所示: 这是我的测试: 还有本地测试: 我不知道为什么它找不到。
-
递归查找目录中的所有文本文件
问题内容: 我正在尝试获取目录中所有文本文件的名称。如果目录中包含子目录,那么我也想在这些子目录中获取任何文本文件。我不确定如何继续执行任意数量的子目录。 现在,下面的代码仅获取当前目录中的所有文本文件以及该目录中的子目录。对于找到的每个子目录,它还会找到任何文本文件和更深的子目录。问题是,如果那些更深的子目录还有更深的子目录,那么我找不到所有的文本文件。这似乎是一个需要递归的问题,因为我不知道它
-
本章小结,拿去做笔记吧
类的成员有成员变量和成员函数两种。 成员函数之间可以互相调用,成员函数内部可以访问成员变量。 私有成员只能在类的成员函数内部访问。默认情况下,class 类的成员是私有的,struct 类的成员是公有的。 可以用“对象名.成员名”、“引用名.成员名”、“对象 指针->成员名”的方法访问对象的成员变量或调用成员函数。成员函数被调用时,可以用上述三种方法指定函数是作用在哪个对象上的。 对象所占用的存储
-
Python BeautifulSoup:从div标记检索文本
我是网页刮刮的新手。我正在使用美丽的汤提取谷歌播放商店。但是,我坚持从div标记中检索文本。Div标记如下所示: 我想检索从“谢谢你的反馈”开始的文本。我使用以下代码检索文本: 但是,上面的命令也返回不需要的文本,即'education.com'和日期。我不确定如何从没有类名的div标记中检索文本,如上面的示例所示。等待你的指引。
-
Jupyter笔记本不显示进度栏
问题内容: 我正在尝试在Jupyter笔记本中使用进度条。这是一台新计算机,我通常无法正常工作: 产生以下文本输出,并且不显示任何进度条 同样,此代码: 产生以下文本输出: 我缺少让Jupyter显示这些进度条的设置吗? 问题答案: 答案在GitHub问题中。 关键是要确保使用以下命令启用笔记本扩展: 您还需要安装JupyterLab扩展: 编辑: 作为中提到的文档以及一些下面的意见,安装Jupy
-
BeautifulSoup:从锚标记中提取文本
问题内容: 我要提取: 来自标签的src的文本和 类数据内的定位标记的文本 我成功地提取了img src,但是从锚标记中提取文本时遇到了麻烦。 这是整个HTML页面的链接。 这是我的代码: 我想做的是 提取图像src(链接)和中的标题,因此例如: 应该提取: 问题答案: 以上所有答案确实可以帮助我构建答案,因此,我对其他用户提出的所有答案投了赞成票:但是我最终对自己正在处理的确切问题汇总了自己的答
-
TypeScript 学习笔记之基本类型
本文向大家介绍TypeScript 学习笔记之基本类型,包括了TypeScript 学习笔记之基本类型的使用技巧和注意事项,需要的朋友参考一下 在 TypeScript 中一共有 7 种基本类型。 1、boolean 2、number 代表 JavaScript 中的数字。在 JavaScript 中,无论是“整数”还是“浮点数”,都是以双精度浮点类型存储的。 3、string 代表字符串。跟 J