《同花顺2024春招》专题
-
Selenium + JUnit:测试顺序/流程?
问题内容: 我正在使用Selenium来测试我的Java Web应用程序的html页面(实际上是JSP)。我的网络应用程序需要访问每个页面的流程(这是一个小型的在线游戏网络应用程序),例如:要进入页面B,您需要进入页面A,输入一些文本,然后按一个按钮进入页面。 B.显然,我已经进行了一些测试来验证A页是否正常工作。 我希望能够编写更多测试,以便在运行A页的测试之后检查是否可以运行B页的测试(其余的
-
异步javascript事件的顺序
问题内容: 我有以下代码: 但是,当我执行此代码时,在图形 之前 会收到响应“ hello” 。为什么会这样呢?我将如何改变它以便我首先得到图形? 问题答案: 异步,您永远不知道哪个函数先运行\先完成… 想想异步操作,例如告诉一群人跑1英里,您知道谁会先完成吗?(是的,乔恩·斯基特,然后是查克·诺里斯…) 您可以使用Callack来运行第二个ajax:
-
jQuery ajax事件调用顺序
问题内容: 可以说我有一个简单的函数,像这样。 http://jsfiddle.net/AT5vt/ 是否可以使全局ajaxSuccess()函数在本地成功回调之前被调用?因为我想对结果进行全局检查,然后再由局部函数进行进一步处理。 问题答案: 使用默认的ajax发布而不是使用自定义发布处理程序: http://jsfiddle.net/AT5vt/1/ 并未将其放在jsfiddle中,因为从那里
-
setTimeout和Promise的执行顺序?
本文向大家介绍setTimeout和Promise的执行顺序?相关面试题,主要包含被问及setTimeout和Promise的执行顺序?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 首先我们来看这样一道题: 输出答案为2 10 3 5 4 1 要先弄清楚settimeout(fun,0)何时执行,promise何时执行,then何时执行 settimeout这种异步操作的回调,只有主线程
-
Firebase按顺序获取数据
问题内容: 我正在使用Firebase,直到最近我都没有按字母顺序获取数据的问题。我从来没有使用过查询,我总是只使用数据快照并逐一对其进行排序。最近,在 snapVal中 ,数据并不总是按字母顺序 排列 。如何做到这一点,以便获得按字母顺序排序的数据的snapVal,就像数据库快照中的快照一样? 真实示例:有4条消息,id1-id4(按此顺序)。它们包含消息“ 1”-“ 4”。快照看起来正确。但是
-
jQuery:按顺序加载脚本
问题内容: 我正在尝试使用jQuery动态加载一些脚本: 但是有时加载脚本的顺序会发生变化。前一个脚本成功加载后,如何加载每个脚本? 问题答案: 您可以通过使用回调函数作为递归函数调用在前一个完成加载后加载每个。 在您的代码中发生的是,脚本是同时被请求的,并且由于它们是异步加载的,因此它们以随机顺序返回并执行。 我尚未对此进行测试,但是如果脚本是在本地托管的,则可以尝试以纯文本格式检索它们,然后将
-
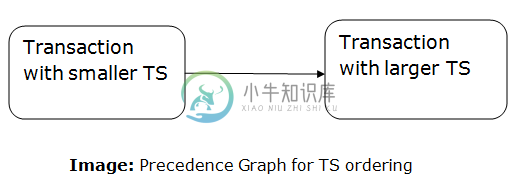 DBMS时间戳顺序协议
DBMS时间戳顺序协议DBMS时间戳顺序协议- 时间戳顺序协议用于根据事务的时间戳对事务进行排序。 事务顺序只不过是事务创建的升序。 旧事务的优先级高于它首先执行的原因。 要确定事务的时间戳,此协议使用系统时间或逻辑计数器。 基于锁的协议用于在执行时管理事务之间的冲突对之间的顺序。 但是,基于时间戳的协议会在创建事务后立即开始工作。 假设有两个事务T1和T2。 假设事务T1已经以007次进入系统并且事务T2已经以009
-
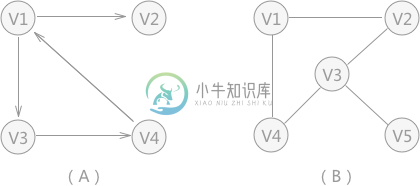 图的顺序存储结构
图的顺序存储结构主要内容:图的顺序存储结构C语言实现使用图结构表示的数据元素之间虽然具有“多对多”的关系,但是同样可以采用顺序存储,也就是使用数组有效地存储图。 使用数组存储图时,需要使用两个数组,一个数组存放图中顶点本身的数据(一维数组),另外一个数组用于存储各顶点之间的关系(二维数组)。 存储图中各顶点本身数据,使用一维数组就足够了;存储顶点之间的关系时,要记录每个顶点和其它所有顶点之间的关系,所以需要使用二维数组。 不同类型的图,存储的方式略
-
串的定长顺序存储
我们知道, 顺序存储结构( 顺序表)的底层实现用的是数组,根据创建方式的不同,数组又可分为 静态数组和 动态数组,因此顺序存储结构的具体实现其实有两种方式。 通常所说的数组都指的是静态数组,如 str[10],静态数组的长度是固定的。与静态数组相对应的,还有动态数组,它使用 malloc 和 free 函数动态申请和释放空间,因此动态数组的长度是可变的。 串的定长顺序存储结构 ,可以简单地理解为
-
 顺序栈及基本操作
顺序栈及基本操作主要内容:顺序栈元素"入栈",顺序栈元素"出栈",总结顺序栈,即用 顺序表实现栈存储结构。通过前面的学习我们知道,使用栈存储结构操作数据元素必须遵守 "先进后出" 的原则,本节就 "如何使用顺序表模拟栈以及实现对栈中数据的基本操作(出栈和入栈)" 给大家做详细介绍。 如果你仔细观察顺序表(底层实现是数组)和栈结构就会发现,它们存储数据的方式高度相似,只不过栈对数据的存取过程有特殊的限制,而顺序表没有。 例如,我们先使用顺序表(a 数组)存储 ,存储
-
 顺序表的基本操作
顺序表的基本操作主要内容:顺序表插入元素,顺序表删除元素,顺序表查找元素,顺序表更改元素我们学习了 顺序表及初始化的过程,本节学习有关顺序表的一些基本操作,以及如何使用 C 语言实现它们。 顺序表插入元素 向已有顺序表中插入数据元素,根据插入位置的不同,可分为以下 3 种情况: 插入到顺序表的表头; 在表的中间位置插入元素; 尾随顺序表中已有元素,作为顺序表中的最后一个元素; 虽然数据元素插入顺序表中的位置有所不同,但是都使用的是同一种方式去解决,即:通过遍历,找到数据元素要插入的位
-
启动屏幕顺序错误
我正在尝试完成此程序:1:请求用户在JOptionPane窗口中输入手机号码2:显示消息“单击确定以跟踪(输入)的GPS坐标3:用户单击确定后,应弹出启动屏幕。4:启动屏幕应完全完成,然后JOptionPane窗口应显示消息“位于GPS坐标内的地址是:“加上我输入的任何假地址。 现在,启动屏幕在其他所有操作中运行,并且所有操作都出现故障。我希望启动屏幕在单击“OK”后执行,然后完成并继续执行最后的
-
未使用顺风CSS的表
我成功地使用了顺风,所以我没有导入它的问题。举个例子,我用的是网格。但是,我无法创建一个在他们的例子中的表。这张桌子没有颜色。没有样式添加到表中,我错过了什么? tailwind.config.js: 未按预期方式呈现得表: }
-
.NET 中的 GUID 字节顺序
我正在创建一个这样的GUID 这输出 根据维基百科,guid中有四个部分,这解释了为什么字节顺序在四组中切换。然而,维基百科的文章还指出,所有部分都以大端格式存储。显然前三部分不是Big Endian。guid的GetBytes()方法按照与创建时完全相同的顺序返回字节。这种行为的解释是什么?
-
更改Spring Security WebFilter的顺序
-路径:/APP2/** 这意味着与其使用身份验证->路由映射->过滤web处理程序,不如使用路由映射->身份验证->过滤web处理程序。这三个组件并不是不相似,它们中的一个是过滤器,另一个是映射器,最后一个是web处理程序。现在我知道如何自定义它们,但问题是我不知道如何拦截Netty服务器构建过程,以便更改这些操作的顺序。我需要等待构建过程结束,并在开始之前更改服务器的内容。我怎么能那么做?