《大数据》专题
-
 屡败屡战的大数据秋招之面试总结以及经验
屡败屡战的大数据秋招之面试总结以及经验投了一百多家厂,累计参加了三十多场面试,面试了十多家公司只有两个拿到了意向。😅😅😅这个面试成功率也太低了些,反思反思,做一些总结。 大数据面试注重知识面的广度。需要多看面经扩展开面。 环境不好,珍惜每一场面试机会,😅😅曾经有拿中厂给大厂垫刀,练手的想法。结果发现全挂了。😅😅家没了 知识需要反复的滚动复习!前面能答上来的,过了一阵子之后知识会忘。 惨痛教训😥😥😥 不回头复习感觉自
-
 网易云音乐--大数据开发(日常实习)一面、二面挂
网易云音乐--大数据开发(日常实习)一面、二面挂本人本应是23届应届生,但是计划之外的是获得了推免资格,综合考虑之后选择退出秋招队伍,准备找日常实习。 10.4简历投递 还在国庆假期中 10.12一面(40分钟) 1. 自我介绍 2. 做到题(二叉树层序遍历) 3. java网络编程模型 4. 实习项目介绍,实习工作 5. HBase集群架构介绍 6. java的HashMap介绍,说到了2倍扩容 7. 为什么是2倍,2倍有什么好处 8. jv
-
 字节跳动 商业化技术 大数据开发实习生 面经
字节跳动 商业化技术 大数据开发实习生 面经### 一面技术面 自我介绍 四道算法 前两题是sql,其中一个难点的就是求连续登录2天以上的用户 一道快排 一道求二叉树是否是对称二叉树,就是左右节点是对称的 问实习经历(问的很细) 工作中的难点 维度建模过程 聊到数据仓库工具箱这本书的内容,我都不会。。。 数据倾斜(我从原理,场景,解决方案三个角度回答的) 问到一些常用函数,UDF,UDAF,UDTF概念 hive的概述 hadoop,hiv
-
 2022暑期实习-大数据开发面经-美团到店-餐饮SASS
2022暑期实习-大数据开发面经-美团到店-餐饮SASS一面 50分钟 自我介绍 http协议是哪一层的协议,讲一下对http的了解 tcp协议和udp协议是哪一层的协议,讲一下他们之间的区别,以及他们各自的应用场景 你知道get和post请求吗,讲一下他们之间的区别 当我们输入美团网址的时候,这个从输入到显示页面的过程 你了解操作系统吗,linux了解吧,你说一下你用过的命令 当我们要查看文件的具体属性用什么命令 讲一下静态链表和动态链表的区别 数据
-
 电信智科-大数据开发运营工程师(成都base)面经
电信智科-大数据开发运营工程师(成都base)面经电信智科(中国电信股份有限公司数字智能科技分公司)-大数据开发运营工程师面经 9月1日投的,15日笔试,26日一面。这个公司是在国聘行动上投递的,在成都就这一个岗位,本来没抱希望投的,结果没想到还给面试了。面试在腾讯会议上的,一共25分钟左右,比较短;感觉有点凉,像kpi面,我准备了kafka的很多八股,结果一个没问,一直在怼网络,感觉有点像kpi面试。 以下回答绝大部分是GPT4.0回答
-
 2023暑期实习-大数据开发面试-字节商业化-HR面
2023暑期实习-大数据开发面试-字节商业化-HR面1、 面试官直接自我介绍,说HR面,开始问我问题。 2、 看专业是大数据相关的,你这是定向保研吗? 3、 你为什么选择大数据开发这个岗位? 4、 平常你怎么学习这些技术的? 5、 新技术看文档、博客、源码这些? 6、 经过两轮技术面,你对自己的评价? 7、 什么时候能来实习? #找实习多的是你不知道的事#
-
批量 - 如何在超大的Excel文件中读取前N行数据?
我的Excel文件大概有3000行,1000列。 我希望在这个海量数据中进行搜索,我尝试了使用POI,也尝试了比如先取出部分行数,如60行,并且在60行内进行搜索。但不论怎么样,我总是会遇到out of memroy的问题。
-
 腾讯TEG 大数据平台 Java日常实习 一面二面经验
腾讯TEG 大数据平台 Java日常实习 一面二面经验岗位介绍 在腾讯大数据平台,Java日常实习的主要工作内容是腾讯大模型系统的研发,以及推荐系统平台研发。岗位要求实习6个月以上,且无转正。 一面面经 0.5h Java JVM调优了解过没有?JVM GC机制有了解过吗? 都无 ConcurrentHashMap和HashMap的区别是什么,底层实现是什么样的? MySQL MySQL索引有哪些类型? MySQL事务隔离级别? 计算机网络 TCP三
-
1.2.3 es 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
面试题 es 在数据量很大的情况下(数十亿级别)如何提高查询效率啊? 面试官心理分析 这个问题是肯定要问的,说白了,就是看你有没有实际干过 es,因为啥?其实 es 性能并没有你想象中那么好的。很多时候数据量大了,特别是有几亿条数据的时候,可能你会懵逼的发现,跑个搜索怎么一下 5~10s,坑爹了。第一次搜索的时候,是 5~10s,后面反而就快了,可能就几百毫秒。 你就很懵,每个用户第一次访问都会比
-
R: 查找数据帧列中大于或等于其他数据帧列的行值的最小值
第一次问问题(温柔点),因为我还没有找到任何有用的东西。 在R中,我有两个数据帧。一个(DataFrameA)有一列带有唯一日期列表。另一个(DataFrameB)也有日期列表。但是DataFrameB中的某些日期在DataFrameA中可能不存在。在这种情况下,我想将DataFrameB中的日期更新为DataFrameA中的最小日期,该日期大于DataFrameB中的日期。 在SQL中,我可能会
-
宇宙数据库能否以批大小从文件 Blob 或 Csv 或 Json 文件中读取数据?
我目前正在研究使用cosmos db读取数据,基本上我们目前的方法是使用带有Cosmos DB SDK的.Net Core C#应用程序从文件blob或csv或json文件中读取整个数据,然后使用for循环,逐个从cosmos db中提取其信息并比较/插入/更新, 这在某种程度上感觉效率低下。 我们很好奇 cosmos DB 是否可以执行从文件 blob 或 csv 或 json 文件以及类似 S
-
为什么分报告中不同维度的数据相加会大于网站概况的数据
使用指南 - 疑难问题 - 数据矛盾问题 - 为什么分报告中不同维度的数据相加会大于网站概况的数据 每个报告的分析维度不同,因此去重逻辑也不同。网站概况,以及趋势报告中的数据是以整个站点为维度去重的,是了解站点整体流量和访问量的地方。 例如:访客 X 通过百度搜索进入网站后又通过直接访问进入网站,此时,“搜索引擎”报告和“直接访问”报告会各记录一个独立访客数据,但是网站概况中只会记录一个独立访客数
-
空手道场景大纲-基于JSON数组索引大小创建动态示例表
在这里,我想澄清一下如何为动态JSON索引大小创建动态示例表 我的JSON看起来像 Env-Dev-2服务器 Env-Uat-3服务器 我的场景大纲看起来像 上述错误: 1) *动态表达式计算失败:result.response.abc 2)com.intuit.karate.karateExpresion: ---- javascript评估失败result.response.abc,Requi
-
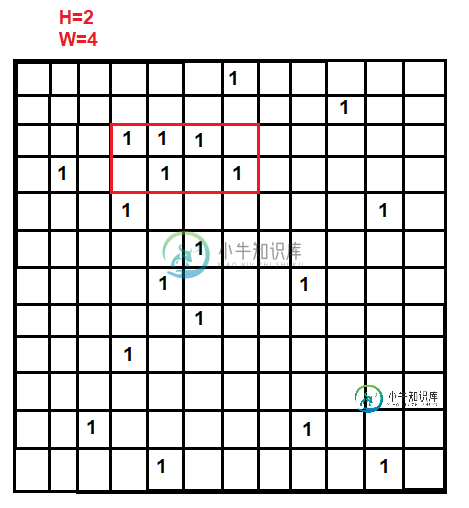 大 2D 位矩阵中大小为 HxW 的最大子阵列
大 2D 位矩阵中大小为 HxW 的最大子阵列我有一个大的NxN位数组,有K个1(其他都是0)。所有非零点的坐标都是已知的——换句话说,这个n×n数组可以表示为K对数组,每个数组包含一个非零点的x和y坐标。 给定一个HxW大小的子矩阵,我需要将其放在我的原始NxN数组上,使其覆盖大多数非零点。 输入:子矩阵的高度H和宽度W 输出:HxW子数组的x和y协弦,其内部有最多的协弦 之前也回答过类似的问题:2D矩阵中尺寸为HxW的最大子阵列,但在我的
-
下载大小大于可用流/文件大小。(Asha 501,J2ME)
我正在下载一个歌曲文件。下面的代码(好吧,原始代码,这只是我正在做的一个示例)在Asha 310设备上运行良好。然而,在较新的Asha 501设备上,下载的文件比实际文件大得多。如果我使用512缓冲区,一个2.455.870字节的文件最终会下载2.505.215字节,而且它也不会加载。使用4096缓冲区,文件大小最终为3.342.335字节!! 发生这种情况的原因是什么?它在另一部手机上运行良好,