《大数据》专题
-
操作SHA256哈希的大型文本数据库的最有效方法?
我必须经常在这种格式的大型(高达1G)CSV数据库中搜索哈希 在C.这需要非常快,内存使用不是问题(最低32G)。我发现这非常接近我的想法:将数据加载到内存中,一次性按哈希排序数据库,按哈希的第一个n字节索引,然后通过较小的子列表搜索。但是上面的帖子似乎没有解决我中间的一个问题。因为我不是一个密码学的家伙,我想知道哈希的分布,以及它是否可以用来更快地搜索子列表。对此或我的总体方法有什么建议吗?
-
更改大型数据表的字符集的更好方法是哪种?
问题内容: 在我的生产数据库中,使用默认字符集“ latin”创建了与警报相关的表,因此,当我们尝试在表中插入日文字符时遇到错误。我们需要将表和列的默认字符集更改为UTF8。由于这些表中包含大量数据,Alter命令可能会花费很多时间(在具有相同数据量的本地DB中花费了5个小时)并锁定了表,这将导致数据丢失。我们是否可以计划一种将字符集更改为UTF8而不丢失数据的机制。 更改大型数据表的字符集的更好
-
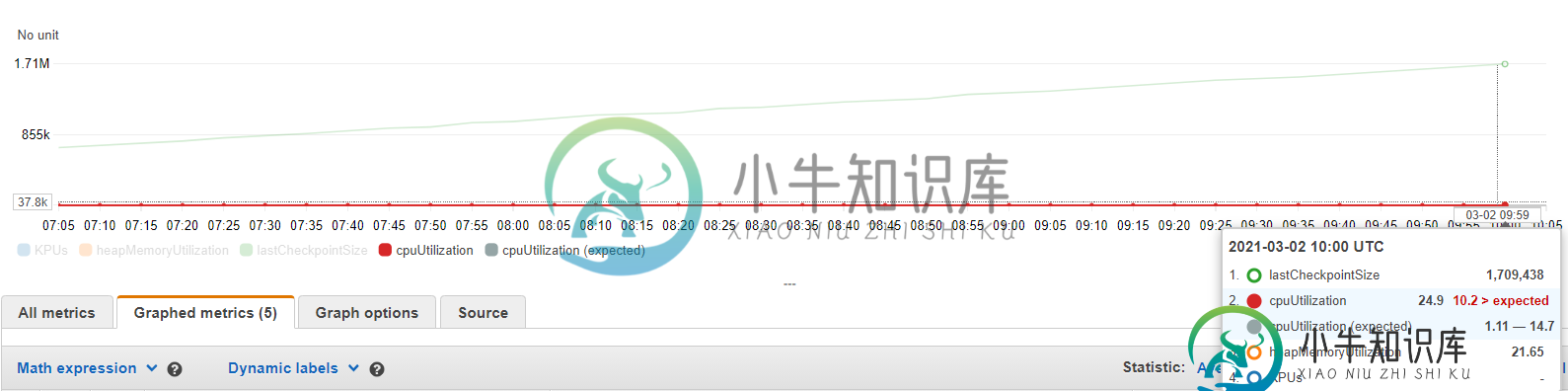 Apache Flink-检查点数据大小随着时间的推移而增加
Apache Flink-检查点数据大小随着时间的推移而增加我在我的Flink应用程序(版本1.11.1)中使用事件时语义,该应用程序运行在AWS-kinesis analytics中。此应用程序的源为kinesis stream,汇为Postgres。notifyCheckpointComplete()上触发DB接收器时,检查点间隔为10秒。我正在使用多个协处理函数和ValueState连接不同的流,然后再将其放入Postgres。 观察到,检查点数据大
-
为什么没有与缓存行大小一样宽的数据总线?
当发生缓存未命中时,CPU会将整个缓存线从主内存提取到缓存层次结构中。(x86\u 64上通常为64字节) 这是通过数据总线完成的,在现代64位系统上,数据总线只有8字节宽。(因为字大小是8字节) 编辑:“数据总线”在此上下文中是指CPU芯片和DRAM模块之间的总线。此数据总线宽度不一定与字大小相关。 根据策略,首先获取实际请求的地址,然后依次获取缓存行的其余部分。 如果有一个64字节宽的总线,它
-
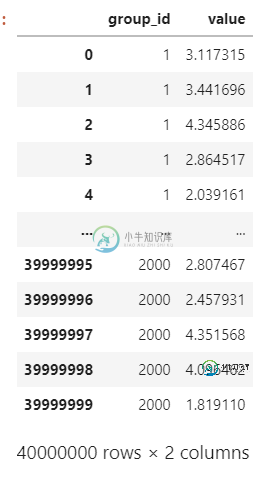 如何有效地标记大数据帧的每组中的随机行?
如何有效地标记大数据帧的每组中的随机行?我有一个包含40百万行的数据框。有一个名为的列指定一行的组标识符。一共有2000个群。 我想随机标记每组中的元素,并将此信息添加到的列中。例如,如果组1包含行1、2、3、4和5,那么我选择(1、2、3、4、5)的排列,例如,我们取(5、3、4、2、1)。然后我将值[5,3,4,2,1]分配给这些行的列。 我定义了一个函数,并使用了并行化,但是速度非常慢。你能建议一个更快的方法吗?
-
根据子节点的数量动态调整d3树布局的大小
从http://mbostock.github.com/d3/talk/20111018/tree.html这个例子中,我构建了一个< code>d3树布局,其中根在浏览器窗口的中间(< code>root.x0 = width/2),节点在向下的方向,而不是面向右边。 是否可以重新调整树的大小,使得树的宽度取决于树的节点数量,如果节点数量较少,则宽度较小,或者如果节点数量较大,则宽度较大? 我还
-
如何从大型xlsx文件中加载pandas数据帧的进度条?
来自https://pypi.org/project/tqdm/: 我获取了这段代码并对其进行了编辑,以便从load_excel创建数据帧,而不是使用随机数: 这给了我一个错误,所以我将df.progress_apply改为: 这是最终代码: 这会产生一个进度条,但它实际上并不显示任何进度,而是加载进度条,当操作完成时,它会跳到100%,从而达到目的。 我的问题是:如何让这个进度条工作? prog
-
Flink关闭挂钩以最大限度地减少数据丢失/重复
我有一个flink作业,从kafka读取数据,从redis读取一些数据,然后将聚合的窗口数据写入redis接收器(redis写入操作实际上是调用加载到redis中的lua脚本,该脚本会增加现有值,因此我只能在此处增加而不能更新)。 问题是,当我停止作业(维护、代码更改等)时,即使使用保存点,我也会向redis写入重复数据,或者在恢复时丢失一些数据,因为据我所知,redis sink在语义方面没有任
-
查询以比较数据库中从2列开始的大小范围
我有一个简单的数据库表,它包含以下列: 用户从列表中选择一个产品,然后根据minSize和MaxSize查询数据库中的类似产品。 如果用户选择Prod1,则将通过所选的minSize和maxSize查询数据库表,并且上面示例数据中的结果将包括Prod2和PROD3。 我正在努力确定查询是否在允许的范围内找到产品。谁能给我指出正确的方向或者给我举个例子吗?我的SQL知识有限。 肖恩
-
时间序列数据的卡桑德拉:如何调整分区大小?
我正在尝试使用Cassandra来存储来自一些传感器的数据。我读了很多关于Cassandra的时间序列数据模型的文章。我从时间序列数据建模入门开始,“时间序列模式2”看起来是最好的方法。所以我创建了一个复制因子为2的键空间和一个这样的表 其中是唯一的设备ID,是一天(例如2017-08-30),是时间戳。 我的查询是 如您所见,我需要从多天中检索数据,这意味着在我的集群中读取多个分区。在我看来,查
-
如何在大数据文件中使用熊猫删除重复的行?
我有一个csv文件太大,无法加载到内存中。我需要删除文件的重复行。所以我这样做: 但是如果重复的行分布在不同的块中,就像上面的脚本不能得到预期的结果。 还有更好的方法吗
-
巨大数据负载下对JTable行选择事件的延迟响应
我有一个Swing动态更新了大量数据,新的行不断地被实时添加,大约1000-2000行可以在几分钟内添加。我已经注册了一个监听器来响应使用的单行选择事件来执行一些操作。我使用了Observer模式进行Swing数据绑定,表的模型由WritableList实现支持。因此,新项目从表自身的领域添加到表中。监听器是从SWT UI线程添加的。问题是,当向表中添加新行时,它不会立即响应用户行选择事件。只有在
-
邻近数据的大小现代计算机缓存的地方青睐
我有一个1024个缓冲区的连续内存,每个缓冲区大小2K字节。我使用一个链表来记录可用的缓冲区(这里的缓冲区可以被认为是生产者和消费者使用的)。经过一些操作后,链接列表中缓冲区的顺序变得随机。 现代计算机体系结构非常倾向于紧凑的数据、局部性。当需要访问某个位置时,它会缓存相邻的数据。我的计算机的缓存线是64(从64K更正)字节。 问题1。就我的情况而言,由于我的访问模式是随机的,是否有很多缓存未命中
-
如何像调度程序一样将大数据从MongoDB导入SQL Server
-
 字节跳动大数据研发实习生-商业化技术凉经
字节跳动大数据研发实习生-商业化技术凉经1. 自我介绍,项目介绍 2. 自我介绍的时候问我这些东西是自己学的还是学校讲的。 内心:在说什么。。。 3. 因为简历上第一个写的是使用爬虫进行数据挖掘,但是没用flume进行数据采集,所以就简单的说一下当时是把数据采集成csv或者data格式的文件,直接上传到的Hdfs,直接使用load path加载到hive当中。 并且当时介绍了数据集的大小,以及介绍了可能会产生的问题, 4. 面试