
Apache Flink-检查点数据大小随着时间的推移而增加

我在我的Flink应用程序(版本1.11.1)中使用事件时语义,该应用程序运行在AWS-kinesis analytics中。此应用程序的源为kinesis stream,汇为Postgres。notifyCheckpointComplete()上触发DB接收器时,检查点间隔为10秒。我正在使用多个协处理函数和ValueState连接不同的流,然后再将其放入Postgres。
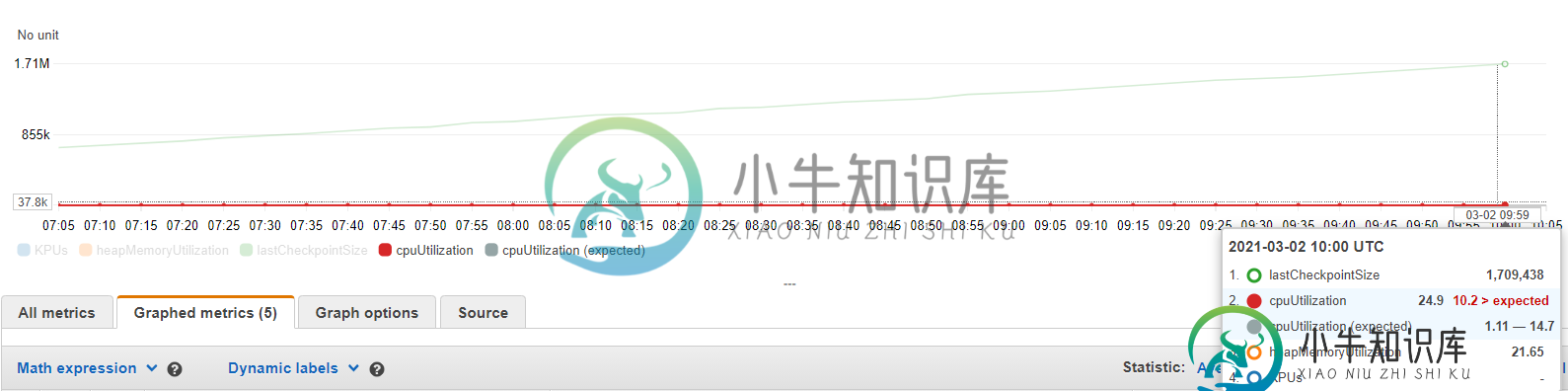
观察到,检查点数据大小在一段时间内不断增长,而线程计数和堆内存利用率保持不变。CPU利用率不超过30%。我希望检查点数据的大小最终稳定下来。
在查看有关状态TTL的flink文档时,似乎当前状态TTL只支持处理时间语义-状态生存时间(TTL)
基于事件时间的Flink应用程序的发展方向是什么?
共有1个答案

您仍然可以使用状态TTL。只是状态保留间隔必须用挂钟时间来表示,而不是与事件中的时间戳相关。
但是,如果您想更多地控制何时以及如何清除状态,可以在协处理函数中使用计时器触发对清除的显式调用。
-
我有一个正在运行的Spark Streaming应用程序,它使用mapWithState函数来跟踪RDD的状态。该应用程序可以正常运行几分钟,但随后会崩溃 我观察到,Spark应用程序的内存使用量随着时间的推移呈线性增加,尽管我已经为mapWithStateRDD设置了超时。请参阅下面的代码片段和内存使用情况- 如果每个RDD都有一个显式超时,为什么内存会随着时间线性增加? 我已经尝试增加内存,但
-
问题内容: 我正在尝试处理表中的数百万条记录(大小约为30 GB),目前正在使用分页(mysql 5.1.36)进行处理。我在for循环中使用的查询是 对于大约50万条记录,这完全可以正常工作。我正在使用的页面大小为5000,在第100页之后,查询开始显着放缓。前约80页在2-3秒内提取出来,但在第130页左右之后,每页检索大约需要30秒,至少直到200页为止。我的一个查询大约有900页,这将花费
-
首先也是最重要的: null 现在,这项工作一直很好,直到上周,我们有一个激增(10倍以上)的流量。从那时候起,Flink变成了香蕉。检查点大小开始从500MB缓慢增长到20GB,检查点时间大约需要1分钟,并且随着时间的推移而增长。应用程序开始失败,并且永远无法完全恢复,事件迭代器的年龄增长也永远不会下降,因此没有新的事件被消耗。 因为我是一个新的闪现,我不确定我做滑动计数的方式是不是完全没有优化
-
这个说法我不清楚。你能更多地解释一下这个用例吗?
-
源在内存中创建任意数量的事件,每秒吞吐量为1个事件。每个事件都有用于分区流的唯一id(使用keyBy运算符),并通过映射函数向托管状态(使用ValueState)添加约100KB。然后将事件简单地传递给不执行任何操作的接收器。 使用上面描述的设置,我们发送了1200个事件,检查点间隔和最小暂停设置为5秒。当事件以恒定的速度和相等的状态量出现时,我们期望检查点的大小或多或少是恒定的。然而,我们观察到
-
我对JavaFX有问题。当我调整窗口大小时,它会自动调整锚具的大小以适应。此外,帆布的宽度和高度属性也被绑定到锚烷上。因此,如果通过重新调整窗口本身,锚烷变大,画布也会变大。 但是当我把窗户变小,宽度和高度保持不变时,问题就来了。我真的不明白那里的行为。 因此,如果在使窗户更大的宽度和高度是100。然后在把窗口缩小后,它仍然是100。。。除息的 这是我的画布控制器。 以及我对应的FXML: