
为什么spark worker的内存使用会随着时间的推移而增加?

我有一个正在运行的Spark Streaming应用程序,它使用mapWithState函数来跟踪RDD的状态。该应用程序可以正常运行几分钟,但随后会崩溃
org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 373
我观察到,Spark应用程序的内存使用量随着时间的推移呈线性增加,尽管我已经为mapWithStateRDD设置了超时。请参阅下面的代码片段和内存使用情况-
val completedSess = sessionLines
.mapWithState(StateSpec.function(trackStateFunction _)
.numPartitions(80)
.timeout(Minutes(5)))
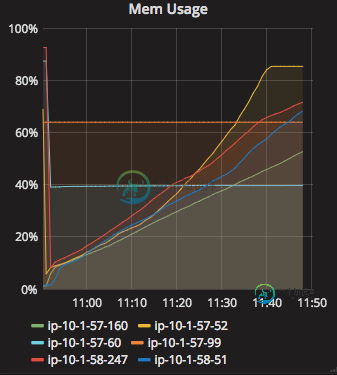
如果每个RDD都有一个显式超时,为什么内存会随着时间线性增加?
我已经尝试增加内存,但没有关系。我错过了什么?
编辑-代码供参考
def trackStateFunction(batchTime:Time,key:String,value:Option[String],state:state[(Boolean,List[String],Long)]:Option[(Boolean,List[String])]={
def updateSessions(newLine: String): Option[(Boolean, List[String])] = {
val currentTime = System.currentTimeMillis() / 1000
if (state.exists()) {
val newLines = state.get()._2 :+ newLine
//check if end of Session reached.
// if yes, remove the state and return. Else update the state
if (isEndOfSessionReached(value.getOrElse(""), state.get()._4)) {
state.remove()
Some(true, newLines)
}
else {
val newState = (false, newLines, currentTime)
state.update(newState)
Some(state.get()._1, state.get()._2)
}
}
else {
val newState = (false, List(value.get), currentTime)
state.update(newState)
Some(state.get()._1, state.get()._2)
}
}
value match {
case Some(newLine) => updateSessions(newLine)
case _ if state.isTimingOut() => Some(true, state.get()._2)
case _ => {
println("Not matched to any expression")
None
}
}
}
共有2个答案

MapSusState还在RAM中存储mapSusStateRDD(请参阅MapSusStateRDD),默认情况下,mapSusState在RAM中存储多达20个MapSusStateRDD。
简而言之,RAM的使用与批次间隔成正比,
您可以尝试减少批处理间隔以减少RAM使用。

根据mapwithstate:State Specification的信息,初始状态为RDD——您可以从某个商店加载初始状态,然后使用该状态启动流媒体工作。
分区数-键值状态dstream按键分区。如果您之前对状态的大小有很好的估计,您可以提供相应的分区数。
分区器-您还可以提供自定义分区器。默认的分区器是散列分区器。如果您对密钥空间有很好的了解,那么您可以提供一个自定义分区器,它可以比默认的哈希分区器进行更高效的更新。
超时-这将确保值在特定时间段内未更新的键将从状态中删除。这有助于清理旧键的状态。
因此,超时时间只与一段时间后清理没有更新的密钥有关。内存将满负荷运行并最终阻塞,因为执行器没有分配足够的内存。这将导致MetaDataFetchFailed异常。随着记忆的增加,我希望你指的是遗嘱执行人。即使这样,增加执行器的内存也可能行不通,因为流仍在继续。使用MapWithState,会话线将包含与输入数据流相同的记录。所以解决这个问题的办法是让你的数据流变小。在流式处理上下文中,您可以设置一个批处理间隔,这很可能会解决这个问题
val ssc=新的StreamingContext(sc,秒(batchIntervalSeconds))
还记得偶尔做一次快照和检查点。这些快照将允许您使用现在已丢失的数据流中的信息进行其他计算。希望这有助于了解更多信息,请参阅:https://docs.cloud.databricks.com/docs/spark/1.6/examples/StreamingmapWithState。html,以及http://asyncified.io/2016/07/31/exploring-stateful-streaming-with-apache-spark/
-
我在我的Flink应用程序(版本1.11.1)中使用事件时语义,该应用程序运行在AWS-kinesis analytics中。此应用程序的源为kinesis stream,汇为Postgres。notifyCheckpointComplete()上触发DB接收器时,检查点间隔为10秒。我正在使用多个协处理函数和ValueState连接不同的流,然后再将其放入Postgres。 观察到,检查点数据大
-
问题内容: 我正在尝试处理表中的数百万条记录(大小约为30 GB),目前正在使用分页(mysql 5.1.36)进行处理。我在for循环中使用的查询是 对于大约50万条记录,这完全可以正常工作。我正在使用的页面大小为5000,在第100页之后,查询开始显着放缓。前约80页在2-3秒内提取出来,但在第130页左右之后,每页检索大约需要30秒,至少直到200页为止。我的一个查询大约有900页,这将花费
-
为什么gcc在上的末尾插入了,而我却要自己在上添加? 从:
-
代码只是从输入源获取ip数据,然后在加入后找到它的公司。以下是我的问题: 这段代码在生产中会运行2-3分钟,但当删除广播数据(只需在两个数据上连接)时,只需花费不到1分钟。当我查看spark的ui时,我发现gc时间可能是问题所在。 下面是运行此作业的设置: null 更新2。由于生产代码相当复杂,与上面的伪代码不同,在代码顺序上稍作改变后,程序运行得更快,但我不确定问题的关键是初始化广播数据的位置
-
我的java服务运行在一个16 GB的RAM主机上,-xms和-xmx设置为8GB。主机正在运行其他几个进程。 我注意到随着时间的推移,我的服务消耗了更多的内存。我在主机上运行以下命令,并记录java服务的内存使用情况。 当服务启动时,它使用了大约8GB内存(将-xms和-xmx设置为8GB),但一周后,它使用了大约9GB+内存。它每天消耗大约100MB的内存。 我去了一个垃圾堆。我重新启动了我的