
大 2D 位矩阵中大小为 HxW 的最大子阵列

我有一个大的NxN位数组,有K个1(其他都是0)。所有非零点的坐标都是已知的——换句话说,这个n×n数组可以表示为K对数组,每个数组包含一个非零点的x和y坐标。
给定一个HxW大小的子矩阵,我需要将其放在我的原始NxN数组上,使其覆盖大多数非零点。
输入:子矩阵的高度H和宽度W
输出:HxW子数组的x和y协弦,其内部有最多的协弦
之前也回答过类似的问题:2D矩阵中尺寸为HxW的最大子阵列,但在我的问题中更为复杂,因为N是巨大的,在我的例子中:N=60000,K
创建 60000x60000 数组将是一个内存消耗,即使它是一个位数组。这就是为什么我想出了用所有非零点表示该数组的想法:K 对的一维数组。
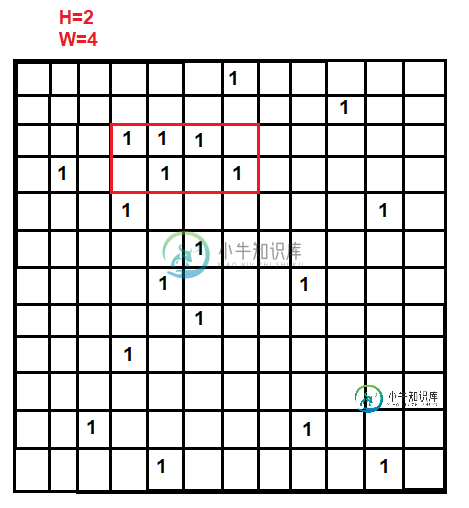
我能想到的一切都是内存和时间效率极低的,我正在寻找任何不会吃掉我所有公羊的解决方案。下面是它的外观:输出将是点 (4,3),因为从这一点开始的 HxW 子数组包含最多的子数组。
共有1个答案

这里有一个算法,应该是O(k2*h)(它可能被优化为O(k*h*w)),并且对空间要求非常轻O(k)。它基于这样一个理论,即任何具有最高非零和的子矩阵必须在其左侧边缘有一个点(否则,在这个子矩阵的右侧可能有一个和更高的子矩阵)。因此,为了找到最高和,我们迭代每个非零点,并找到所有在其左侧边缘有该点的子矩阵,对子矩阵中每一行的当前点右侧W内的所有非零点求和。
下面是该算法的python实现。它首先创建每一行中的点的字典,然后如所述迭代每一点,存储该行右侧非零点的总和,然后基于该点计算每个子矩阵的总和。如果总和大于当前最大值,则存储该值及其位置。请注意,这使用了0索引列表,因此对于示例数据,最大值为(2,3)。
from collections import defaultdict
def max_subarray(n, nzp, h, w):
maxsum = 0
maxloc = (0, 0)
# create a dictionary of points in a row
nzpd = defaultdict(list)
for p in nzp:
nzpd[p[0]].append(p[1])
# iterate over each of the non-zero points, looking at all
# submatrixes that have the point on the left side
for p in nzp:
y, x = p
pointsright = [0] * n
for r in range(max(y-(h-1), 0), min(y+h, n)):
# points within w to the right of this column on this row
pointsright[r] = len([p for p in nzpd[r] if x <= p <= x+(w-1)])
# compute the sums for each of the possible submatrixes
for i in range(-h+1, h):
thissum = sum(pointsright[max(y+i, 0):min(y+i+h, n)])
if thissum > maxsum:
maxsum = thissum
maxloc = (y, x)
# adjust the position in case the submatrix would extend beyond the last row/column
maxloc = (min(n-h, maxloc[0]), min(n-w, maxloc[1]))
# print the max sum
print(f'{maxsum} found at location {maxloc}')
示例用法:
nzp = [(0, 6), (1, 9), (2, 3), (2, 4), (2, 5),
(3, 1), (3, 4), (3, 6), (4, 3), (4, 3),
(4, 10), (5, 5), (6, 4), (6, 8), (7, 5),
(8, 3), (10, 2), (10, 8), (11, 4), (11, 10)
]
max_subarray(12, nzp, 2, 4)
输出:
5 found at location (2, 3)
rexter上的演示
-
给定一个2维正整数数组,求和最大的HxW子矩形。矩形的总和是该矩形中所有元素的总和。 输入:具有正元素的二维数组NxN子矩形的HxW大小 输出:HxW大小的子矩阵,其元素的总和最大。 我已经使用蛮力方法解决了这个问题,但是,我现在正在寻找一个具有更好复杂性的更好的解决方案(我的蛮力法的复杂性是O(n6))。
-
我有一个数据集,它有4列/属性和150行。我想用最小最大规范化来规范化这个数据。到目前为止,我的代码是: 这里,和返回全局最小值和最大值。因此,这段代码实际上对2D矩阵中的所有值应用最小-最大规范化,以便全局最小值为0,全局最大值为1。 然而,我想对每一列分别执行相同的操作。具体来说,2D矩阵的每一列都应该独立于其他列进行最小-最大规格化。 我尝试使用只是使用和,但得到的错误说矩阵维度必须一致。
-
我实现了c程序,可以找到矩阵的元素:行的最大元素,同时列的最小元素,或行的-min元素,同时列的最大元素。例如,我们有数据。包含以下内容的txt文件: 4 7 8 9 10 6 5 4 11 5 0 1 12 4 2 7 13- 其中4是n-矩阵大小(4x4),7和10是这些数字。 下面是代码: 问题:我想知道我的代码是不是“脏”代码?因为我总是渴望让一切变得如此困难,只要有可能让它变得容易。是否
-
我用直方图解决方案编写了这段代码,但用户将输入其矩阵,而不是在代码上输入矩阵。现在看看我做错了什么,除了柱状图的数学之外,一切似乎都正常。我做错了什么? 用户将输入行和列,然后一个接一个地输入矩阵中的每个值。然后代码将显示矩阵并计算所有1的最大大小矩形二进制子矩阵。
-
我正在寻找一个有效的解决方案,从矩阵中选择不重叠的值,而不考虑成本的最小化。匈牙利算法通过选择一个代价最小的组合来解决指派问题。然而,我想要一个最大值的最小化。 匈牙利人会选择 总成本=1+2+5=8 但是,最大值为5。 我希望将组合选择为 所以我想要的输出是:4,3,2 而不是成本最小化。我想选择一个最小最大数量的组合。
-
这个问题可能是封闭的,因为它听起来很模糊,但我真的问这个,因为我不知道或者我的数学背景不够。 我试图实现一个挑战,其中一部分挑战要求我计算矩阵的最小值和最大值。我对矩阵的实现及其操作没有任何问题,但是什么是矩阵的最小值和最大值?考虑到3x3矩阵是9个数中最小的数,最大的是最大的还是其他什么?