《大数据》专题
-
将2D数组拆分为大小相同的更小的2D子数组
基本上,我要问的是给定一个正方形2D阵列和一个有效的补丁大小(2D子阵列的大小),我将如何做到这一点。最终,我不需要以任何方式存储子阵列,我只需要找到每个子阵列的中值并将它们存储在一个一维阵列中。中值和存储到新阵列对我来说很简单,我只是不知道如何处理原始2D阵列并正确拆分它。我已经尝试了几次,但一直出现越界错误。我有一个4x4: 我需要像这样拆分它 < code>[1,2] [3,4] [2,3]
-
 我在firebase实时数据库中有数据9000的大节点,我想删除除少数节点之外的所有节点
我在firebase实时数据库中有数据9000的大节点,我想删除除少数节点之外的所有节点我正在为药房做一个应用程序,所有数据都在实时数据库上,例如:用户信息,聊天和购物车。我不小心在应用程序的主节点上导入了药物的json文件,现在我有9000个节点,我无法手动删除它们。我想删除除4个节点之外的所有节点或撤消上次操作。
-
给定内存限制,对具有大量数据的文件进行排序
问题内容: 要点: 我们一天可以同时处理数千个平面文件。 内存限制是一个主要问题。 我们为每个文件进程使用线程。 我们不按列排序。文件中的每一行(记录)都被视为一列。 不能做: 我们不能使用Unix / Linux的sort命令。 无论多么轻巧,我们都无法使用任何数据库系统。 现在,我们不能只加载集合中的所有内容并使用排序机制。它将耗尽所有内存,程序将得到堆错误。 在这种情况下,您将如何对文件中的
-
巨大的数据负载下对JTable行选择事件的延迟响应
问题内容: 我有秋千 动态更新大量数据- 不断地实时添加新行,并且可以在几分钟内添加大约1000-2000行。我已经注册了一个侦听器来响应使用单行选择事件来执行一些工作。我已将Observer模式用于Swing数据绑定,并且表的模型由WritableList实现支持。因此,新项目将从其自己的领域添加到表中。侦听器是从SWT UI线程添加的。问题是,将新行添加到表时,它不会在用户行选择事件时立即响应
-
是否可以通过编程方式检测数据URL的大小限制?
问题内容: 我正在使用javascript和htmlcanvas调整jpeg图像的大小。调整大小后,我在锚标记中用作href属性,以提供一个链接,用户可以在其中下载调整大小的图像。 在一定的图像尺寸下效果很好。 似乎不同的浏览器对数据URL的大小有不同的限制,如下所述 在chrome中,当我超出数据URL大小限制时,单击下载链接不会发生任何事情。没有错误或任何东西(据我所知)。 是否可以通过编程方
-
PHP实现根据数组某个键值大小进行排序的方法
本文向大家介绍PHP实现根据数组某个键值大小进行排序的方法,包括了PHP实现根据数组某个键值大小进行排序的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现根据数组某个键值大小进行排序的方法。分享给大家供大家参考,具体如下: 问题:针对给定数组的某个键的键值进行排序 解决方法: 运行结果: PS:这里再为大家推荐一款关于排序的演示工具供大家参考: 在线动画演示插入/选择/冒泡/
-
纯CSS,可根据动态字符数量对字体大小做出响应
问题内容: 我知道可以使用Javascript轻松解决此问题,但是我只对纯CSS解决方案感兴趣。 我想要一种动态调整文本大小的方法,以使其始终适合固定的div。这是示例标记: 我在想,也许可以通过在ems中指定容器的宽度,并让font-size继承该值来实现? 问题答案: 我刚刚发现,使用大众汽车是可能的。它们是与设置视口宽度相关的单位。有一些缺点,例如缺乏对旧版浏览器的支持,但这绝对是认真考虑使
-
如何使用Spring data Rest对数据进行不区分大小写排序?
我喜欢在我的SortimentRespository中有一个findAll方法,它允许排序和分页,并且我可以在其中传递一个参数,该参数包含当前页面和页面的大小以及我想要排序的列的名称(不区分大小写)。 请求应类似于: http://localhost:8081/x/rest/sorti ments?尺寸=20 或 http://localhost:8081/x/rest/sortiments?si
-
Apache Beam数据流读取带有splittable=true的大CSV,导致重复条目
我使用下面的代码片段将CSV文件作为dict读入管道。 在并行读取源文件时可能会有一些问题吗?是不是有什么我忽略了或者没有用正确的方式去照顾?
-
 Python利用多进程将大量数据放入有限内存的教程
Python利用多进程将大量数据放入有限内存的教程本文向大家介绍Python利用多进程将大量数据放入有限内存的教程,包括了Python利用多进程将大量数据放入有限内存的教程的使用技巧和注意事项,需要的朋友参考一下 简介 这是一篇有关如何将大量的数据放入有限的内存中的简略教程。 与客户工作时,有时会发现他们的数据库实际上只是一个csv或Excel文件仓库,你只能将就着用,经常需要在不更新他们的数据仓库的情况下完成工作。大部分情况下,如果将这些文件存
-
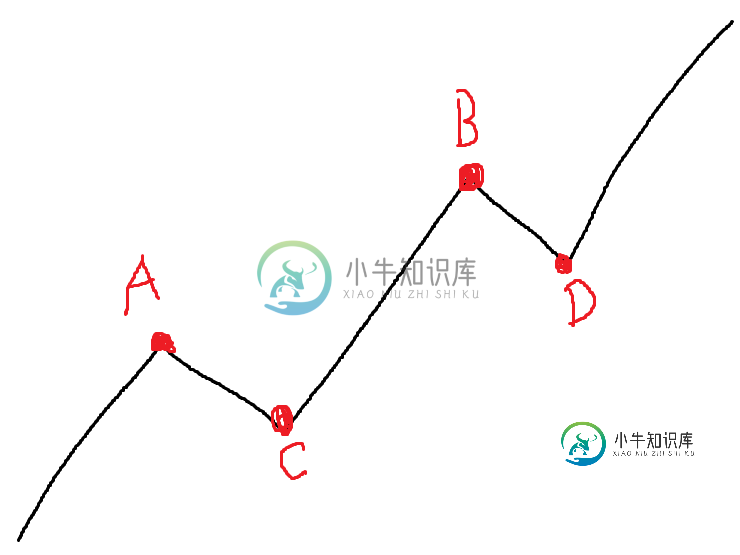 Python在离散数据上查找局部最大值和最小值[重复]
Python在离散数据上查找局部最大值和最小值[重复]假设这条线是由熊猫的离散随机数组成的。我怎样才能找到A、B、C、D点? A是第一点和C之间的最高点 C是A和B之间的最低点 B是C和D之间的最高点 您可以使用这些数据来测试:[1, 2, 3, 10, 13, 15, 20, 50, 49, 49, 32, 33, 35, 36, 35, 34, 33, 34, 35, 36, 30, 27, 22, 15, 15, 17, 20, 27, 30,
-
使用Vuex在Vue应用程序中高效地处理大型数据集
在我的Vue应用程序中,我有Vuex存储模块,它们的状态下有大量资源对象。为了方便地访问这些数组中的单个资源,我制作了Vuex getter函数,将资源或资源列表映射到各种键(例如“id”或“标签”)。这导致性能迟缓和巨大的内存占用。如何在没有如此多重复数据的情况下获得相同的功能和反应性?
-
订单表数据量越来越大导致查询缓慢, 如何处理?
本文向大家介绍订单表数据量越来越大导致查询缓慢, 如何处理?相关面试题,主要包含被问及订单表数据量越来越大导致查询缓慢, 如何处理?时的应答技巧和注意事项,需要的朋友参考一下 分库分表. 由于历史订单使用率并不高, 高频的可能只是近期订单, 因此, 将订单表按照时间进行拆分, 根据数据量的大小考虑按月分表或按年分表. 订单ID最好包含时间(如根据雪花算法生成), 此时既能根据订单ID直接获取到订单
-
JPA spring启动-当数据库很大时(20M行表),findBy速度非常慢
我需要你们关于JPA spring数据的联系。我的数据库使用MySQL,数据容量为20GB(20m行)。当我执行findByID(字符串id)-(不是唯一标识符)时。这需要10多分钟。。。 性能问题可能是什么?? 我的对象实体: 我的职能: @自动连线专用数据存储库数据存储库; Hibernate统计: 如果我移除findBy需要10秒。。。 谢谢,伊丹
-
如何检测时间序列数据中的重大变化/趋势?[关闭]
因此,我有一个25个样本的数组,我希望能够注意到它是从25个样本的时间间隔减少n还是增加n的趋势(基本上,25个样本数组是我的缓冲区,每1毫秒填充一次)。 请注意,我正在寻找的是一般趋势,而不是单个导数(就像我使用有限差分或其他数值微分技术获得的那样)。 基本上,我希望我的数据是嘈杂的,所以即使在进行过滤等操作后,也可能会有起伏。但我正在寻找的是行为增加或减少的总体趋势。 我想在每个ms中集成递增