《nlp算法工程师》专题
-
 常用算法实现方法
常用算法实现方法算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。
-
如何计算过程的完成时间?- 最短剩余时间优先算法
我使用最短剩余时间优先算法(SRTF)来计算流程的平均等待时间和周转时间。 我想以如下所示的表格格式打印结果。 这里AT=到达时间,TT=周转时间,WT=等待时间。但是由于过程3和4的完成时间不可能,出现了一些错误。这是我的代码: 我犯了什么错误?请纠正我。
-
 百度提前批(直接开始二战) 高性能计算工程师一面面经
百度提前批(直接开始二战) 高性能计算工程师一面面经没想到吧兄弟们,直接开始二战了。捞了我就面呗~这回面的挺爽的。 点名表扬语音部门,面试至少感觉respect。 八股/经历 自我介绍:懂得都懂,开源+实习 讲了讲在字节的实习工作:大模型训练模拟器 根据这个他问了我TP PP DP都是什么,具体流程 如何根据TP PP的通信量进行取舍 问了量化相关,什么是per tensor,per channel,group wise 不同的量化方法之间的区别,
-
最大工作台压力计算器项目不工作
我希望文本视图每按一次按钮增加2.5,但应用程序一直崩溃。我试着使用数字选择器,但我不喜欢它的垂直方向。我决定做我自己的,后来我添加了长按功能,但现在我正在试验按钮。 这是logcat中的堆栈: 致命异常:主进程:com。实例卢克。maxbenchcalculator,PID:2281 java。lang.RuntimeException:无法启动活动组件信息{com.example.luke.m
-
归并算法之有序数组合并算法实现
本文向大家介绍归并算法之有序数组合并算法实现,包括了归并算法之有序数组合并算法实现的使用技巧和注意事项,需要的朋友参考一下 归并算法之有序数组合并算法实现 一个简单的有序数组合并算法:写一个函数,传入 2 个有序的整数数组,返回一个有序的整数数组。实现相当简单,创建一个长度为这两个长度之和的数组,然后分别用三个指针指向这三个数组,找到这两个数组中各个元素在合并数组中的位置并插入,直到某个数组指针到
-
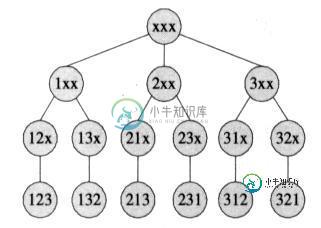 C#算法之全排列递归算法实例讲解
C#算法之全排列递归算法实例讲解本文向大家介绍C#算法之全排列递归算法实例讲解,包括了C#算法之全排列递归算法实例讲解的使用技巧和注意事项,需要的朋友参考一下 排列:从n个元素中任取m个元素,并按照一定的顺序进行排列,称为排列; 全排列:当n==m时,称为全排列; 比如:集合{ 1,2,3}的全排列为: 我们可以将这个排列问题画成图形表示,即排列枚举树,比如下图为{1,2,3}的排列枚举树,此树和我们这里介绍的算法完全一致; 算
-
Minimax算法(极小化极大算法)及实例讲解
计算机科学中最有趣的事情之一就是编写一个人机博弈的程序。有大量的例子,最出名的是编写一个国际象棋的博弈机器。但不管是什么游戏,程序趋向于遵循一个被称为Minimax算法,伴随着各种各样的子算法在一块。本篇将简要介绍 minimax 算法,并通过实例分析帮助大家更好的理解。 一、概念 Minimax算法又名极小化极大算法,是一种找出失败的最大可能性中的最小值的算法。Minimax算法常用于棋类等由两
-
5.算法原理以及算法效果(哨岗相机)
定位原理 基本原理是 sfm(Structure From Motion), 通过一系列运动图像,求得相机位姿,然后加入带有尺度信息的一组图片(拍摄的位置已知),然后进行三维重建,最后得到放置哨岗相机处成像平面相对地图原点位姿,然后检测到的机器人像素坐标通过内参矩阵与地面平面方程联立方程组,解得地面平面坐标。 相机位姿求解 整个模块的任务是获取固定在高空2m左右的哨岗相机相对于地图中心坐标点所在坐
-
 秋招算法岗面经复盘-腾讯-广告算法
秋招算法岗面经复盘-腾讯-广告算法腾讯-base未知-广告算法 做题: 1. 求两个列表的交集,时间复杂度尽可能低,不可以用map和set 2. 求一个数在一个列表中的最大数 ner模型除了gp还有哪些,gp相比普通ner的优点 ner中如何去解决预测错误的问题,比如宝马三系标签是BIBI中的三系 什么是线性可分,逻辑斯蒂是线性还是非线性的 常用的ctr模型 deepfm的fm结构是啥 如果输入特征只有一维,做二分类任务,这个特征
-
斯坦福核心NLP NER输出
我曾使用grep和awk从斯坦福CRF-NER的“内联XML”中提取英语文本中的命名实体,我希望在其他人类语言中使用相同的更大工作流。 我一直在尝试法语(西班牙语似乎给我带来了一个Java错误,这是另一个故事),并使用我得到标准文本输出,每个句子都有各种类型的注释,包括正确组合在一起的多单词实体,如下所示: 我知道解析它是可能的,但当我真的只是想要整个文件中的实体列表时,这似乎浪费了很多处理。 我
-
NLP:从文本中检索词汇
我有一些不同语言的文本,可能有一些拼写错误或其他错误,我想检索他们自己的词汇。一般来说,我对自然语言处理没有经验,所以可能我使用了一些不正确的单词。 关于词汇,我指的是一种语言的单词集合,其中每个单词都是唯一的,不考虑性别、数字或时态的屈折变化(例如,think、thinks和thought are都是考虑-思考)。 这是一个主要问题,所以让我们把它简化为一种语言的词汇检索,例如英语,并且没有错误
-
基于NLP/ML的摘要分类
null
-
斯坦福核心nlp java输出
我是Java和Stanford NLP工具包的新手,并试图在一个项目中使用它们。具体地说,我尝试使用Stanford Corenlp toolkit来注释文本(使用Netbeans而不是命令行),并尝试使用http://nlp.Stanford.edu/software/Corenlp.shtml#Usage上提供的代码(使用Stanford Corenlp API)。问题是:有人能告诉我如何在文
-
Stanford NLP令牌Regex--不识别NER
我从几个网络搜索中拼凑出以下内容。我可以让简单的Java regex与之匹配,但在使用NER时,我没有尝试过任何匹配(所有这些都是从web搜索中复制来的示例,并稍微调整了一下)。 为了清晰起见,请编辑:(下面代码中的中的成功/失败为true/false。) 我不知道我是否需要明确地提到某个模型或注释或其他东西,或者我是否遗漏了其他东西,或者我是否只是以完全错误的方式处理它。
-
将深度学习应用到 NLP
词向量 自然语言需要数学化才能够被计算机认识和计算。数学化的方法有很多,最简单的方法是为每个词分配一个编号,这种方法已经有多种应用,但是依然存在一个缺点:不能表示词与词的关系。 词向量是这样的一种向量[0.1, -3.31, 83.37, 93.0, -18.37, ……],每一个词对应一个向量,词义相近的词,他们的词向量距离也会越近(欧氏距离、夹角余弦) 词向量有一个优点,就是维度一般较低,一般